Flink入门教程
1.简介
Apache Flink是一个开源的分布式流处理框架,旨在提供高效、可扩展、容错的流式数据处理技术,支持实时流处理和批处理,并提供了Java、Scala、Python等语言的API。
2.快速入门
2.1 下载和安装
https://nightlies.apache.org/flink/flink-docs-stable/docs/try-flink/local_installation/
2.1.1 下载Flink
Flink可以在所有类UNIX环境上运行。首先需要安装Java 8+。之后从下载页面下载Flink二进制包(例如flink-1.17.2-bin-scala_2.12.tgz)并解压。
2.1.2 启动和停止本地集群
进入解压目录,运行以下脚本启动本地集群:
1
./bin/start-cluster.sh
Flink将在后台进程中运行。
使用以下脚本停止集群:
1
./bin/stop-cluster.sh
2.1.3 提交Flink作业
Flink提供的命令行工具bin/flink可以将打包为JAR的程序提交到Flink集群执行。examples目录包含一些示例程序(源代码见flink-examples)。
执行以下命令将单词计数示例程序提交到本地集群:
1
./bin/flink run examples/streaming/WordCount.jar
可以查看日志验证输出:
1
2
3
4
5
6
7
8
9
10
11
$ tail log/flink-*-taskexecutor-*.out
(nymph,1)
(in,3)
(thy,1)
(orisons,1)
(be,4)
(all,2)
(my,1)
(sins,1)
(remember,1)
(d,4)
也可以在浏览器打开Flink的Web UI (http://localhost:8081/)查看集群和作业的状态。
2.2 使用IDE
2.2.1 创建工程
可以基于Flink提供的Archetype创建Flink工程。
如果使用IDEA,在新建工程时选择Maven Archetype。Archetype填写org.apache.flink:flink-quickstart-java,如下图所示。
也可以使用Maven命令:
1
2
3
4
$ mvn archetype:generate \
-DarchetypeGroupId=org.apache.flink \
-DarchetypeArtifactId=flink-quickstart-java \
-DarchetypeVersion=1.17.2
2.2.2 添加依赖
https://nightlies.apache.org/flink/flink-docs-stable/docs/dev/configuration/overview/
Flink提供了两类API:Datastream API以及Table API & SQL。可以根据需要添加对应的依赖:
| API类型 | 依赖 |
|---|---|
| DataStream | flink-streaming-java |
| DataStream with Scala | flink-streaming-scala_2.12 |
| Table | flink-table-api-java |
| Table with Scala | flink-table-api-scala_2.12 |
| Table + DataStream | flink-table-api-java-bridge |
| Table + DataStream with Scala | flink-table-api-scala-bridge_2.12 |
其中2.12是Scala版本。
注意:Flink Scala API已弃用,并在2.0版本中移除。使用Scala构建的应用程序应该迁移到Java API。详见FLIP-265 Deprecate and remove Scala API support。
例如,如果要使用DataStream API则添加以下依赖。
1
2
3
4
5
6
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>1.17.2</version>
<scope>provided</scope>
</dependency>
2.2.3 运行
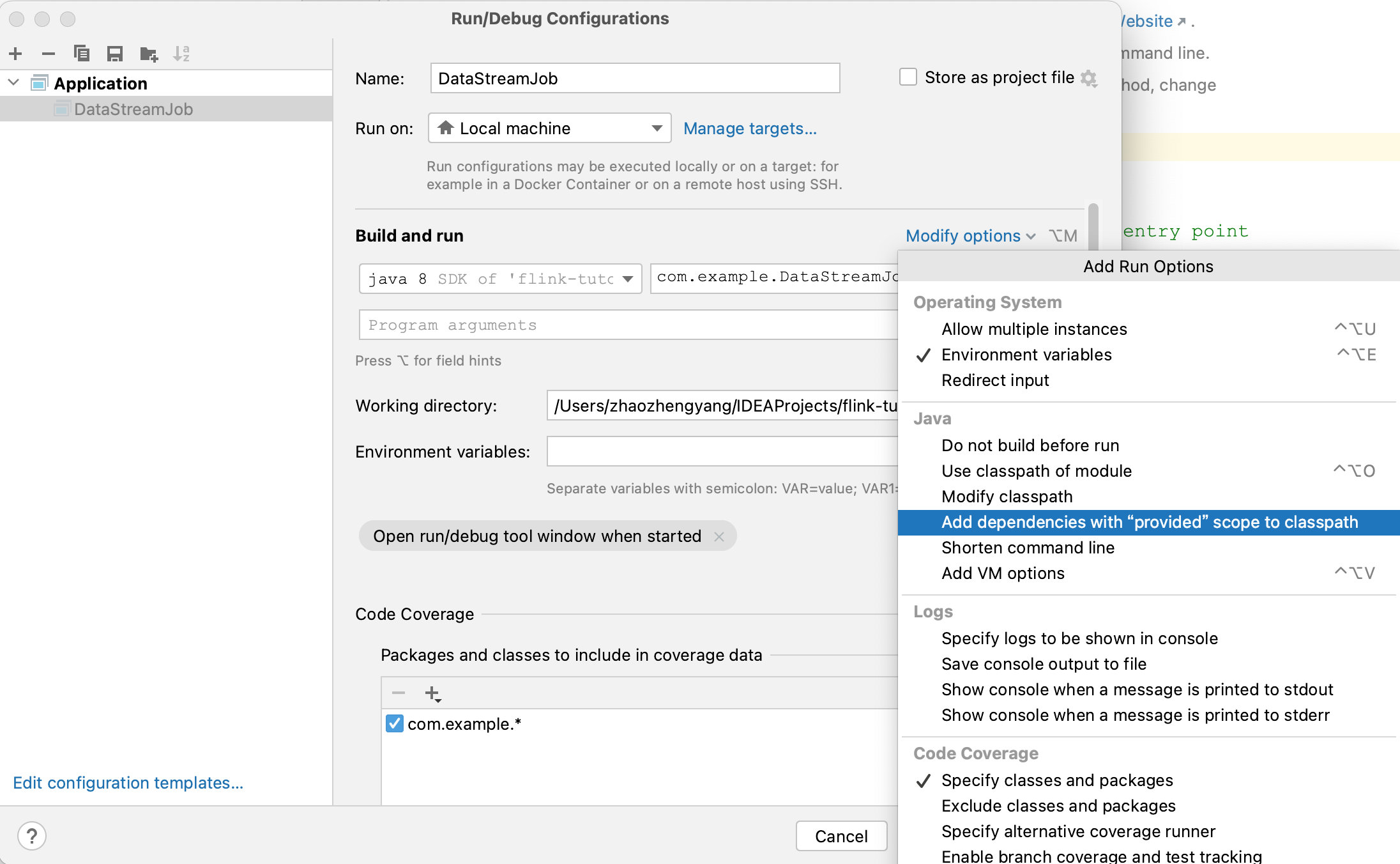
直接用IDEA运行创建的Flink工程会报错 “java.lang.ClassNotFoundException: org.apache.flink.streaming.api.environment.StreamExecutionEnvironment” ,因为Flink API是provided依赖。需要修改运行配置,将provided依赖添加到类路径,如下图所示。
2.3 示例:单词计数-批处理
下面的程序读取指定的文本文件,计算每个单词的出现次数,并输出到指定的文件或打印到标准输出。
程序输出结果:
1
2
3
4
5
6
7
8
9
10
11
12
(arrows,1)
(be,4)
(coil,1)
(dread,1)
(er,1)
(know,1)
(long,1)
(make,2)
(my,1)
(nobler,1)
(of,15)
...
注:从Flink 1.12起DataSet API已经被弃用,并将在未来版本中移除,详见FLIP-131。推荐使用Table API & SQL来进行批处理。另外,也可以使用DataStream API的BATCH 执行模式。
2.4 示例:单词计数-流处理
下面的程序从TCP套接字读取字符串,计算每5秒窗口内的单词计数,并打印到标准输出。
可以使用nc命令启动一个简单的文本服务器(TCP连接):
1
2
3
4
$ nc -l 12345
to be or not to be
not to be
^C
其中第一行和第二行输入间隔5秒。程序输出如下:
1
2
3
4
5
6
7
(not,1)
(to,2)
(be,2)
(or,1)
(to,1)
(not,1)
(be,1)
注意:第一行和第二行的单词属于不同的窗口,因此单词 “be” 是分开计数的。
3.Flink基础
官方文档:https://nightlies.apache.org/flink/flink-docs-stable/docs/learn-flink/overview/
3.1 流处理
很多数据都是流(stream)式的,分为有界流(bounded stream)和无界流(unbounded stream)。
- 批处理(batch processing):处理有界流,可以将整个数据集加载到内存中。
- 流处理(stream processing):处理无界流,输入可能永远不终止,必须在数据到达时持续处理。
在Flink中,应用由数据流(streaming dataflows)组成,数据流由用户定义的算子(operator)构成。数据流可抽象为有向图,以一个或多个源(source)算子开始、一个或多个汇(sink)算子结束。

3.1.1 并行数据流
Flink程序本质上就是并行和分布式的。在执行中,流有一个或多个分区(partition),每个算子有一个或多个子任务(subtask)。算子子任务是相互独立的,在不同线程中执行,可能位于不同机器上。
算子子任务的数量称为算子的并行度(parallelism)。同一个程序的不同算子可以有不同的并行度。

流可以在两个算子之间以一对一或重新分配的方式传输数据:
- 一对一(one-to-one)流(例如上图中的source和map算子之间)保持数据的分区和顺序,因此子任务source[1]和map[1]将以相同的顺序看到相同的数据。
- 重新分配(redistributing)流(例如上图中的map和keyBy/window算子之间,以及keyBy/window和sink算子之间)会改变流的分区,仅在每对发送和接收子任务(例如map[1]和keyBy/window[2])之间保持数据顺序。
3.2 DataStream API简介
https://nightlies.apache.org/flink/flink-docs-stable/docs/learn-flink/datastream_api/
3.2.1 支持的类型
Flink的DataStream API支持任何可序列化的类型作为流元素,包括:
对于Java,Flink定义了元组类型Tuple0~Tuple25。例如:
1
Tuple2<String, Integer> person = Tuple2.of("Fred", 35);
POJO类型需要满足以下条件:
- 类是公有的、独立的(没有非静态内部类)
- 具有公有无参数构造器
- 所有非静态、非
transient字段要么是公有且非final的,要么具有公有getter和setter方法且遵循Java bean的命名规则
例如:
1
2
3
4
5
6
7
8
9
10
11
public class Person {
public String name;
public Integer age;
public Person() {}
public Person(String name, Integer age) {
this.name = name;
this.age = age;
}
}
3.2.2 完整示例
下面的示例输入人员信息的(有界)流,过滤出成年人,并打印出来。
该示例中的数据流结构如下:
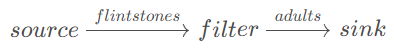
其中source算子是fromElements(),表示从指定的元素创建一个流,得到流flintstones;之后经过filter()算子过滤出成年人,得到流adults;最后使用sink算子print()打印元素。
程序运行结果:
1
2
1> Fred: age 35
2> Wilma: age 35
其中 “1>” 和 “2>” 表示子任务(即线程)id。
3.2.3 执行环境
每个Flink应用需要一个执行环境,流处理应用需要StreamExecutionEnvironment,即上面示例中的env。
DataStream API调用构成一个数据流附加到执行环境,当调用env.execute()时,数据流将被打包并发送到作业管理器(JobManager),JobManager将作业并行化切片并分发到任务管理器(TaskManager)执行。作业的每个并行切片将在一个任务槽(task slot)中执行。

注意:调用env.execute()时应用才真正开始运行。当作业启动时,JobManager会将所有算子的函数对象(包括所有非transient字段和引用的外部对象)序列化,打包成任务并分发到各个TaskManager。如果对象包含不可序列化的字段,作业就会启动失败。例如:
1
2
3
4
public class MyMapper implements MapFunction<String, String> {
private DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd");
...
}
由于DateTimeFormatter类不可序列化,这会导致报错:
1
org.apache.flink.api.common.InvalidProgramException: [Ljava.time.format.DateTimeFormatterBuilder$DateTimePrinterParser;@d5b810e is not serializable. The object probably contains or references non serializable fields.
另外,可序列化但非常大的对象会增加网络传输开销。
解决这个问题的最佳实践是transient+延迟初始化:将字段用关键字transient标记使其跳过序列化,实现rich变体的函数接口(见3.3.3.1节)并在open()方法中初始化该字段。
1
2
3
4
5
6
7
8
9
10
public class MyMapper extends RichMapFunction<String, String> {
private transient DateTimeFormatter formatter;
@Override
public void open(Configuration parameters) {
formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd");
}
...
}
这样,当JobManager序列化算子时会跳过formatter字段。在TaskManager上反序列化后formatter字段仍然为null,之后open()方法被调用,初始化formatter字段。(注:虽然不加transient也能工作,因为在序列化时formatter为null,但用transient可以明确表达“该字段不需要序列化”的意图,并且可以减少一点序列化开销)
在Scala中可以使用lazy val实现延迟初始化,同时又绕过了序列化问题,非常适合在Flink算子中使用。
1
2
3
4
class MyMapper extends MapFunction[String, String] {
@transient private lazy val formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd")
...
}
3.2.4 基本算子
source算子(StreamExecutionEnvironment类的方法)
fromElements():从指定元素创建流fromCollection():从指定集合创建流fromSequence():从整数区间创建流readTextFile():读取文本文件,每行作为一个元素socketTextStream():从套接字读取数据,使用指定的分隔符addSource():使用自定义SourceFunction
转换算子(DataStream及其子类的方法)
map():元素一对一映射flatMap():元素一对n映射filter():按指定的条件过滤元素keyBy():按指定的key分组reduce():对已分组的流进行聚合union():合并多个流
sink算子(DataStream及其子类的方法)
print():将每个元素打印到标准输出流writeAsText():写入文本文件,每个元素占一行writeAsCsv():写入CSV文件writeToSocket():写入套接字addSink():使用自定义SinkFunction- 输出到文件:FileSink
完整列表参考:
算子和流类型的转换关系如下图所示:
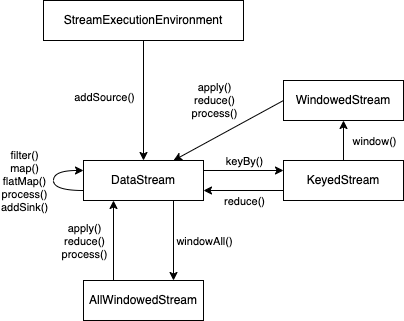
3.2.5 练习
3.3 数据管道和ETL
https://nightlies.apache.org/flink/flink-docs-stable/docs/learn-flink/etl/
Flink的一种非常常见的应用场景是实现ETL (extract-transform-load)管道,即从一个或多个数据源获取数据,进行一些转换和/或信息补充,并将结果保存起来。本节将介绍如何使用Flink的DataStream API来实现这类应用。
3.3.1 无状态转换
算子map()和flatMap()是用于实现无状态转换的基本操作。
3.3.1.1 map()
map()算子接受一个MapFunction接口参数,对元素进行一对一转换,即每个元素对应恰好一个结果。由于MapFunction是函数式接口,因此可以使用Lambda表达式。
例如,下面的代码将每个数字变为2倍:
1
DataStream<Long> doubled = env.fromSequence(1, 5).map(x -> 2 * x);
结果为[2, 4, 6, 8, 10]。
下面的代码将每个单词映射到其长度:
1
2
3
DataStream<Integer> wordLengths = env
.fromElements("to be or not to be that is the question".split(" "))
.map(String::length);
结果为[2, 2, 2, 3, 2, 2, 4, 2, 3, 8]。
3.3.1.2 flatMap()
flatMap()算子接受一个FlatMapFunction接口参数,对元素进行一对n转换,即每个元素映射到零个或多个结果。
例如,下面的代码将文本行分割为单词:
1
2
3
DataStream<String> words = env
.fromElements("to be or not to be", "that is the question")
.flatMap(new LineSplitter());
1
2
3
4
5
6
7
8
class LineSplitter implements FlatMapFunction<String, String> {
@Override
public void flatMap(String line, Collector<String> out) {
for (String word : line.split(" ")) {
out.collect(word);
}
}
}
结果为["to", "be", "or", "not", "to", "be", "that", "is", "the", "question"]。
下面的代码只保留奇数:
1
DataStream<Long> oddNumbers = env.fromSequence(1, 5).flatMap(new OddNumber());
1
2
3
4
5
6
7
8
class OddNumber implements FlatMapFunction<Long, Long> {
@Override
public void flatMap(Long x, Collector<Long> out) {
if (x % 2 == 1) {
out.collect(x);
}
}
}
结果为[1, 3, 5](也可以用filter()实现)。
3.3.2 分组
3.3.2.1 keyBy()
将一个流按照某个字段分组通常是十分有用的,类似于SQL的GROUP BY语句。在Flink中可以用keyBy()算子实现。
keyBy()算子接受一个KeySelector接口参数(元组也可以使用字段索引,POJO也可以使用字段名),返回KeyedStream。接口KeySelector的抽象方法从一个元素提取出用于分组的key。
例如,下面的代码将人员信息按年龄分组:
1
KeyedStream<Person, Integer> keyedByAge = people.keyBy(p -> p.age);
KeySelector提取的key不限于元素的字段,可以按任何方式计算得到key,只要key是确定的,并且实现了hashCode()和equals()方法即可。例如,随机数、数组和枚举不能作为key,但元组和POJO可以作为复合key。
keyBy()操作会将流重新分区,这个开销是很大的,因为涉及网络通信、序列化和反序列化,如3.1.1节图所示。
3.3.2.2 聚合
分组后的流可以对每个组进行聚合操作(注意:是“滚动”聚合,例如sum()计算的是前缀和而不是总和,因为无限流不存在“总和”)。
例如,下面的代码对单词计数:
1
2
3
4
5
DataStream<Tuple2<String, Integer>> wordCounts = env
.fromElements("to be or not to be".split(" "))
.map(w -> Tuple2.of(w, 1))
.returns(Types.TUPLE(Types.STRING, Types.INT));
wordCounts.keyBy(t -> t.f0).sum(1).print();
输出结果为每个单词目前遇到的次数(顺序可能变化):
1
2
3
4
5
6
6> (not,1)
8> (be,1)
8> (or,1)
9> (to,1)
8> (be,2)
9> (to,2)
注:由于类型擦除,Tuple2.of()无法提供关于其字段类型的信息。如果不写returns()会报错 “The generic type parameters of ‘Tuple2’ are missing”,见Java Lambda Expressions。解决方法是实现MapFunction接口、使用匿名子类或者returns()等能够显式指定类型的方式。
下面的代码统计每个用户目前停留时间最长的页面和对应的停留时间:
1
2
3
4
5
6
public static class PageView {
public int userId;
public int pageId;
public int duration;
// ...
}
1
2
3
4
5
6
7
8
DataStream<PageView> pageViews = env.fromElements(
new PageView(1, 2, 5),
new PageView(2, 1, 12),
new PageView(1, 3, 8),
new PageView(3, 2, 15),
new PageView(2, 3, 2));
DataStream<PageView> longestStay = pageViews.keyBy(pv -> pv.userId).maxBy("duration");
longestStay.print();
输出结果为:
1
2
3
4
5
12> PageView{userId=2, pageId=1, duration=12}
11> PageView{userId=3, pageId=2, duration=15}
9> PageView{userId=1, pageId=2, duration=5}
12> PageView{userId=2, pageId=1, duration=12}
9> PageView{userId=1, pageId=3, duration=8}
注:还有一个max()操作,与maxBy()的区别为:前者仅将记录的指定字段替换为最大值,其他字段保持不变;后者会用最大值对应的完整记录替换当前记录。如果将上面示例中的maxBy()替换为max(),则用户1输出的第二条记录为PageView{userId=1, pageId=2, duration=8}(pageId仍是第一条记录的,与duration不对应)。
为了记录每个分组“当前遇到的最大值”或者“当前部分和”,Flink内部使用了状态(见3.3.3节)。当应用涉及状态时,就应该考虑状态的大小。如果key的取值空间是无限的,则Flink的状态需要的存储空间也同样是无限的。
在流处理场景中,考虑有限窗口的聚合往往比整个流聚合更有意义(见3.4节)。
KeyedStream提供了更通用的聚合算子reduce(),以及求和、最大值和最小值的三个特例:
reduce():接受一个ReduceFunction接口参数,对每个相同key的分组内的元素进行“滚动”聚合操作,即a0, a1, a2, ... -> a0, f(a0, a1), f(f(a0, a1), a2), ...sum():计算前缀和max()/maxBy():计算当前遇到的最大值min()/minBy():计算当前遇到的最小值
3.3.3 有状态转换
本节将介绍如何使用Flink的API来管理状态(state)。
3.3.3.1 RichFunction
Flink的filter()、map()、flatMap()等算子使用的函数接口FilterFunction、MapFunction、FlatMapFunction都提供了一个 “rich” 变体(实现了RichFunction接口),增加了以下方法:
open():算子初始化时调用一次close():关闭时调用一次getRuntimeContext():返回用于创建和访问状态的上下文对象
3.3.3.2 示例
下面的例子对事件流去重,每个key只保留第一个事件。在该应用中,使用一个名为Deduplicator的RichFlatMapFunction来实现去重操作。
程序将输出
1
2
3
4
a@1
b@2
c@3
d@4
为了实现这一功能,Deduplicator需要记住出现过的key,这里使用状态来记录。
状态相当于算子的局部变量,可用于存储数据。对于KeyedStream,Flink将维护一个键值对存储,即每个key分别存储一份数据。最简单的一种状态是ValueState,即每个key分别存储单个对象,在这个例子中是Boolean类型。
Deduplicator有两个方法:open()使用ValueStateDescriptor通过名字 “keyHasBeenSeen” 获取状态;flatMap()方法获取状态的值,如果为null则表示当前key未出现过,因此输出当前事件并将状态更新为true。
注意:在读访问和更新状态keyHasBeenSeen时,key并未显式出现过。但Flink运行时调用flatMap()方法时,当前被处理的事件的key是已知的,Flink根据这个key来确定keyHasBeenSeen.value()访问键值对存储中的哪个条目。
部署在分布式集群时,将会有很多Deduplicator的实例,每个实例负责整个key空间中的一个子集。因此,ValueState<Boolean> keyHasBeenSeen;代表的不是一个布尔变量,而是一个分布式、分片的键值对存储。
3.3.3.3 清除状态
上面的例子有一个潜在的问题:当key空间无界时状态需要的存储空间也是无界的。因此清除不再需要的key的状态是很有必要的,可以通过调用状态对象的clear()方法来实现。
可以在ProcessFunction中通过定时器清除状态(见3.5节),也可以通过状态的生存时间 (time-to-live, TTL)配置自动清除时间。
3.3.4 连接流
有时可能需要通过引入阈值、规则或其他参数来动态调整转换功能。Flink支持这种需求的模式称为连接流(connected stream),其中一个算子有两个输入流,如下图所示。

连接流也可以用于实现流的关联(join)。
3.3.4.1 示例
在该示例中,使用控制流control来指定要从单词流streamOfWords中过滤掉的单词。使用connect()算子连接两个流,之后在flatMap()算子中使用RichCoFlatMapFunction来实现这一功能。
两个KeyedStream只有按相同的方式分组时才能连接,这确保来自两个流具有相同key的元素被发送到同一个实例。这使得按key连接(join)两个流成为可能。
ControlFunction在状态中存储一个布尔值,被两个流共享。
流control和streamOfWords中的单词将分别进入flatMap1()和flatMap2()。状态blocked用于记录当前key(单词)是否在control中出现过,这个状态是与key关联的,并且被两个流共享,这也是为什么两个流必须有相同的key空间。
理论上程序只会输出 “Apache” 和 “Flink” 两个单词,但实际上多次运行会发现 “DROP” 和 “IGNORE” 也有可能被输出。
注意:对于同一个key,flatMap1()和flatMap2()的调用顺序是无法控制的,因为这两个流是相互竞争的。对于需要保证时间和/或顺序的场景,必须将元素缓存在状态中,直到它们能够被处理。
3.3.5 练习
3.4 流式分析
https://nightlies.apache.org/flink/flink-docs-stable/docs/learn-flink/streaming_analytics/
3.4.1 事件时间和水印
3.4.1.1 概要
Flink支持三种时间语义:
- 事件时间(event time):事件产生的时间
- 摄入时间(ingestion time):Flink读取事件的时间
- 处理时间(processing time):特定算子处理事件的时间
注:Flink时间戳的单位是毫秒。
使用事件时间可以得到可复现的结果,无论什么时候计算结果都一样。实时应用可能会使用处理时间,但多次运行会得到不同的结果,使得重新分析历史数据或者测试新代码比较困难。
要使用事件时间,需要用到水印。
3.4.1.2 水印
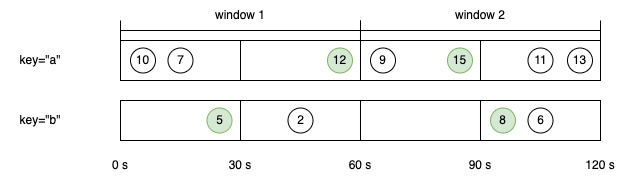
考虑一个简单的例子。有一个乱序到达的事件流,如下所示,其中数字表示事件发生时间:
1
... 23 19 22 24 21 14 17 13 12 15 9 11 7 2 4 ->
假设要对事件流排序:在每个事件到达时就处理事件,输出按时间戳排序的流。但是发现存在一些困难:
(1)第一个到达的事件的时间戳是4,但不能立即将其输出,因为更早的事件可能还未到达(站在上帝视角可以知道必须等待时间戳为2的事件到达)。因此,缓冲和延迟是必要的。
(2)如果处理不当,可能会永远等待。排序程序首先会看到时间戳为4的事件,之后看到时间戳为2的事件。接下来是否会有时间戳小于2的事件到达?可能会,也可能不会(再次站在上帝视角,可以知道永远不会看到时间戳1)。因此,必须在某个时刻决定将2作为第一个输出结果。
(3)接下来需要一种策略,来定义对于给定时间戳的事件,何时停止等待更早事件的到达——这正是水印的作用:
t时刻的水印 Watermark(t)表示t时刻之前的事件(很可能)已经全部到达。在Watermark(t)之后到达且时间戳≤t的事件称为迟到事件。例如,时间戳9:00的水印在10:00到达,则10:00之后到达、时间戳在9:00及以前(即延迟1个小时及以上)的事件是迟到的。
Flink处理事件时间依赖于水印生成器,将带有时间戳的特殊元素(水印)插入到流中。当t时刻的水印到达时停止等待时间戳≤t的事件。 在这个例子中,当时间戳≥2的水印到达时,将2输出作为已经排好序的流。
(4)如何决定水印的生成策略?每个事件都会延迟一段时间后到达,这些延迟有大有小。一种简单的方法是假定这些延迟有一个上界,Flink将这种策略称为“有界乱序”(bounded-out-of-orderness)水印。
3.4.1.3 延迟 vs. 完整性
流应用开发者需要在延迟和完整性之间权衡:如果将水印的边界时间设置得较小,则等待时间较短,但丢失的数据较多;反之得到的数据更完整,但延迟较大。
3.4.1.4 使用水印
使用水印最简单的方式是用WatermarkStrategy。例如:
1
2
3
4
5
6
7
DataStream<Event> events = ...;
WatermarkStrategy<Event> strategy = WatermarkStrategy
.<Event>forBoundedOutOfOrderness(Duration.ofSeconds(20))
.withTimestampAssigner((event, recordTimestamp) -> event.timestamp);
DataStream<Event> withTimestampsAndWatermarks = events.assignTimestampsAndWatermarks(strategy);
其中forBoundedOutOfOrderness()表示使用“有界乱序”策略,即周期性地插入当前最大事件时间-20秒的水印;withTimestampAssigner()指定如何提取事件时间。
注:“t时刻的水印到达时停止等待t时刻及以前的事件” ⇔ “如果事件时间≤当前水印时间则丢弃该事件”,这一逻辑需要自己实现,见3.5.1.2节PseudoWindow.processElement()方法。
3.4.2 窗口
Flink具有非常富有表现力的窗口(window)语义。本节将介绍:
- 如何使用窗口来计算无界流上的聚合
- Flink支持哪些类型的窗口
- 如何使用窗口聚合
3.4.2.1 概要
在处理无界流时,很自然地希望对流的有界子集进行聚合分析,以便回答以下问题:
- 每分钟的页面浏览量
- 每个用户每周的会话数
- 每个传感器每分钟的最高温度
用Flink进行窗口分析主要依赖两个抽象:窗口分配器(window assigner)和窗口函数(window function)。窗口分配器用于将事件分配到窗口,窗口函数用于处理窗口内的事件。
此外还有触发器(trigger)和驱逐器(evictor)。触发器确定何时调用窗口函数,驱逐器删除窗口中的元素。
在已分组的流(KeyedStream)上使用窗口的一般形式如下:
1
2
3
4
stream
.keyBy(keySelector)
.window(windowAssigner)
.reduce|aggregate|process(windowFunction);
也可以在未分组的流上使用窗口,但处理不能并行化:
1
2
3
stream
.windowAll(windowAssigner)
.reduce|aggregate|process(windowFunction);
3.4.2.2 窗口分配器
Flink有一些内置的窗口分配器,如下图所示。

下面是如何使用这些窗口分配器的示例:
- 滚动时间窗口(tumbling time windows):每分钟页面浏览量,
TumblingEventTimeWindows.of(Time.minutes(1)) - 滑动时间窗口(sliding time windows):每10秒钟计算前1分钟的页面浏览量,
SlidingEventTimeWindows.of(Time.minutes(1), Time.seconds(10)) - 会话窗口(session windows):每个会话的网页浏览量,其中会话之间的间隔至少为30分钟,
EventTimeSessionWindows.withGap(Time.minutes(30))
基于时间的窗口分配器(包括会话窗口)既可以使用事件时间,也可以使用处理时间(将类名中的EventTime改为ProcessingTime即可)。这两种时间窗口各有利弊,使用处理时间窗口具有以下限制:
- 无法正确处理历史数据
- 无法正确处理乱序数据
- 结果是不确定的
但优势是延迟较低。
注:使用基于事件时间的窗口必须先调用assignTimestampsAndWatermarks()指定时间戳。
基于计数的窗口只有在到达一个完整批次时才会触发计算,无法设置超时,除非自定义触发器。
全局窗口分配器将(具有相同key的)所有事件分配到同一个全局窗口,这只有在自定义触发器时才有用。很多情况下使用ProcessFunction更好(见3.5.1节)。
3.4.2.3 窗口函数
有三种方式处理窗口内的数据:
- 批处理,使用ProcessWindowFunction,接受一个包含窗口中所有元素的
Iterable,可以全量计算; - 增量式处理,使用
ReduceFunction或AggregateFunction,每个事件被分配到窗口时都会调用一次; - 二者结合,通过
ReduceFunction或AggregateFunction预聚合的结果在触发窗口时提供给ProcessWindowFunction做全量计算。
下面展示第一种和第三种方式的示例,用于计算传感器在1分钟窗口内的峰值,产生一个包含元组(key, 窗口结束时间戳, 最大值)的流。
批处理方式使用MyWastefulMax,输出结果:
1
2
3
4
(a,60000,12)
(b,60000,5)
(a,120000,15)
(b,120000,8)
注意:
- Flink会在状态中缓存分配到窗口的事件,直到触发计算,这可能需要大量存储空间。
ProcessWindowFunction有一个Context参数,其windowState()和globalState()分别返回可以存储当前key当前窗口和当前key全局信息的状态对象。
增量聚合、批处理结合方式使用MyReducingMax和MyWindowFunction,结果与批处理方式相同。
注意MyWindowFunction的Iterable<SensorReading>参数只包含一个元素,即MyReducingMax预先计算的最大值。
3.4.2.4 迟到事件
默认情况下,使用事件时间窗口时,迟到的事件会被丢弃,但窗口API提供了两个选项来控制这些事件。
可以使用旁路输出(side output)机制(见3.5.2节)将这些事件收集到另一个输出流。例如:
1
2
3
4
5
6
7
8
9
OutputTag<Event> lateTag = new OutputTag<Event>("late"){};
SingleOutputStreamOperator<Event> result = stream
.keyBy(...)
.window(...)
.sideOutputLateData(lateTag)
.process(...);
DataStream<Event> lateStream = result.getSideOutput(lateTag);
也可以执行允许的延迟间隔,延迟在这个间隔内的事件仍然会被分配到对应的窗口,每个迟到事件都会导致窗口函数被再次调用。例如:
1
2
3
4
5
stream
.keyBy(...)
.window(...)
.allowedLateness(Time.seconds(10))
.process(...);
3.4.3 练习
3.5 事件驱动的应用
https://nightlies.apache.org/flink/flink-docs-stable/docs/learn-flink/event_driven/
3.5.1 ProcessFunction
3.5.1.1 简介
ProcessFunction将事件处理与计时器和状态相结合,使其成为流处理应用的强大构建模块。这是使用Flink创建事件驱动应用的基础。
注:
- 还有其他几种处理函数,例如KeyedProcessFunction、CoProcessFunction等。
- 这些处理函数都实现了
RichFunction接口,因此可以访问状态。 ProcessFunction要实现两个主要的回调函数:processElement()和onTimer()。processElement()对于每个输入事件都会被调用,onTimer()在计时器触发时被调用。计时器可以基于事件时间,也可以基于处理时间。两个回调函数都提供了可以获取TimerService的上下文对象,TimerService用于管理计时器。
利用ProcessFunction可以对流执行任何操作,实现任何想要的功能。例如,使用ProcessFunction + 状态 + 计时器可以实现窗口功能。
3.5.1.2 示例
在上一节的练习Hourly Tips中,使用滚动窗口来计算每小时内每个司机的小费总和:
1
2
3
4
5
// compute the sum of the tips per hour for each driver
DataStream<Tuple3<Long, Long, Float>> hourlyTips = fares
.keyBy(fare -> fare.driverId)
.window(TumblingEventTimeWindows.of(Time.hours(1)))
.process(new AddTips());
下面使用KeyedProcessFunction实现同样的操作:
1
2
3
4
// compute the sum of the tips per hour for each driver
DataStream<Tuple3<Long, Long, Float>> hourlyTips = fares
.keyBy(fare -> fare.driverId)
.process(new PseudoWindow(Time.hours(1)));
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
// Compute the sum of the tips for each driver in hour-long windows.
// The keys are driverIds.
class PseudoWindow extends KeyedProcessFunction<Long, TaxiFare, Tuple3<Long, Long, Float>> {
private final long durationMillis;
private transient MapState<Long, Float> sumOfTips;
public PseudoWindow(Time duration) {
this.durationMillis = duration.toMilliseconds();
}
@Override
public void open(Configuration conf) {
sumOfTips = getRuntimeContext().getMapState(new MapStateDescriptor<>("sumOfTips", Long.class, Float.class));
}
@Override
public void processElement(
TaxiFare fare,
Context ctx,
Collector<Tuple3<Long, Long, Float>> out) throws Exception {
long eventTime = fare.getEventTime();
TimerService timerService = ctx.timerService();
if (eventTime <= timerService.currentWatermark()) {
// This event is late; its window has already been triggered.
return;
}
// Round up eventTime to the end of the window containing this event.
long endOfWindow = eventTime - (eventTime % durationMillis) + durationMillis;
// Schedule a callback for when the window has been completed.
timerService.registerEventTimeTimer(endOfWindow);
// Add this fare's tip to the running total for that window.
Float sum = sumOfTips.get(endOfWindow);
if (sum == null) {
sum = 0.0f;
}
sum += fare.tip;
sumOfTips.put(endOfWindow, sum);
}
@Override
public void onTimer(
long timestamp,
OnTimerContext ctx,
Collector<Tuple3<Long, Long, Float>> out) throws Exception {
long driverId = ctx.getCurrentKey();
// Look up the result for the hour that just ended.
Float sumOfTips = this.sumOfTips.get(timestamp);
Tuple3<Long, Long, Float> result = Tuple3.of(timestamp, driverId, sumOfTips);
out.collect(result);
this.sumOfTips.remove(timestamp);
}
}
注意:
- 由于事件可能乱序到达,因此
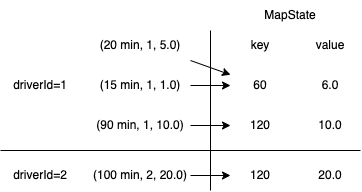
open()方法中使用MapState记录每个“窗口”内的小费总和,其中key是窗口结束时间,value是小费总和。另外,在KeyedProcessFunction中,状态是与外层key关联的,在这里是司机id。 processElement()方法将迟到事件丢弃(也可以使用旁路输出,见下一节)。对于未迟到事件,首先计算其所属的“窗口”,使用窗口结束时间作为key查询状态,累加小费,并更新状态;之后调用timerService.registerEventTimeTimer()注册基于事件时间的计时器回调函数,在给定时间戳的水印到达(即当前“窗口”结束)时将被调用。onTimer()方法使用timestamp(即窗口结束时间)作为key查询状态,得到当前“窗口”的小费总和,并与外层key(司机id)一起作为输出。
每条记录与MapState的对应关系如下图所示:
3.5.2 旁路输出
3.5.2.1 简介
有时希望一个算子有多个输出流,例如用于报告:
- 异常情况
- 格式错误的事件
- 迟到的事件
- 告警,例如与外部服务的连接超时
旁路输出(side output)是实现这些功能的一种方便的方式。除了错误报告,也可以实现流的n路分割。
3.5.2.2 示例
现在可以处理上一节中忽略的迟到事件。
旁路输出与OutputTag关联。
例如,在PseudoWindow类中增加
1
public static final OutputTag<TaxiFare> lateFares = new OutputTag<TaxiFare>("lateFares") {};
注意,必须定义为匿名内部类。
在processElement()方法中可以将迟到事件发送到旁路输出:
1
2
3
4
5
6
if (eventTime <= timerService.currentWatermark()) {
// This event is late; its window has already been triggered.
ctx.output(lateFares, fare);
} else {
...
}
在main()方法中可以访问旁路输出流:
1
hourlyTips.getSideOutput(PseudoWindow.lateFares).print();
3.5.3 练习
3.6 容错
https://nightlies.apache.org/flink/flink-docs-stable/docs/learn-flink/fault_tolerance/
3.6.1 状态后端
Flink管理的状态是一种分片的键值对存储,每个key对应的状态对象都保存在key所属的TaskManager本地。
Flink管理的状态存储在状态后端(state backend)。Flink有两种状态后端的实现:一种基于RocksDB,将状态存储在磁盘上;另一种基于堆,将状态存储在Java堆内存中。
访问RocksDB状态后端中的对象涉及序列化和反序列化,因此会有更大的开销,但RocksDB可存储的状态数量仅受本地磁盘大小的限制。只有RocksDB能够进行增量快照,对于状态数量大、变化慢的应用有很大好处。
所有状态后端都能异步执行快照,这意味着可以在不妨碍正在进行的流处理的情况下执行快照。
3.6.2 检查点存储
Flink会定期获取每个算子所有状态的快照,并将这些快照保存到持久化的位置,例如分布式文件系统。如果发生故障,Flink可以恢复应用的完整状态并继续处理,就如同没有出现过异常。
这些快照的存储位置由检查点存储(checkpoint storage)定义。有两种检查点存储的实现:一种保存在分布式文件系统上,另一种使用JobManager的堆内存。
注:使用StreamExecutionEnvironment.enableCheckpointing()启用检查点功能。
3.6.3 状态快照
3.6.3.1 定义
- 快照(snapshot):所有数据源的指针(例如文件或Kafka分区的偏移量)以及所有算子状态的副本。
- 检查点(checkpoint):Flink自动获取的状态快照,用于从故障中恢复。
- 外部化的检查点(externalized checkpoint):Flink只保留作业运行时的最近n个检查点,并在作业取消时删除。但也可以将其配置为保留,从而可以手动从中恢复。
- 保存点(savepoint):用户手动触发的检查点。保存点始终是完整的,并且已针对操作灵活性进行了优化。
3.6.3.2 快照如何工作
Flink使用Chandy-Lamport算法的一种变体,称为异步屏障快照(asynchronous barrier snapshotting)。
当TaskManager接收到检查点协调器(JobManager的一部分)的指示开始生成检查点时,它会让所有source记录自己的偏移量,并将编号的检查点屏障(checkpoint barrier)插入到它们的流中。这些屏障表示每个检查点在流中的位置(类似于水印的概念),如下图所示。

检查点n将包含每个算子在消费了严格位于屏障n之前的所有事件后生成的状态。
当每个算子接收到屏障之后就会记录其状态。有两个输入流的算子(例如CoProcessFunction)将进行屏障对齐,使得生成的快照包含消费了两个输入流各自的屏障之前的所有事件后生成的状态,如下图所示。

3.6.3.3 恰好一次保证
当流处理应用发生错误时,结果可能会产生丢失或重复。Flink根据应用和集群的配置可能产生以下结果:
- 至多一次(at most once):Flink不从错误中恢复,可能有丢失
- 至少一次(at least once):没有丢失,但可能有重复
- 恰好一次(exactly once):没有丢失或重复
这些语义保证可使用CheckpointingMode配置。
Flink通过回退(rewinding)和重放(replaying)源数据流来从故障中恢复。理想情况“恰好一次” 并不意味着每个事件都将被处理恰好一次,而是每个事件都将影响Flink管理的状态恰好一次。
3.6.3.4 端到端恰好一次
为了实现端到端的恰好一次,即source中的每个事件都对sink生效恰好一次,必须满足以下条件:
- source必须是可重放的
- sink必须是事务性的(或幂等的)
4.Table API & SQL
https://nightlies.apache.org/flink/flink-docs-stable/docs/dev/table/overview/
Flink提供了两个关系型 API:Table API和SQL,用于统一流式和批处理。Table API是一种语言集成查询API,支持Java、Scala和Python,能够以非常直观的方式使用选择、过滤和连接等关系运算符来组合查询。Flink SQL基于Apache Calcite,它实现了SQL标准。无论输入是连续的(流式)还是有界的(批处理),用两种接口编写的查询都具有相同的语义,输出相同的结果。
Table API和SQL以及DataStream API可以互相无缝集成。
Table API & SQL需要的依赖见2.2.2节。为了在IDE中运行Table API程序,还需要添加依赖flink-table-planner_2.12。
4.1 基本概念和常用API
https://nightlies.apache.org/flink/flink-docs-stable/docs/dev/table/common/
Table API和SQL的核心概念是Table,表示一个关系型表,包含行和列(类似于MySQL数据库表),用作查询的输入和输出。
下面的示例展示了Table API和SQL程序的通用结构:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
// Create a TableEnvironment for batch or streaming execution.
// See the "Create a TableEnvironment" section for details.
TableEnvironment tableEnv = TableEnvironment.create(...);
// Create a source table
tableEnv.createTemporaryTable("SourceTable", TableDescriptor.forConnector("datagen")
.schema(Schema.newBuilder()
.column("f0", DataTypes.STRING())
.build())
.option(DataGenConnectorOptions.ROWS_PER_SECOND, 100L)
.build());
// Create a sink table (using SQL DDL)
tableEnv.executeSql("CREATE TEMPORARY TABLE SinkTable WITH ('connector' = 'blackhole') LIKE SourceTable (EXCLUDING OPTIONS) ");
// Create a Table object from a Table API query
Table table1 = tableEnv.from("SourceTable");
// Create a Table object from a SQL query
Table table2 = tableEnv.sqlQuery("SELECT * FROM SourceTable");
// Emit a Table API result Table to a TableSink, same for SQL result
TableResult tableResult = table1.insertInto("SinkTable").execute();
4.1.1 示例:单词计数
下面是使用Table API和SQL实现的单词计数示例。
fromValues()方法用于从给定的值创建一张表,可以通过DataType参数指定列名。
使用批处理模式时(inBatchMode()),程序的输出如下(顺序可能不同)。此时Table API等价于DataSet API(见2.3节)。
1
2
3
4
5
6
7
8
9
10
11
+--------------------------------+-----------------+
| word | total_frequency |
+--------------------------------+-----------------+
| or | 1 |
| to | 15 |
| the | 15 |
| be | 3 |
| is | 2 |
| that | 4 |
| not | 2 |
+--------------------------------+-----------------+
使用流模式时(inStreamingMode()),结果中增加了op列(含义参见4.2节),并且total_frequency由总和变为前缀和。在这种情况下,Table API等价于DataStream API,见3.3.2.2节的示例。
1
2
3
4
5
6
7
8
9
10
11
12
13
+----+--------------------------------+-----------------+
| op | word | total_frequency |
+----+--------------------------------+-----------------+
| +I | is | 2 |
| +I | that | 4 |
| +I | not | 2 |
| +I | or | 1 |
| +I | to | 5 |
| -U | to | 5 |
| +U | to | 15 |
| +I | be | 3 |
| +I | the | 15 |
+----+--------------------------------+-----------------+
4.1.1 创建TableEnvironment
TableEnvironment是Table API和SQL程序的入口点,负责创建表、执行查询、管理UDF等。每个Table都绑定到一个特定的TableEnvironment。
通过调用静态方法create()来创建TableEnvironment:
1
2
EnvironmentSettings settings = EnvironmentSettings.inStreamingMode(); // or inBatchMode()
TableEnvironment tableEnv = TableEnvironment.create(settings);
其中EnvironmentSettings类的静态方法inStreamingMode()和inBatchMode()分别使作业以流模式(默认)和批处理模式工作。
或者,可以从现有的StreamExecutionEnvironment创建StreamTableEnvironment,以便与DataStream API进行互操作。
1
2
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
Table API和SQL可以很容易地与DataStream API集成,并在Table和DataStream之间相互转换,详见4.2节。
4.1.2 创建表
TableEnvironment维护了一个表目录。表标识符由三部分组成:目录(catalog)名、数据库(database)名和表名,例如my_catalog.my_database.my_table。如果未指定目录或数据库,则使用当前默认值。
表可以是常规表(TABLE)或虚拟表(VIEW)。常规表用于描述外部数据,例如文件、数据库表或消息队列。视图可以从现有的Table对象创建。
创建连接器表
连接器(connector)描述了外部数据源,例如Kafka、文件系统、JDBC等。
可以直接使用Table API创建常规表。首先使用静态方法TableDescriptor.forConnector()创建表描述符,之后使用TableEnvironment类的createTemporaryTable()方法创建临时表,或者使用createTable()方法创建永久表。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
// Using table descriptors
Schema sourceSchema = Schema.newBuilder()
.column("order_id", DataTypes.VARCHAR(20).notNull())
.column("user_id", DataTypes.INT())
.column("product_id", DataTypes.INT())
.column("price", DataTypes.DECIMAL(10, 2))
.column("quantity", DataTypes.INT())
.column("create_time", DataTypes.TIMESTAMP(3))
.primaryKey("order_id")
.build();
TableDescriptor sourceDescriptor = TableDescriptor.forConnector("datagen")
.schema(sourceSchema)
.option(DataGenConnectorOptions.NUMBER_OF_ROWS, 1000L)
.build();
tableEnv.createTemporaryTable("Orders", sourceDescriptor);
也可以使用SQL DDL创建表:
1
2
3
4
5
6
7
8
9
10
11
12
CREATE TABLE Orders (
order_id VARCHAR(20) NOT NULL,
user_id INT,
product_id INT,
price DECIMAL(10, 2),
quantity INT,
create_time TIMESTAMP(3),
PRIMARY KEY order_id
) WITH (
'connector' = 'datagen',
'number-of-rows' = '1000'
)
通过调用tableEnv.executeSql()来执行以上SQL字符串。
DateGen连接器是基于内存数据生成的数据源。默认情况下是无界的,可以通过number-of-rows选项指定行数使其成为有界的。无界表只能用于流模式,而有界表可以用于流模式或批处理模式。每个字段都是随机值,可以通过fields.#.min和fields.#.max等选项指定最小值/最大值。详见文档DataGen SQL Connector。
Flink SQL支持的数据类型参见Data Types。
Table API连接器的完整列表参见Table API Connectors。
创建视图
Table对象对应SQL术语中的VIEW(虚拟表),它封装了逻辑查询计划。可以使用createTemporaryView()方法创建视图:
1
2
3
4
5
// table is the result of a simple projection query
Table projTable = tableEnv.from("myTable").select(...);
// register the Table projTable as table "projectedTable"
tableEnv.createTemporaryView("projectedTable", projTable);
4.1.3 查询表
可以使用Table API或SQL两种方式对Table对象执行查询操作。
Table API
Table API是一种语言集成查询API,使用Table类提供的方法来执行关系型查询操作,返回一个新的Table对象。调用其execute()方法来执行查询操作。
下面的示例展示了一个简单的Table API聚合查询:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
// register Orders table
tableEnv.createTemporaryTable("Orders", ...);
// scan registered Orders table
Table orders = tableEnv.from("Orders");
// compute order count and total amount for all users
Table userStats = orders
.groupBy($("user_id"))
.select($("user_id"),
$("order_id").count().as("order_count"),
$("price").times($("quantity")).sum().as("total_amount"))
.orderBy($("total_amount").desc());
// print the result
userStats.execute().print();
其中$()是org.apache.flink.table.api.Expressions类的静态方法,用于引用具有给定名字的列。
完整代码:用户订单数据
下表列出了常用查询操作:
| SQL | Table API |
|---|---|
SELECT a | select($("a")) |
SELECT SUM(b) AS b | select($("b").sum().as("b")) |
FROM x | tableEnv.from("x") |
WHERE b = 'red' | where($("b").isEqual("red")) filter($("b").isEqual("red")) |
GROUP BY a | groupBy($("a")) |
ORDER BY a ASC | orderBy($("a").asc()) |
INSERT INTO y | insertInto("y") |
Table API操作的完整列表(流式和批处理统一)参见Table API。
内置SQL函数参见System (Built-in) Functions。
SQL
Flink SQL基于Apache Calcite,它实现了SQL标准。可以将SQL查询作为字符串传递给TableEnvironment类的sqlQuery()方法,返回一个Table对象。或者直接调用TableEnvironment类的executeSql()方法执行SQL。
下面是使用SQL实现的与上一节中用户订单示例相同的查询操作:
1
2
3
4
5
6
7
8
9
Table userStats = tableEnv.sqlQuery(
"SELECT " +
" user_id," +
" COUNT(*) AS order_count," +
" SUM(price * quantity) AS total_amount " +
"FROM Orders " +
"GROUP BY user_id " +
"ORDER BY total_amount DESC"
);
Flink SQL语法参见文档SQL。
混合Table API和SQL
Table API和SQL查询可以很容易地混合使用,因为二者都返回Table对象:
- 可以在SQL查询返回的
Table对象上调用Table API查询。 - 可以通过在
TableEnvironment中注册结果表并在FROM子句中引用来对Table API查询的结果执行SQL查询。
4.1.4 输出表
通过将表写入DynamicTableSink来输出表。DynamicTableSink接口是对外部存储系统的抽象,例如文件系统、消息队列、JDBC等。
与输入表一样,输出表也可以通过连接器来创建,并调用Table对象的insertInto()方法或者使用SQL的INSERT INTO语句来输出数据。另外,也可以自定义DynamicTableSink,参见文档User-defined Sources & Sinks。
FileSystem连接器可以将表输出到文件系统(对应的实现类是FileSystemTableSink)。只需在创建输出表时指定连接器名称filesystem和文件格式。例如,下面的代码定义了一个连接到CSV文件的输出表:
1
2
3
4
5
6
7
8
9
10
11
12
13
Schema sinkSchema = Schema.newBuilder()
.column("user_id", DataTypes.INT())
.column("order_count", DataTypes.BIGINT())
.column("total_amount", DataTypes.DECIMAL(10, 2))
.build();
TableDescriptor sinkDescriptor = TableDescriptor.forConnector("filesystem")
.schema(sinkSchema)
.option("path", "/path/to/dir")
.format(FormatDescriptor.forFormat("csv")
.option("field-delimiter", "|")
.build())
.build();
tableEnv.createTemporaryTable("User_stats", sinkDescriptor);
等价的SQL DDL如下:
1
2
3
4
5
6
7
8
9
10
CREATE TABLE User_stats (
user_id INT,
order_count BIGINT,
total_amount DECIMAL(10, 2)
) WITH (
'connector' = 'filesystem',
'path' = 'file:///path/to/dir',
'format' = 'csv',
'csv.field-delimiter' = '|'
)
为了使用FileSystem连接器和CSV格式,需要添加以下依赖:
1
2
3
4
5
6
7
8
9
10
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-files</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-csv</artifactId>
<version>${flink.version}</version>
</dependency>
像这样输出一张表:
1
2
3
4
5
6
7
8
9
// Using Table API
Table userStats = ...;
userStats.insertInto("User_stats").execute();
// Or using SQL
tableEnv.executeSql(
"INSERT INTO User_stats " +
"SELECT ..."
);
连接器的完整列表以及每种能否作为输入/输出参见文档Table API Connectors。
格式的完整列表以及支持的连接器参见文档Formats。
4.2 DataStream API集成
https://nightlies.apache.org/flink/flink-docs-stable/docs/dev/table/data_stream_api/
Table API和DataStream API都可以处理有界流和无界流。Flink提供了特殊的桥接功能,使这两个API可以混合使用,为此需要添加依赖flink-table-api-java-bridge或flink-table-api-scala-bridge_2.12。
Flink提供了一个专门的StreamTableEnvironment,用于与DataStream API集成。这个接口扩展了常规的TableEnvironment,可以通过DataStream API中使用的StreamExecutionEnvironment来创建,并增加了用于在DataStream和Table之间互相转换的方法(如下表所示)。
| 转换 | 方法 |
|---|---|
DataStream<T> → Table | fromDataStream(), fromChangelogStream() |
Table → DataStream<Row> | toDataStream(), toChangelogStream() |
1
2
3
4
5
6
7
8
9
10
11
12
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
DataStream<String> dataStream = ...;
// convert DataStream to Table
Table inputTable = tableEnv.fromDataStream(dataStream);
Table resultTable = ...;
// convert Table to DataStream
DataStream<Row> resultStream = tableEnv.toDataStream(resultTable);
将DataStream转换为Table时,列名和类型可以从DataStream的TypeInformation自动推断,也可以手动指定(作为fromDataStream()方法的第二个参数)。
下面的示例代码展示了如何在两个API之间相互转换。
输出结果如下:
1
2
3
+I[ALICE]
+I[BOB]
+I[JOHN]
其中+I表示插入操作,另外几种类型如下表所示(对应RowKind枚举):
| 类型 | 名称 | 含义 |
|---|---|---|
+I | INSERT | 插入操作 |
-U | UPDATE_BEFORE | 更新操作(旧值) |
+U | UPDATE_AFTER | 更新操作(新值) |
-D | DELETE | 删除操作 |
在上面的例子中没有聚合操作,因此输出只包含+I类型的记录。但是在很多情况下,将Table转换为DataStream时不仅会产生插入,还会产生更新。在这种情况下,使用toDataStream()会导致异常:
1
Table sink 'xxx' doesn't support consuming update changes which is produced by ...
在这种情况下,需要使用toChangelogStream()。
下面的示例展示了如何转换可更新表(相对于Insert-only)。结果中的每一行都表示一个更新操作(其类型可通过row.getKind()得到),称为changelog流。在这个例子中,SUM(score)计算的是前缀和。Alice的第一条记录产生一个插入操作+I[Alice, 12];第二条记录则会产生两个更新操作:更新前-U[Alice, 12]和更新后+U[Alice, 112]。
上面的示例展示了Table API如何通过持续地为每条输入记录输出更新操作来增量地计算最终结果(底层原理是动态表,将在下一节介绍)。这使得Table API和SQL也能够处理无界流。然而,在输入流是有界的情况下,利用批处理可以更高效地计算结果。
1
2
3
4
5
6
7
8
9
// setup DataStream API
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// set the batch runtime mode
env.setRuntimeMode(RuntimeExecutionMode.BATCH);
// setup Table API
// the table environment adopts the runtime mode during initialization
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
4.3 动态表
https://nightlies.apache.org/flink/flink-docs-stable/docs/dev/table/concepts/dynamic_tables/
动态表(dynamic table)是Flink的Table API和SQL支持流式数据的核心概念。不同于表示批数据的静态表,动态表会随着时间变化。查询动态表会生成持续查询(continuous query)。持续查询永远不会终止,并产生另一个动态表。
流、动态表和持续查询之间的关系如下图所示:

- 将流转换为动态表。
- 对动态表执行持续查询,生成一个新的动态表。
- 将生成的动态表转换回流。
注:这类似于Spark Structured Streaming的基本思想。
下面将通过具有以下结构的用户点击事件流来解释动态表和持续查询的概念。
1
2
3
4
5
CREATE TABLE clicks (
`user` VARCHAR(20), -- the name of the user
url VARCHAR(100), -- the URL that was accessed by the user
cTime TIMESTAMP(3) -- the time when the URL was accessed
) WITH (...)
完整代码:用户点击事件
4.3.1 流转换为动态表
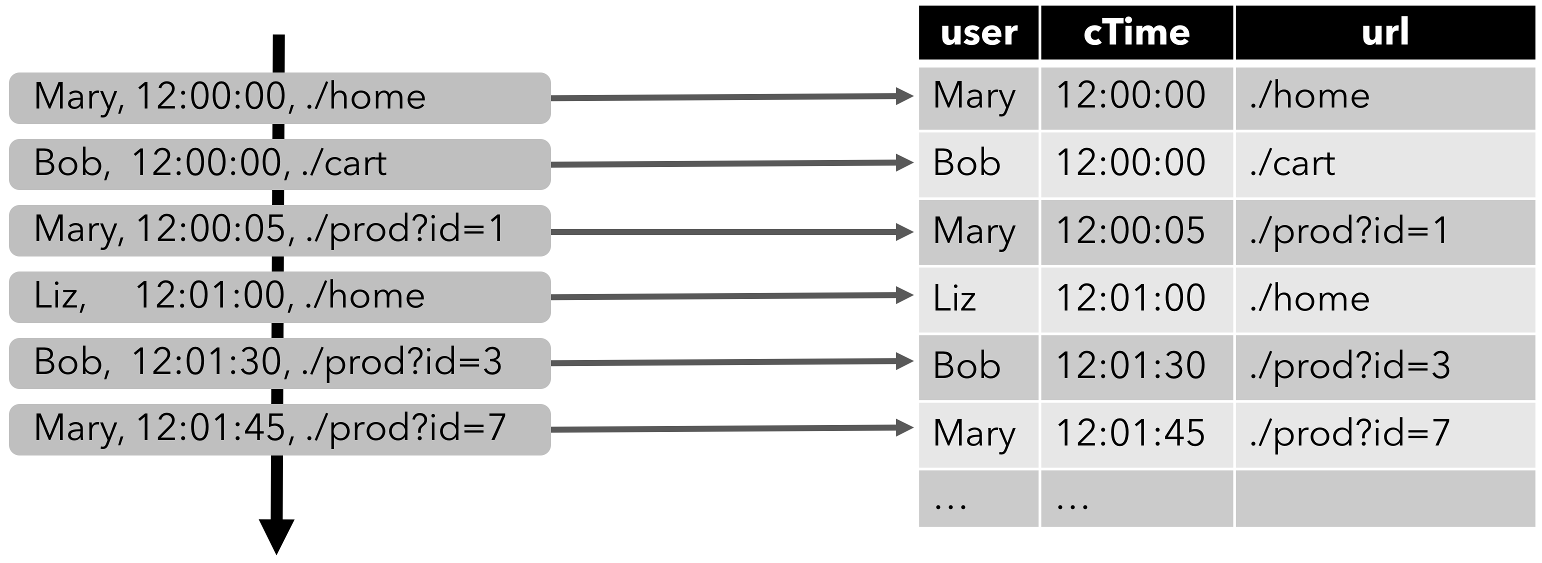
对流执行关系型查询需要将其转换为Table。从概念上讲,流的每条记录都被解释为对结果表的一次INSERT操作。
下图展示了点击事件流如何转换为动态表。随着点击事件的到达,结果表将不断增长。
4.3.2 持续查询
在动态表上执行持续查询会生成一个新的动态表作为结果。与批处理查询相比,持续查询永远不会终止,并根据其输入表的更新来更新结果表。在任何时间点,持续查询在语义上都等价于在输入表的快照上以批处理模式执行相同查询的结果。
下面将展示对点击事件表clicks的两个示例查询。
第一个例子是简单的聚合查询:计算每个用户访问的URL数量。
1
2
3
4
5
SELECT
`user`,
COUNT(url) AS cnt
FROM clicks
GROUP BY `user`
下图展示了查询是如何随着输入表的更新而求值的。
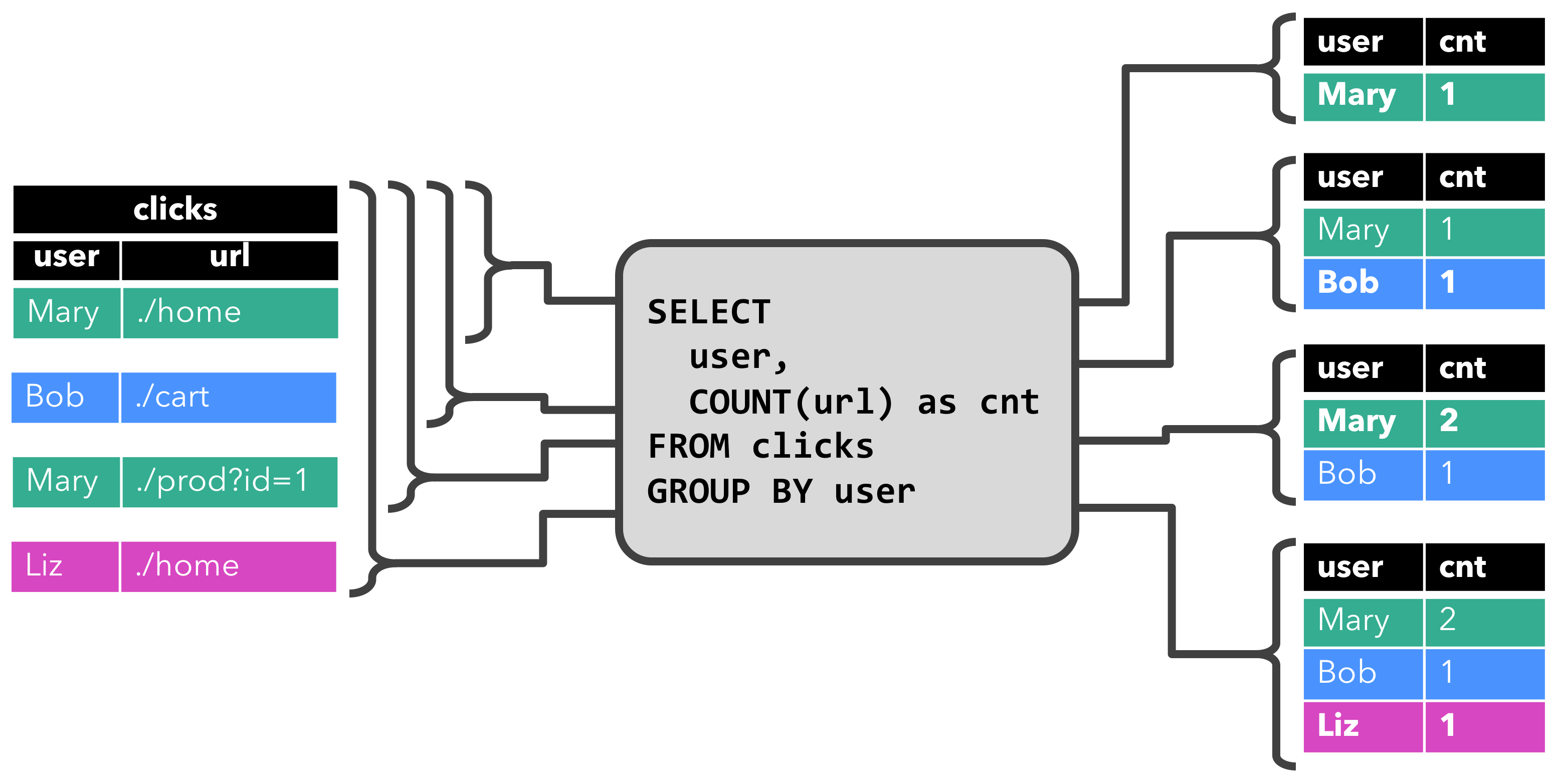
开始时,左侧的clicks表为空。当第一行[Mary, ./home]到达后,结果表(右上)增加一行[Mary, 1]。当第二行[Bob, ./cart]到达后,结果表再增加一行[Bob, 1]。第三行[Mary, ./prod?id=1]会将[Mary, 1]更新为[Mary, 2]。最后,当第四行到达后,结果表增加[Liz, 1]。
注意:右侧的四张表只是在逻辑上说明动态表的更新过程。在这个过程中并没有构建完整的结果表,而是逐条输出更新记录(如下所示)。
1
2
3
4
5
+I[Mary, 1]
+I[Bob, 1]
-U[Mary, 1]
+U[Mary, 2]
+I[Liz, 1]
第二个查询与第一个类似,但分组维度除了user外还包括小时级滚动窗口。
1
2
3
4
5
6
7
8
SELECT
`user`,
TUMBLE_END(cTime, INTERVAL '1' HOURS) AS endT,
COUNT(url) AS cnt
FROM clicks
GROUP BY
`user`,
TUMBLE(cTime, INTERVAL '1' HOURS)
注:基于时间的计算(例如窗口)是基于特殊的时间属性,需要在创建表时定义水印:
1
2
3
4
CREATE TABLE clicks (
...,
WATERMARK FOR cTime AS cTime - INTERVAL '5' SECOND
) WITH (...)
或者
1
2
3
4
5
Schema schema = Schema.newBuilder()
...
.watermark("cTime", $("cTime").minus(lit(5).seconds()))
.build();
Table clickTable = tableEnv.fromDataStream(clickStream, schema);
下图显示了不同时间点的输入和输出。
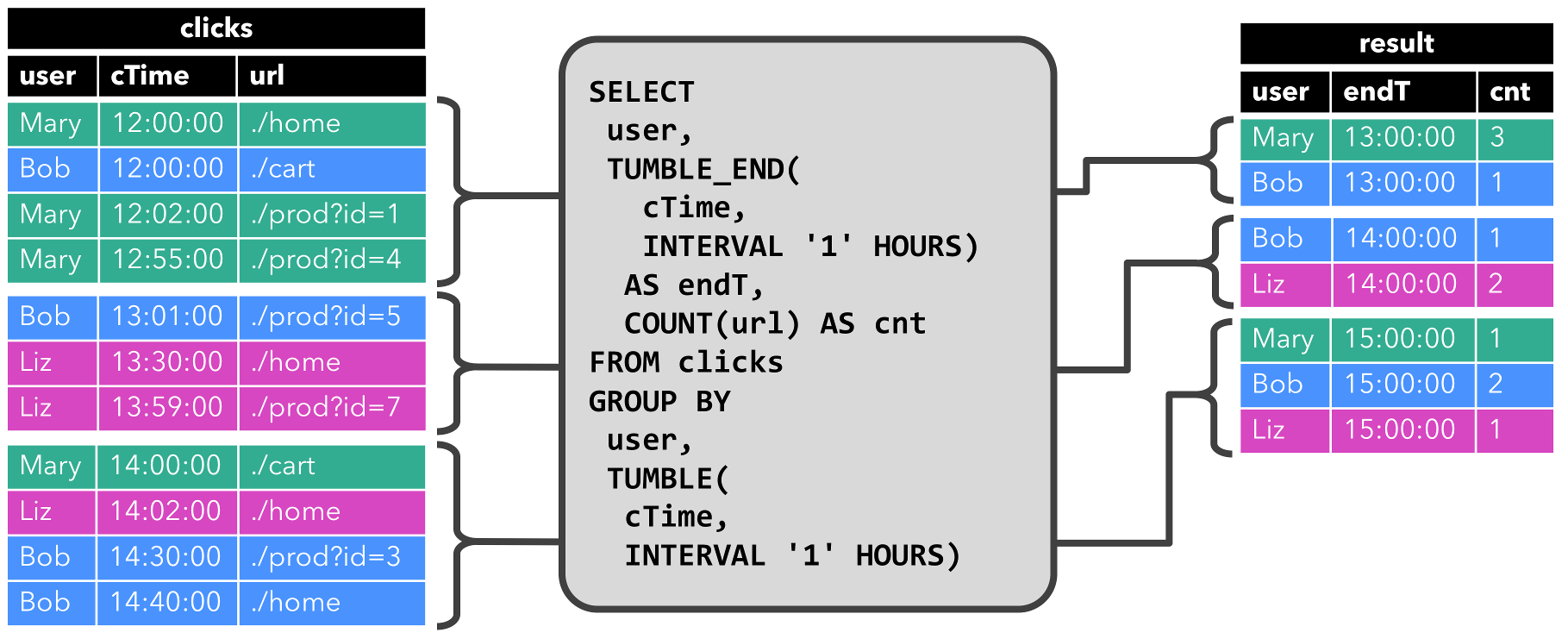
查询每小时计算一次结果,并更新结果表。clicks表包含4个时间戳(cTime)在12:00:00到12:59:59之间的行。查询根据这4行输入计算出2个结果行[Mary, 13:00:00, 3]和[Bob, 13:00:00, 1]。对于下一个窗口13:00:00到13:59:59,clicks表包含3行,这导致另外2行添加到结果表中,以此类推。
尽管这两个示例查询看起来非常相似,但它们在一个关键方面有所不同:
- 第一个查询会更新以前输出的结果,即定义结果表的changelog流包含
INSERT和UPDATE操作。 - 第二个查询只会向结果表追加,即结果表的changelog流仅由
INSERT操作组成。
一个查询生成仅追加表还是可更新表有一些影响:
- 生成可更新表的查询通常需要维护更多状态(例如用户数量可能非常多)。
- 将仅追加表转换为流与可更新表的转换不同(见下一节)。
4.3.3 动态表转换为流
动态表包含INSERT、UPDATE和DELETE操作。将动态表转换为流或写入外部系统时,需要对这些操作进行编码。Flink的Table API和SQL支持三种编码方式:
- Append-only流:仅包含
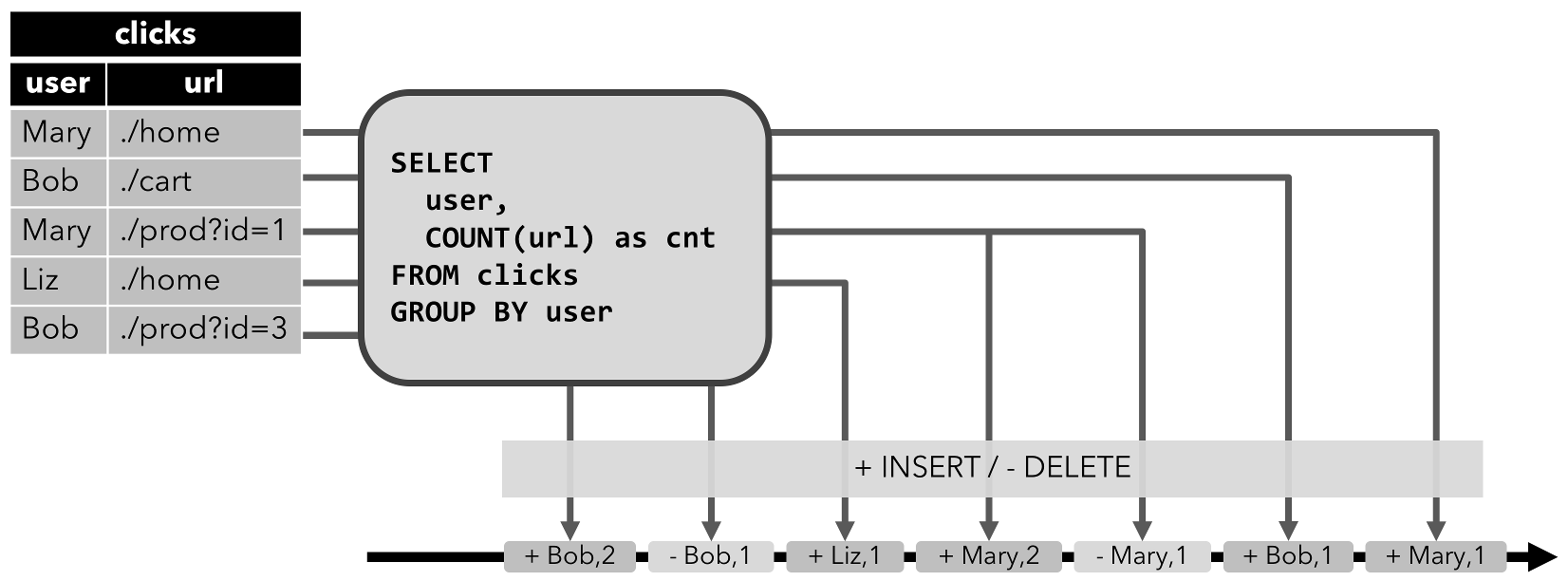
INSERT操作,可以通过输出插入的行转换为流。 - Retract流:包含add和retract两种类型消息的流。通过将
INSERT编码为add消息、将DELETE编码为retract消息、将UPDATE编码为旧值的retract消息以及新值的add消息,从而将动态表转换为retract流(如下图所示)。
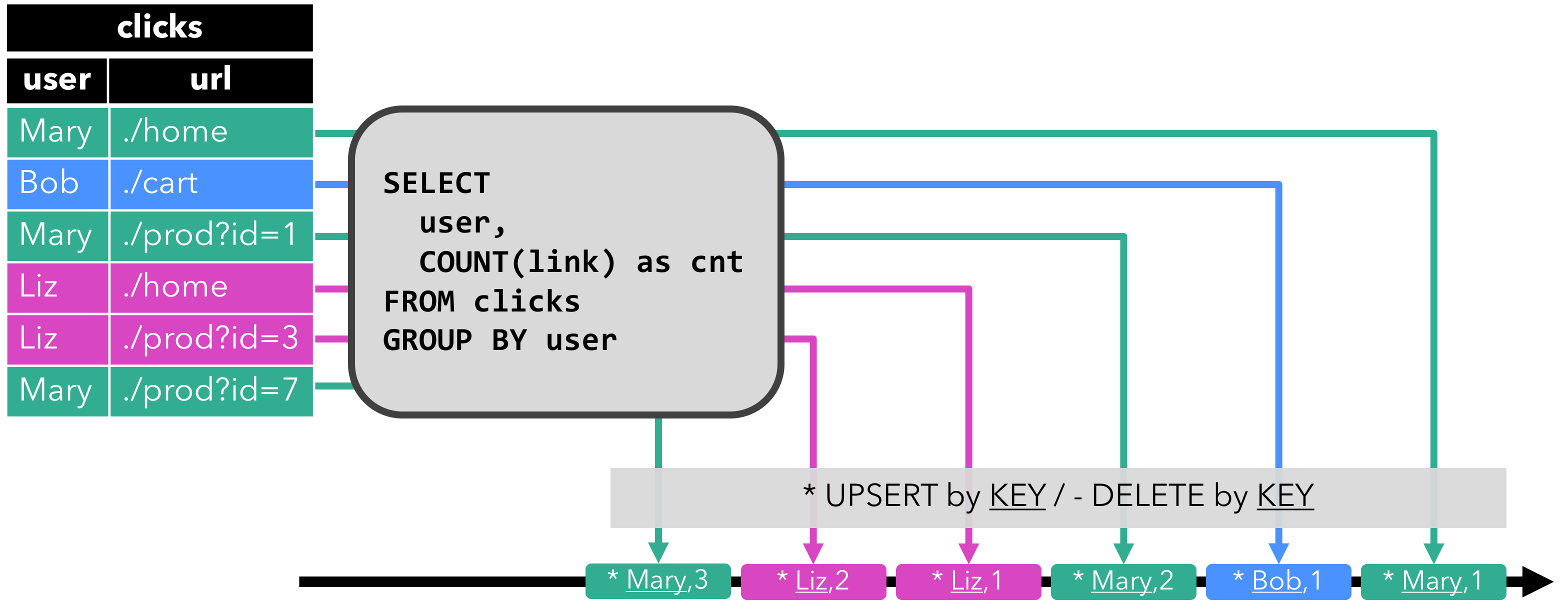
- Upsert流:包含upsert和delete两种消息的流。将动态表转换为upsert流需要一个唯一键,通过将
INSERT和UPDATE编码为upsert消息、将DELETE编码为delete消息实现转换(如下图所示)。与retract流的主要区别在于UPDATE编码为单条消息,因此效率更高。
注意,在将动态表转换为DataStream时,只支持append-only和retract流。