【论文笔记】HAN
Heterogeneous Graph Attention Network
2019 WWW
论文链接:https://arxiv.org/pdf/1903.07293
代码:
- 官方代码:https://github.com/Jhy1993/HAN
- DGL实现:https://github.com/dmlc/dgl/tree/master/examples/pytorch/han
- 个人实现:https://github.com/ZZy979/pytorch-tutorial/tree/master/gnn/han
1.引言
真实世界的数据通常是图结构,例如社交网络、引用网络、万维网等,GNN是一种强大的用于图数据深度表示学习的方法
注意力机制能够处理变长数据,使模型能够聚焦于数据最突出的部分,GAT是一种将注意力机制用于同构图的GNN模型
下图是一个IMDB异构图的例子:
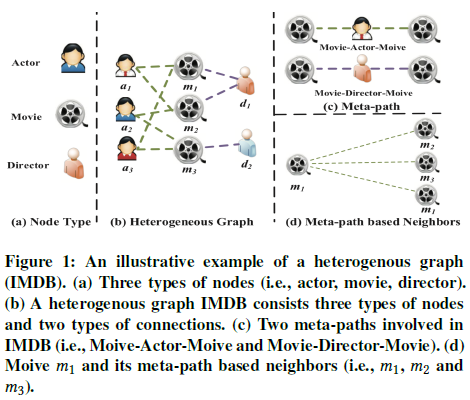
该论文中的一个重要概念是元路径,元路径表示两个顶点之间经过特定类型顶点的连接关系,表达了异构图中的语义信息
例如在上图中,“电影-演员-电影”(MAM)是一种元路径,含义是“同一个演员出演的两部电影”,表达的语义信息是“识别电影类型”;“电影-导演-电影”(MDM)是另一种元路径,含义是“同一个导演执导的两部电影”(表达的语义信息是“电影风格”,猜的)
该论文提出了异构图注意力网络模型HAN,该模型考虑了顶点层次的注意力和语义层次的注意力
顶点层次的注意力旨在学习基于元路径的邻居的重要性,并给它们赋予不同的注意力权重
例如,《终结者》、《终结者2》和《泰坦尼克号》都是导演詹姆斯·卡梅隆的电影,即《终结者2》和《泰坦尼克号》都是《终结者》基于元路径MDM的邻居;如果要识别《终结者2》的类型为科幻电影,注意力应该更集中于《终结者》而不是《泰坦尼克号》
语义层次的注意力旨在学习每种元路径的重要性,并给它们赋予适当的注意力权重
例如,《终结者2》是《终结者》基于元路径MAM的邻居(都由施瓦辛格主演),而《鸟人》是《终结者》基于元路径MYM的邻居(都拍摄于1984年);如果要识别《终结者》的类型,MAM比MYM起更重要的作用 也就是说,将不同的元路径同等对待会削弱异构图中的语义信息
该论文的主要贡献如下:
- 首次将注意力机制应用于异构图神经网络
- 提出了HAN模型,同时考虑了顶点层次的注意力和语义层次的注意力
- 通过实验证明提出的模型优于SOTA模型,另外对于异构图分析有较好的可解释性
2.相关工作
- GNN
- 网络嵌入
3.预备知识
- 异构图:G=(V, E),顶点和边有多种类型 例如图1是一个包含演员、电影、导演三种顶点以及“演员-出演-电影”和“导演-执导-电影”两种边的异构图
- 元路径:两个顶点之间的综合关系(composite relation),即两个顶点之间经过特定类型顶点的连接关系 \(A_1 \xrightarrow{R_1} A_2 \xrightarrow{R_2} \cdots \xrightarrow{R_l} A_{l+1}\) (上面提到的元路径MAM和MDM都是l=2) 例如在图1中,“电影-演员-电影”(MAM)是一种元路径,表示“同一个演员出演的两部电影”,实例有m1-a1-m2, m1-a3-m3, m2-a2-m3, m1-a1-m1等;电影-导演-电影”(MDM)是另一种元路径,含义是“同一个导演执导的两部电影”
- 基于元路径的邻居:给定一个顶点i和元路径Φ,顶点i的基于元路径Φ的邻居 $N_i^\Phi$ 定义为通过元路径Φ与顶点i相连的顶点集合,包括顶点i本身 在图1的例子中,m1基于元路径MAM的邻居集合为 $N_{m_1}^{MAM}=\lbrace m_1,m_2,m_3\rbrace$,基于元路径MDM的邻居集合为 $N_{m_1}^{MDM}=\lbrace m_1,m_2\rbrace$ 基于元路径的邻居异构图中多种结构信息和丰富的语义信息 可以通过邻接矩阵序列相乘的方式得到基于元路径的邻居
4.HAN模型
HAN是用于异构图的半监督GNN模型 层级注意力结构:顶点层次的注意力→语义层次的注意力
模型结构如下:
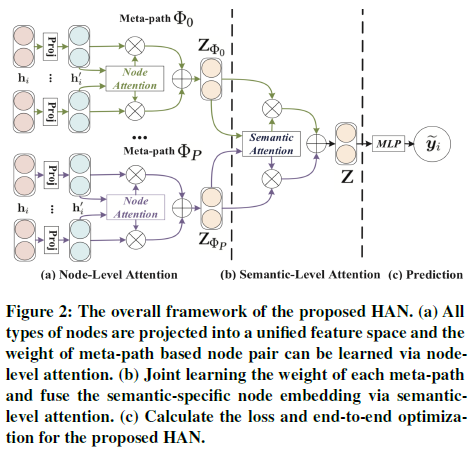
- 首先使用顶点层次的注意力来学习基于元路径的邻居的注意力权重,并将它们聚集起来得到语义相关的顶点嵌入(元路径=语义)
- 之后通过语义层次的注意力来学习不同元路径的注意力权重,并将上一步得到的语义相关的顶点嵌入组合起来得到最终的顶点嵌入,用于特定的任务
4.1 顶点层次的注意力
基于不同元路径的邻居对学习顶点嵌入有不同的影响,即重要性不同,因此引入顶点层次的注意力来学习基于元路径的邻居的重要性,并将它们聚集起来得到一个顶点嵌入
首先,由于不同的类型的顶点有不同的特征空间,因此通过一个类型相关的转换矩阵将不同类型的顶点特征映射到相同的特征空间

其中 $h_i$ 是顶点i的原始特征, $h_i’$ 是映射后的特征,$\phi_i$ 是顶点i的类型
之后,使用自注意力来学习不同邻居的重要性
给定通过元路径Φ连接的顶点对(i, j)(即j是i的基于元路径Φ的邻居),令 $e_{ij}^\Phi$ 表示顶点j对顶点i的重要性,定义为
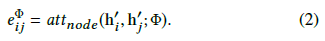
其中attnode表示计算顶点层次注意力的深度神经网络(具体结构见公式(3))
给定元路径Φ, ${att}_{node}$ 对所有基于元路径Φ的顶点对是共享的
注意 $e_{ij}^\Phi$ 是不对称的,即j对i的重要性和i对j的重要性可以不同,因此顶点层次的注意力保留了异构图的不对称性
对 $e_{ij}^\Phi$ 归一化即可得到基于元路径的邻居的权重参数 $\alpha_{ij}^\Phi$
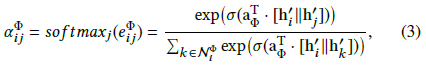
(和HetGNN的注意力公式一样!都来自GAT)
(由此推断, ${att}_{node}$ 的具体形式就是 $\sigma(a_\Phi^T [h_i^′ \Vert h_j^′])$ )
其中σ是激活函数,||表示向量拼接, $a_\Phi$ 是元路径Φ的顶点层次的注意力向量(可学习参数)
使用 $\alpha_{ij}^\Phi$ 对邻居的映射后的特征加权即可顶点i的基于元路径Φ的嵌入:
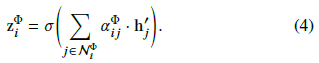
这一步就是聚集操作
由于 $\alpha_{ij}^\Phi$ 是和元路径Φ相关的,因此可以捕获元路径Φ所表示的语义信息,基于元路径的嵌入也叫语义相关的嵌入
论文中还将顶点层次的注意力扩展到多头注意力,即将(4)式重复K次并将向量拼接起来:
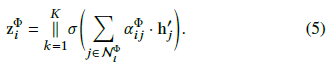
根据以上过程,可以计算出每个顶点基于每个元路径的嵌入表示 论文中给出了一张图来解释计算过程
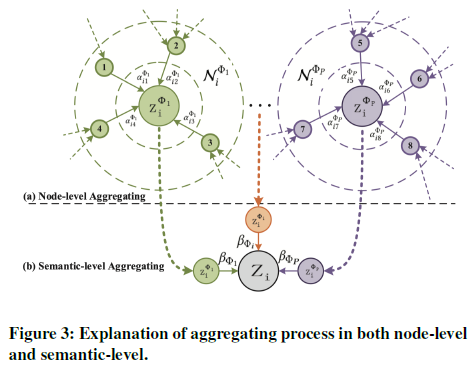
虚线以上对应顶点层次的注意力,每个大圈表示针对一种元路径,通过聚集邻居的特征得到顶点i基于元路径的嵌入的过程
虚线以下对应语义层次的注意力,即对顶点i基于每种元路径的嵌入加权得到最终嵌入
4.2 语义层次的注意力
在异构图中,每个顶点有多种元路径(例如“电影”顶点有MAM和MDM两种元路径),因此包含多种语义信息,而4.1节中基于元路径的嵌入只能反映一种语义信息
因此论文中提出了语义层次的注意力来学习不同元路径的重要性,从而将每个顶点基于不同元路径的嵌入融合为一个嵌入
设 $Z_{\Phi_p}$ 为基于元路径 $\Phi_p$ 的顶点嵌入, $\beta_{\Phi_p}$ 为元路径 $\Phi_p$ 的注意力权重
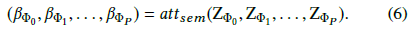
其中 ${att}_{sem}$ 表示计算语义层次注意力的深度神经网络,具体计算方法如下
首先通过一个全连接层将上一步得到的基于元路径的嵌入(语义相关的嵌入)进行转换,使用转换后的嵌入与语义层次的注意力向量q(可学习参数)的相似度来表示每个元路径的重要性 $w_{\Phi_p}$
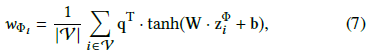
(公式右边的i表示顶点,左边的i应该是元路径的编号p,z的上标应该是 $\Phi_p$ ,和w的下标对应)
其中的参数对所有的元路径是共享的
对 $w_{\Phi_p}$ 归一化即可得到元路径的权重参数 $\beta_{\Phi_p}$
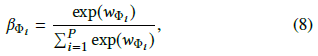
$\beta_{\Phi_p}$ 表达了一个元路径在特定任务中的重要性,一个元路径对于不同任务的权重可能不同
使用 $\beta_{\Phi_p}$ 对基于元路径的嵌入加权即可得到最终的顶点嵌入
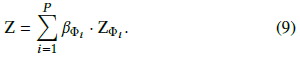
这一步对应图3(b)
4.3 模型分析
- 可以处理不同类型的顶点和边并融合异构图丰富的语义信息
- 计算高效,可并行化
- 注意力参数共享,因此参数数量不随图的规模变化
- 学习到的顶点嵌入可解释性好
5.实验
5.1 数据集
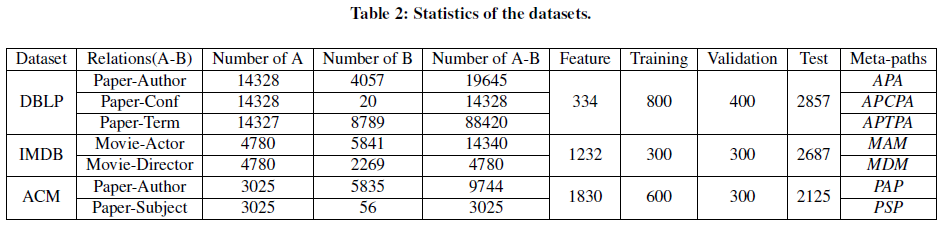
- DBLP:包含论文( P)、学者(A)、会议( C)、关键词(T)四种顶点,学者分为数据库、数据挖掘、机器学习、信息检索四个领域,根据学者发表过论文的会议标注学者的研究领域,学者顶点的输入特征是其关键词的词袋表示,元路径包括APA, APCPA, APTPA
- ACM:包含论文( P)、学者(A)、主题(S)三种顶点,论文分为数据库、无线通信、数据挖掘三类,根据论文所属的会议标注论文标签,论文顶点的输入特征是其关键词的词袋表示,元路径包括PAP和PSP
- IMDB:包含电影(M)、演员(A)、导演(D)三种顶点,电影分为动作、喜剧、话剧三类,电影顶点的输入特征是其剧情的词袋表示,元路径包括MAM, MDM
阅读代码后注:
- 注意到每个数据集选择的所有元路径的起点和终点都是相同的类型,因此在代码中分别构造该类型的顶点基于每种元路径的邻居的同构图(可使用
dgl.metapath_reachable_graph()函数),对每个同构图使用独立的GAT模型学习顶点嵌入,最后使用语义层次的注意力将这些嵌入组合起来,因此HAN和GAT的区别就是增加了语义层次的注意力(顶点层次的注意力和GAT完全一样),而且每个数据集只学习了一种类型的顶点嵌入 - 所谓顶点分类和聚类两个任务其实只有评价指标不同,模型输出的顶点嵌入和损失函数都一样,区别只在于如何由顶点嵌入及标签计算评价指标
5.2 Baseline
用于比较的SOTA baseline包括(异构)网络嵌入方法和基于GNN的方法
- DeepWalk:基于随机游走的网络嵌入方法(用于同构图)
- ESim:异构图嵌入方法,从多个元路径捕获语义信息
- metapath2vec:异构图嵌入方法,使用基于元路径的随机游走,使用skip-gram做嵌入
- HERec:异构图嵌入方法,设计了一个类型限制策略来过滤顶点序列,使用skip-gram做嵌入
- GCN:半监督的图卷积网络,用于同构图
- GAT:半监督的神经网络,在同构图上使用注意力机制
- HAN_nd:HAN的变体,移除了顶点层次的注意力,给每个邻居赋予相同的权重
- HAN_sem:HAN的变体,移除了语义层次的注意力,给每个元路径赋予相同的权重
(与最后两个变体的比较实际上是消融实验)
5.3 实现细节
优化器Adam,学习率0.005,正则项参数0.001
语义层次的注意力向量q的维数128
注意力头数K=8,dropout=0.6
嵌入维数为64(即每个注意力头的嵌入维数为8)
代码:https://github.com/Jhy1993/HAN
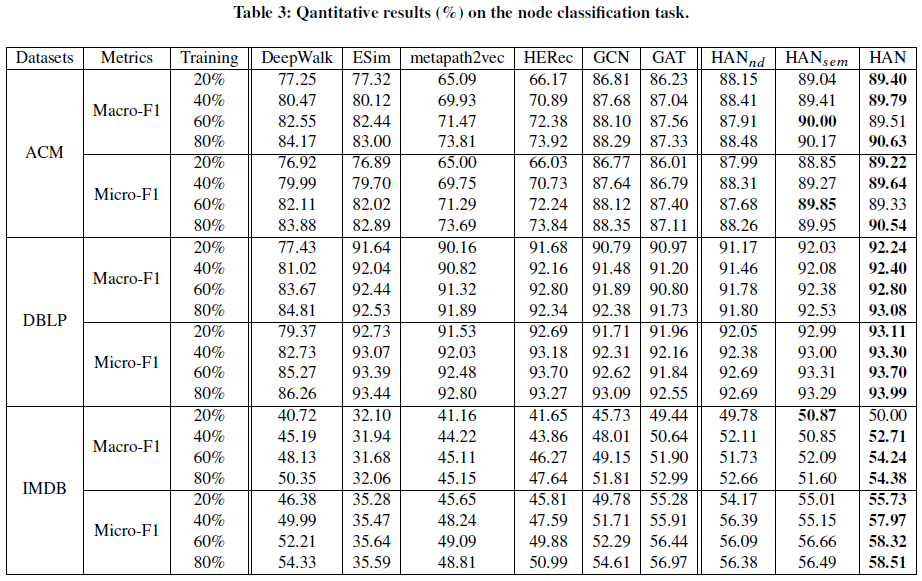
5.4 分类
使用k=5的KNN分类器进行顶点分类,运行10次取平均的Macro-F1和Micro-F1
(实际上代码中用的根本不是KNN,就是一个全连接层?)
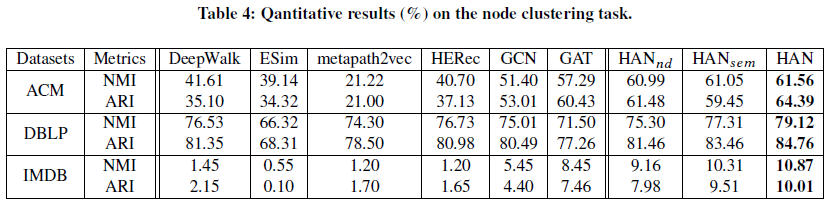
5.5 聚类
使用KMeans方法进行顶点聚类,K设置为类别个数,ground truth与顶点分类任务相同,使用NMI和ARI来评价聚类结果(和HetGNN一样),运行10次取平均结果
5.6 层级注意力机制分析

图4显示(论文)P831注意力权重最高的邻居是P699和P133,这两篇论文所属的类别和P831相同,证明顶点层次的注意力有效
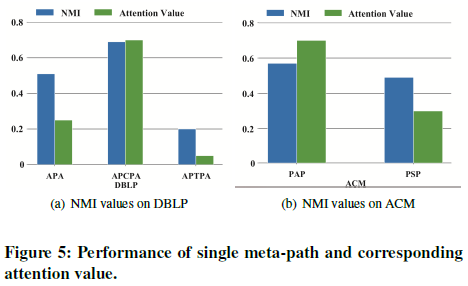
图5显示在DBLP数据集上,HAN赋予元路径APCPA最高的权重,因为元路径APCPA比APA在区分学者的研究领域上更有意义
5.7 可视化
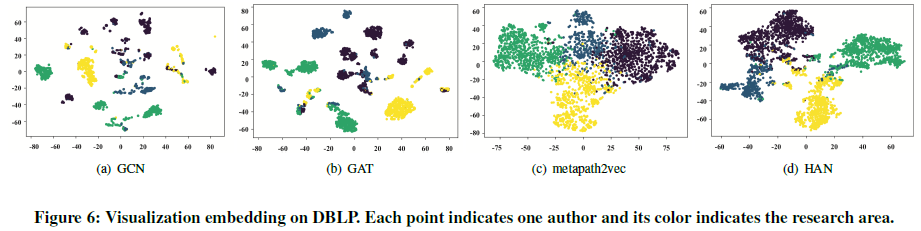
5.8 参数实验
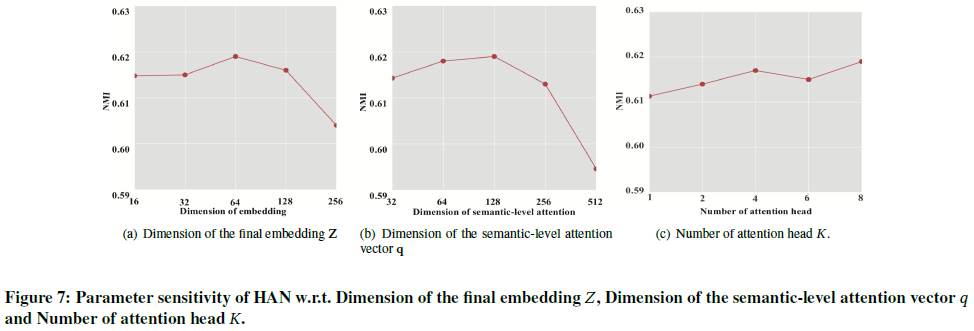
论文中分析了三个超参数对模型性能的影响
- 最终嵌入Z的维数
- 语义层次注意力向量q的维数
- 注意力头数K
6.结论
该论文提出了基于注意力机制的半监督异构图神经网络模型HAN
HAN可以捕获异构图复杂的结构信息和丰富的语义信息
HAN分别利用顶点层次的注意力和语义层次的注意力来学习顶点和元路径的重要性
分类和聚类的实验结果证明了HAN的有效性和可解释性