【DGL教程】第5章 训练GNN
官方文档:https://docs.dgl.ai/en/latest/guide/training.html
官方示例:https://github.com/dmlc/dgl/tree/master/examples/pytorch
官方文档给出了使用消息传递和NN模块训练用于不同类型任务的GNN的例子,包括顶点分类/回归、边分类/回归、连接预测和图分类
1.顶点分类/回归
https://docs.dgl.ai/en/latest/guide/training-node.html
顶点分类任务是学习一个将顶点映射到一组预定义类别的分类器f: V→C,顶点回归任务是学习一个将顶点映射到一个实数的回归器f: V→R 为了分类顶点,GNN通过消息传递来利用顶点的特征,以及邻居和边的特征
1.1 同构图
在该示例中,选择DGL内置的图卷积模块dgl.nn.pytorch.SAGEConv(来自GraphSAGE模型)来执行一次信息传递,叠加多个图卷积模块可执行多次信息传递,从而实现多层GNN
该示例实现了一个两层的GNN,叫做SAGE
1
2
3
4
5
6
7
8
9
10
11
12
class SAGE(nn.Module):
def __init__(self, in_feats, hid_feats, out_feats):
super().__init__()
self.conv1 = SAGEConv(in_feats, hid_feats, 'mean')
self.conv2 = SAGEConv(hid_feats, out_feats, 'mean')
def forward(self, graph, inputs):
# inputs are features of nodes
h = F.relu(self.conv1(graph, inputs))
h = self.conv2(graph, h)
return h
由于该模型学习了隐藏节点表示,因此不仅可以用于顶点分类任务,还可以用于边分类、连接预测、图分类等其他下游任务
- 顶点分类:输出维数等于类别数→softmax→类别概率→交叉熵损失
- 边分类:起点、终点特征拼接→全连接层,输出维数等于类别数→边特征→softmax→类别概率→交叉熵损失
- 边回归:起点、终点特征点积→边特征(标量)→MSE损失
该示例使用的数据集为DGL内置的数据集dgl.data.CiteseerGraphDataset
完整代码:
- https://github.com/dmlc/dgl/blob/master/examples/pytorch/graphsage/train_full.py
- https://github.com/ZZy979/pytorch-tutorial/blob/master/gnn/dgl/node_clf.py
1.2 异构图
对于异构图,使用dgl.nn.pytorch.HeteroGraphConv模块,在所有类型的边上进行消息传递,之后对每种边类型组合不同的图卷积模块,该模块的输入和输出都是一个键为顶点类型、值为顶点特征张量的字典
该示例实现的模型叫做RGCN
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
class RGCN(nn.Module):
def __init__(self, in_feats, hid_feats, out_feats, rel_names):
super().__init__()
self.conv1 = HeteroGraphConv({
rel: GraphConv(in_feats, hid_feats) for rel in rel_names
}, aggregate='sum')
self.conv2 = HeteroGraphConv({
rel: GraphConv(hid_feats, out_feats) for rel in rel_names
}, aggregate='sum')
def forward(self, graph, inputs):
# inputs are features of nodes
h = self.conv1(graph, inputs)
h = {k: F.relu(v) for k, v in h.items()}
h = self.conv2(graph, h)
return h
完整代码:
- https://github.com/dmlc/dgl/blob/master/examples/pytorch/rgcn-hetero/entity_classify.py
- https://github.com/ZZy979/pytorch-tutorial/blob/master/gnn/dgl/node_clf_hetero.py
2.边分类/回归
https://docs.dgl.ai/en/latest/guide/training-edge.html
2.1 同构图
顶点分类任务的GNN已经学习到顶点的向量表示,在此基础上利用边的起点和终点的向量即可得到边的向量表示(例如相加、点积等),这一过程就是消息传递模型中使用消息函数生成消息的步骤,使用DGLGraph.apply_edges()即可
具体地,增加一个Predictor模块,其forward方法调用graph参数的apply_edges()方法,返回生成的消息
内积实现:
1
2
3
4
5
6
7
8
class DotProductPredictor(nn.Module):
def forward(self, graph, h):
# h contains the node representations computed from the GNN defined in node_clf.py
with graph.local_scope():
graph.ndata['h'] = h
graph.apply_edges(fn.u_dot_v('h', 'h', 'score'))
return graph.edata['score']
拼接+内积实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
class MLPPredictor(nn.Module):
def __init__(self, in_features, out_classes):
super().__init__()
self.W = nn.Linear(in_features * 2, out_classes)
def apply_edges(self, edges):
score = self.W(torch.cat([edges.src['h'], edges.dst['h']], dim=1))
return {'score': score}
def forward(self, graph, h):
# h contains the node representations computed from the GNN defined in node_clf.py
with graph.local_scope():
graph.ndata['h'] = h
graph.apply_edges(self.apply_edges)
return graph.edata['score']
整体模型将SAGE和Predictor连接在一起即可
1
2
3
4
5
6
7
8
9
10
class Model(nn.Module):
def __init__(self, in_features, hidden_features, out_features):
super().__init__()
self.sage = SAGE(in_features, hidden_features, out_features)
self.pred = DotProductPredictor()
def forward(self, g, x):
h = self.sage(g, x)
return self.pred(g, h)
完整代码:https://github.com/ZZy979/pytorch-tutorial/blob/master/gnn/dgl/edge_clf.py
2.2 异构图
对于异构图,只需在调用apply_edges()时指定etype参数即可 具体地,对Predictor模块稍加修改,在调用apply_edges()时增加etype参数,叫做HeteroPredictor模块
内积实现:
1
2
3
4
5
6
7
8
class HeteroDotProductPredictor(nn.Module):
def forward(self, graph, h, etype):
# h contains the node representations for each edge type computed from node_clf_hetero.py
with graph.local_scope():
graph.ndata['h'] = h # assigns 'h' of all node types in one shot
graph.apply_edges(fn.u_dot_v('h', 'h', 'score'), etype=etype)
return graph.edges[etype].data['score']
拼接+内积实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
class HeteroMLPPredictor(nn.Module):
def __init__(self, in_features, out_classes):
super().__init__()
self.W = nn.Linear(in_features * 2, out_classes)
def apply_edges(self, edges):
score = self.W(torch.cat([edges.src['h'], edges.dst['h']], dim=1))
return {'score': score}
def forward(self, graph, h, etype):
# h contains the node representations for each edge type computed from node_clf_hetero.py
with graph.local_scope():
graph.ndata['h'] = h # assigns 'h' of all node types in one shot
graph.apply_edges(self.apply_edges, etype=etype)
return graph.edges[etype].data['score']
整体模型将RGCN和HeteroPredictor连接在一起即可
1
2
3
4
5
6
7
8
9
10
class Model(nn.Module):
def __init__(self, in_features, hidden_features, out_features, rel_names):
super().__init__()
self.sage = RGCN(in_features, hidden_features, out_features, rel_names)
self.pred = HeteroDotProductPredictor()
def forward(self, g, x, etype):
h = self.sage(g, x)
return self.pred(g, h, etype)
完整代码:https://github.com/ZZy979/pytorch-tutorial/blob/master/gnn/dgl/edge_clf_hetero.py
2.3 预测边类型
对于在异构图上预测边类型的任务(例如给定user顶点和item顶点之间的一条边,预测其类型为click还是dislike)
该问题是推荐系统中评价预测的简化版本,仍然可以使用异构图卷积网络学习到的顶点向量表示,要预测边的类型,可以直接使用2.1节中的MLPPredictor模块
在该示例中,需要的是一个“合并”了user顶点和item顶点之间的click和dislike两种边类型的图,使用以下语法即可创建:
1
dec_graph = g['user', :, 'item']
dec_graph的user和item顶点与原图完全一样,但是只有user-(click+dislike)->item一种边,由原图中的user-(click)->item和user-(dislike)->item两种边合并得到(具体见DGLHeteroGraph.__getitem__)
以上语句返回的dec_graph具有一个名为dgl.ETYPE的整型边特征,表示边在原图中的类型(实际上是g.etypes.index(etype)),可以用作边类型预测任务中的标签
1
2
>>> dec_graph.edata[dgl.ETYPE]
tensor([2, 2, 2, ..., 3, 3, 3])
dec_graph只合并了两种边,即dec_graph.edata[dgl.ETYPE]中只包含两种数字,因此预测模块的输出应该是2维,而文档中HeteroMLPPredictor模块的输出类别数是len(rel_names),即6,应该是错误的- 另外,
dec_graph.edata[dgl.ETYPE]中的两个数字是2和3,在计算交叉熵损失时会报错,应使用edge_label -= edge_label.min().item()将其改为0和1
整体模型将RGCN和MLPPredictor模块连接在一起即可
1
2
3
4
5
6
7
8
9
10
class Model(nn.Module):
def __init__(self, in_features, hidden_features, out_features, rel_names):
super().__init__()
self.sage = RGCN(in_features, hidden_features, out_features, rel_names)
self.pred = MLPPredictor()
def forward(self, g, x, etype):
h = self.sage(g, x)
return self.pred(g, h, etype)
完整代码:
- https://github.com/dmlc/dgl/tree/master/examples/pytorch/gcmc
- https://github.com/ZZy979/pytorch-tutorial/blob/master/gnn/dgl/edge_type_hetero.py
3.连接预测
https://docs.dgl.ai/en/latest/guide/training-link.html
连接预测任务的目标是预测给定的两个顶点之间是否存在一条边
基于GNN的连接预测模型本质上就是顶点表示向量的函数: $y_{u,v}=\varphi(h_u,h_v)$ ,其中顶点表示向量(即特征)是由多层GNN计算得到,将 $y_{u,v}$ 称为顶点u和v之间的得分
训练连接预测模型的方法是将一条边连接的两个顶点之间的得分与任意一对顶点之间的得分比较。例如,给定一条边连接的两个顶点u和v,目标是使得 $y_{u,v} > y_{u,v’}$ ,其中v’是从任意噪声分布 $P_n(v)$ 中采样得到的顶点。这种方法叫做负采样,可用的损失函数包括交叉熵损失、BPR损失、Margin损失等。
3.1 同构图
计算顶点之间得分的神经网络实际上和用于边回归任务的神经网络是一样的,都是在SAGE模块后增加一个Predictor模块,利用SAGE模块学习到的顶点表示向量计算消息,作为顶点之间的得分
区别在于需要另一个图来表达负样本,该图的边对应所有的负样本顶点对
1
2
3
4
5
6
7
8
9
10
class Model(nn.Module):
def __init__(self, in_features, hidden_features, out_features):
super().__init__()
self.sage = SAGE(in_features, hidden_features, out_features)
self.pred = DotProductPredictor()
def forward(self, g, neg_g, x):
h = self.sage(g, x)
return self.pred(g, h), self.pred(neg_g, h)
负样本图由与原图中的边起点相同、终点不同的边组成
1
2
3
4
5
def construct_negative_graph(graph, k):
src, dst = graph.edges()
neg_src = src.repeat_interleave(k)
neg_dst = torch.randint(0, graph.number_of_nodes(), (len(src) * k,))
return dgl.graph((neg_src, neg_dst), num_nodes=graph.number_of_nodes())
训练完成后,单独使用SAGE模块即可得到顶点嵌入(向量表示)
1
node_embeddings = model.sage(graph, node_features)
该嵌入有多种用途,例如训练下游分类器、做最近邻搜索、通过最大化内积进行实体推荐等
完整代码:https://github.com/ZZy979/pytorch-tutorial/blob/master/gnn/dgl/link_pred.py
3.2 异构图
异构图上的连接预测与同构图基本相同,可以重用HeteroPredictor模块在一种类型的边上计算得分,从而进行连接预测
构造负样本图也是针对要进行连接预测的边类型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
class Model(nn.Module):
def __init__(self, in_features, hidden_features, out_features, rel_names):
super().__init__()
self.sage = RGCN(in_features, hidden_features, out_features, rel_names)
self.pred = HeteroDotProductPredictor()
def forward(self, g, neg_g, x, etype):
h = self.sage(g, x)
return self.pred(g, h, etype), self.pred(neg_g, h, etype)
def construct_negative_graph(graph, k, etype):
utype, _, vtype = etype
src, dst = graph.edges(etype=etype)
neg_src = src.repeat_interleave(k)
neg_dst = torch.randint(0, graph.number_of_nodes(vtype), (len(src) * k,))
return dgl.heterograph(
{etype: (neg_src, neg_dst)},
num_nodes_dict={ntype: graph.number_of_nodes(ntype) for ntype in graph.ntypes}
)
完整代码:https://github.com/ZZy979/pytorch-tutorial/blob/master/gnn/dgl/link_pred_hetero.py
4.图分类
https://docs.dgl.ai/en/latest/guide/training-graph.html
图分类任务与前几种任务的区别在于图分类任务是对整个图做分类,输入数据是一组图而不是一个图,因此在图的层次上学习表示向量。
图分类的过程如下图所示:
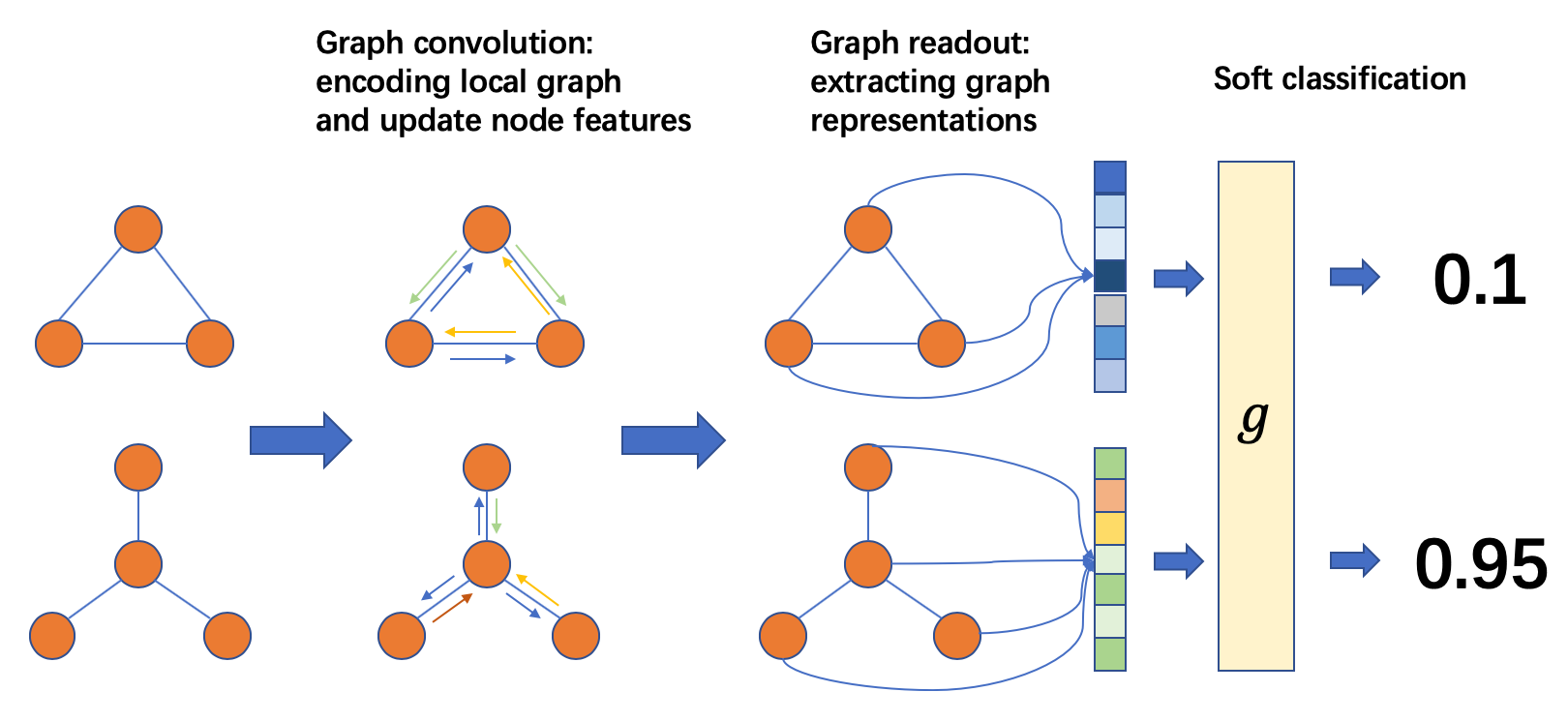
从左到右,通常做法是:
- 将输入图组合成批(batch)
- 在batch上进行消息传递,更新顶点/边特征
- 将顶点/边特征聚集为图层次的表示
- 进行分类任务
4.1 图的batch
在DGL中,可以使用dgl.batch()将多个图构造为一个batch图(对顶点重新编号),该batch图可以被当做一个大图使用(不同的图之间是不连通的)
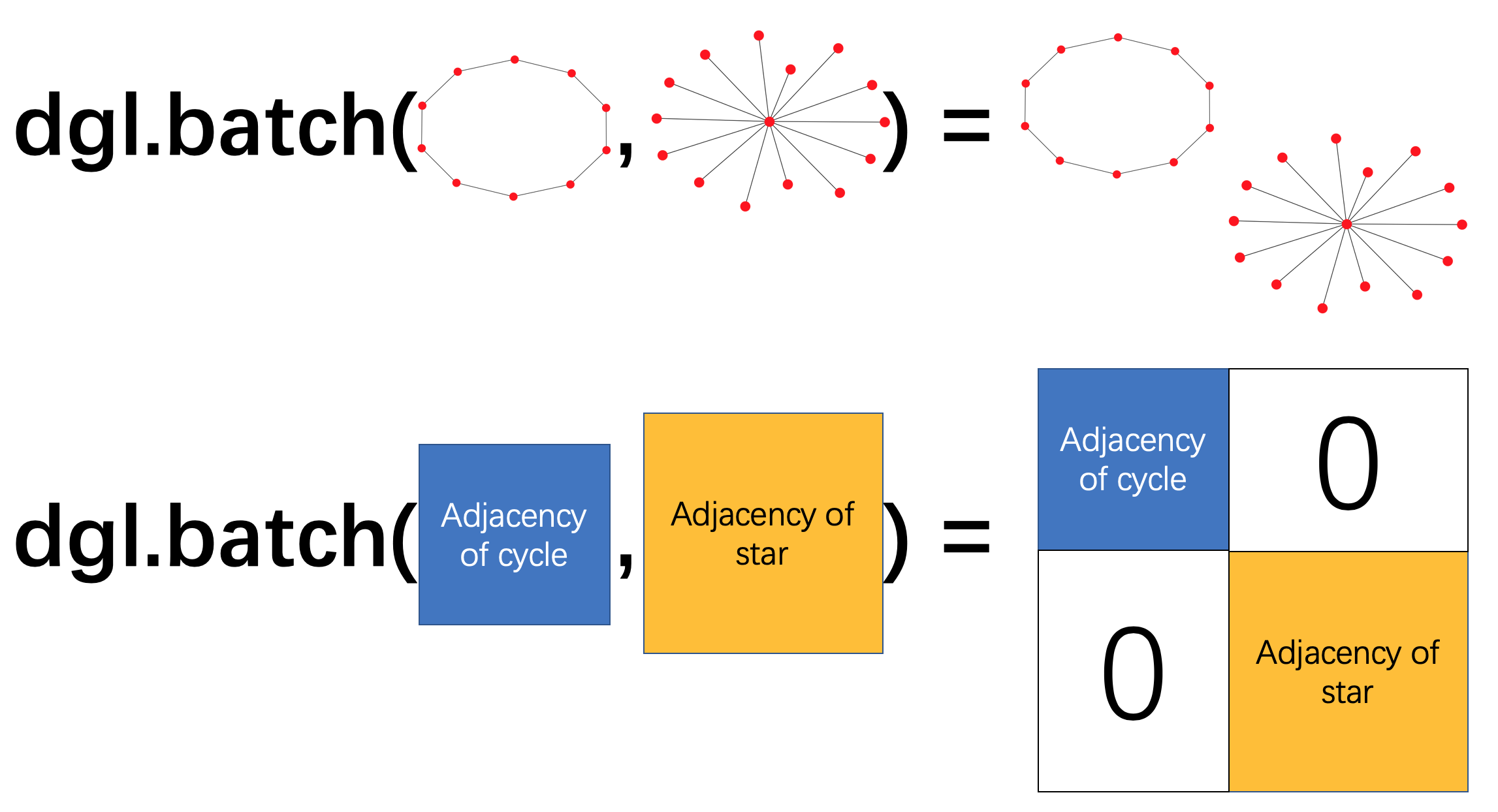
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
>>> import dgl
>>> import torch
>>> g1 = dgl.graph((torch.tensor([0, 1, 2]), torch.tensor([1, 2, 3])))
>>> g2 = dgl.graph((torch.tensor([0, 0, 0, 1]), torch.tensor([0, 1, 2, 0])))
>>> bg = dgl.batch([g1, g2])
>>> bg
Graph(num_nodes=7, num_edges=7,
ndata_schemes={}
edata_schemes={})
>>> bg.batch_size
2
>>> bg.batch_num_nodes()
tensor([4, 3])
>>> bg.batch_num_edges()
tensor([3, 4])
>>> bg.edges()
(tensor([0, 1, 2, 4, 4, 4, 5]), tensor([1, 2, 3, 4, 5, 6, 4]))
>>> dgl.unbatch(bg)
[Graph(num_nodes=4, num_edges=3,
ndata_schemes={}
edata_schemes={}), Graph(num_nodes=3, num_edges=4,
ndata_schemes={}
edata_schemes={})]
4.2 Readout
Readout操作是将每个图的顶点或边特征聚集为一个图特征(例如求和、求平均、取最大值/最小值等),从而便于进行图分类 例如,如果聚集方式是求平均,则
\[h_g=\frac{1}{|V|}\sum_{v \in V}h_v\]在DGL中,对应的函数是dgl.readout_nodes()和dgl.readout_edges(),另外还有sum_nodes, sum_edges, mean_nodes, mean_edges, max_nodes, max_edges几个“语法糖”函数
1
2
3
4
5
6
7
8
9
>>> g = dgl.graph(([0, 1], [1, 2]))
>>> g.ndata['h'] = torch.tensor([0., 1., 2.])
>>> g.edata['h'] = torch.tensor([10., 20.])
>>> dgl.readout_nodes(g, 'h')
tensor([3.])
>>> dgl.readout_nodes(g, 'h', op='mean')
tensor([1.])
>>> dgl.readout_edges(g, 'h')
tensor([30.])
4.3 在batch图上的计算
不同的图在合并后的batch图中是完全分离的,即没有连接两个图的边,因此消息传递的结果不变
在batch图上readout函数将对每个图分别计算,假设batch大小为B,要聚集的特征维数为D,则readout结果的大小为B×D
1
2
3
4
5
6
7
8
9
>>> g1 = dgl.graph(([0, 1], [1, 0]))
>>> g1.ndata['h'] = torch.tensor([1., 2.])
>>> g2 = dgl.graph(([0, 1], [1, 2]))
>>> g2.ndata['h'] = torch.tensor([1., 2., 3.])
>>> bg = dgl.batch([g1, g2])
>>> dgl.readout_nodes(bg, 'h') # [1 + 2, 1 + 2 + 3]
tensor([3., 6.])
>>> dgl.readout_nodes(bg, 'h', op='max') # [max{1, 2}, max{1, 2, 3}]
tensor([2., 3.])
batch图的顶点/边特征由所有图的对应特征张量拼接得到(因为顶点是按顺序重新编号的,g2的顶点0 ~ 2分别对应bg的顶点2 ~ 4)
1
2
>>> bg.ndata['h']
tensor([1., 2., 1., 2., 3.])
完整代码:
- https://github.com/dmlc/dgl/tree/master/examples/pytorch/gin
- https://github.com/ZZy979/pytorch-tutorial/blob/master/gnn/dgl/graph_clf.py
4.4 异构图
在异构图上进行图分类的不同之处在于需要异构图卷积模块,另外在readout函数中还需要对不同类型的顶点做聚集
完整代码:https://github.com/ZZy979/pytorch-tutorial/blob/master/gnn/dgl/graph_clf_hetero.py