JanusGraph使用教程
1.简介
基本概念:
- TinkerPop: Apache的图计算框架,可以理解为图数据库的抽象层
- Gremlin: TinkerPop图遍历(traverse)语言,相当于关系数据库的SQL
- JanusGraph:基于TinkerPop框架的图数据库之一(TinkerPop主页上有更多)
2.下载和安装
TinkerPop首页上有Gremlin Console和Gremlin Server的下载链接,二者区别:前者是一个单机的内存版本,可以进行学习测试;后者是生产环境部署需要使用的版本。
JanusGraph:https://github.com/JanusGraph/janusgraph/releases,大致相当于Gremlin Console+Gremlin Server,但预安装和加载了JanusGraph包,后面将基于此进行说明。
安装JanusGraph之前需要安装Java 8并设置JAVA_HOME环境变量。
以0.5.2版本为例,下载https://github.com/JanusGraph/janusgraph/releases/download/v0.5.2/janusgraph-0.5.2.zip,下载完成后解压即可
1
unzip janusgraph-0.5.2.zip
2.1 运行Gremlin客户端
运行bin目录下的gremlin.bat(Windows)或gremlin.sh(Linux)进入Gremlin控制台
1
./bin/gremlin.sh
- 若遇到报错Exception in thread “main” java.awt.AWTError: Assistive Technology not found: org.GNOME.Accessibility.AtkWrapper,则将/etc/java-8-openjdk/accessibility.properties文件中的assistive_technologies=org.GNOME.Accessibility.AtkWrapper注释掉。
- 在Windows下运行时会提示 “HADOOP_HOME is not set.” ,需要下载https://public-repo-1.hortonworks.com/hdp-win-alpha/winutils.exe并将其放在gremlin.bat同一目录下。
- 参考:https://www.cnblogs.com/rudy123/archive/2018/11/22/10000395.html
Gremlin控制台使用的语言是Groovy。Groovy是Java的语言扩展,因此可以使用任何Java语法。另外Groovy还提供了一些扩展功能,例如像Python一样通过字面量创建列表和映射的语法(注意创建映射时外面是[]不是{})。Linux系统下在Gremlin控制台中也可以按Tab键列出代码补全提示。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
gremlin> 100-10
==>90
gremlin> "Hello, " + "world!"
==>Hello, world!
gremlin> a = [name:'aurelius', vocation:['philosopher', 'emperor']]
==>name=aurelius
==>vocation=[philosopher, emperor]
gremlin> a.getClass()
==>class java.util.LinkedHashMap
gremlin> a.get("vocation")
==>philosopher
==>emperor
gremlin> new Random().nextInt(100)
==>68
gremlin> "a = ${a}"
==>a = [name:aurelius, vocation:[philosopher, emperor]]
通过Gremlin控制台可以在本地进行图数据库操作,见“Gremlin增删改查”。
显示帮助——:help,退出——:exit或:quit
2.2 运行Gremlin服务器
运行bin目录下的gremlin-server.bat(Windows)或gremlin-server.sh(Linux),并传递一个yaml配置文件作为参数
1
./bin/gremlin.sh conf/gremlin-server/gremlin-server.yaml
conf/gremlin-server目录下有一些示例配置文件,详见https://docs.janusgraph.org/basics/configuration/#janusgraph-server。
- 默认配置使用内存存储后端,不使用索引后端,若要使用其他存储后端和索引后端,见“存储后端”和“索引后端”。
- 在一台机器上启动Gremlin服务后,其他机器即可远程连接到该服务器,见“连接远程Gremlin服务器”
- 官方文档:https://docs.janusgraph.org/basics/server/
2.3 在Docker容器中安装
3.Gremlin增删改查
Gremlin是用于遍历图的节点和边进行查询的语言
- Apache官方教程(后面的示例均参考该教程):
- TinkerPop参考文档:http://tinkerpop.apache.org/docs/current/reference/
- SQL与Gremlin的对比:http://sql2gremlin.com/
3.1 简单示例
创建如下内置的示例图数据库(toy graph)
1
2
3
4
gremlin> graph = TinkerFactory.createModern()
==>tinkergraph[vertices:6 edges:6]
gremlin> g = graph.traversal()
==>graphtraversalsource[tinkergraph[vertices:6 edges:6], standard]
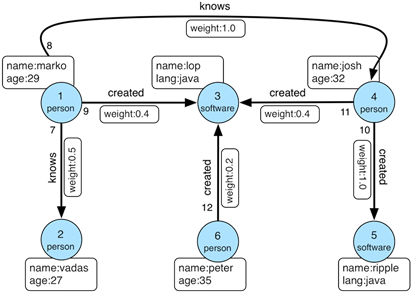
- 第一个命令使用
TinkerFactory工厂类创建了一个Graph类对象graph,表示包含数据的图;第二个命令从graph获取了用于遍历它的GraphTraversalSource类对象g,所有的遍历查询均从g开始。 TinkerFactory类的其他方法createClassic(),createKitchenSink(),createTheCrew()可创建其他的“玩具图”
简单查询
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
gremlin> g.V()
==>v[1]
==>v[2]
==>v[3]
==>v[4]
==>v[5]
==>v[6]
gremlin> g.V(1)
==>v[1]
gremlin> g.V(1).values('name')
==>marko
gremlin> g.V(1).outE('knows')
==>e[7][1-knows->2]
==>e[8][1-knows->4]
gremlin> g.V(1).outE('knows').inV().values('name')
==>vadas
==>josh
gremlin> g.V(1).out('knows').values('name')
==>vadas
==>josh
gremlin> g.V(1).out('knows').has('age', gt(30)).values('name')
==>josh
g.V():获得所有顶点g.V(1):获得id为1的顶点g.V(1).values('name'):获得id为1的顶点的name属性g.V(1).outE('knows'):获得id为1的顶点的knows标签的出边g.V(1).outE('knows').inV().values('name'):获得id为1的顶点的knows标签的出边所指向顶点的name属性outE().inV()可简写为out(),inE().outV()可简写为in()g.V(1).out('knows').has('age', gt(30)).values('name'):获得id为1的顶点的knows标签的出边所指向的age属性大于30的顶点的name属性(gt(30)返回一个谓词对象,具体类型可通过gt(30).getClass()查看)
注意:这些中间步骤的返回结果实际上均为GraphTraversal对象,本质上是一个迭代器,本身不包含查询结果,必须对其进行迭代才能得到结果。Gremlin console自动对其迭代并打印出了结果,但在代码中必须手动迭代!
3.2 图数据库的结构
图(graph)是一组顶点(vertex)和边(edge)的集合,顶点表示实体,边表示关系(有向)
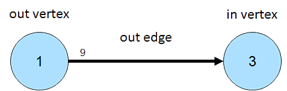
顶点和边都有唯一的id、用于表示种类的标签(label)以及任意多的属性(property)
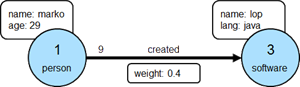
3.3 创建图、添加顶点和边
(1)使用TinkerGraph工厂类
1
2
3
4
5
6
7
8
9
10
gremlin> graph = TinkerGraph.open()
==>tinkergraph[vertices:0 edges:0]
gremlin> g = graph.traversal()
==>graphtraversalsource[tinkergraph[vertices:0 edges:0], standard]
gremlin> v1 = g.addV("person").property(id, 1).property("name", "marko").property("age", 29).next()
==>v[1]
gremlin> v2 = g.addV("software").property(id, 3).property("name", "lop").property("lang", "java").next()
==>v[3]
gremlin> g.addE("created").from(v1).to(v2).property(id, 9).property("weight", 0.4)
==>e[9][1-created->3]
注意:TinkerGraph图数据库允许给id赋值,但其他大部分图数据库不允许,id是自动生成的;property(id, 1)中的id实际上是枚举org.apache.tinkerpop.gremlin.structure.T的成员,在Gremlin Console中已被自动静态导入。
(2)使用JanusGraphFactory工厂类
1
2
graph = JanusGraphFactory.open('conf/janusgraph-xxx.properties')
g = graph.traversal()
在conf目录下有一些示例配置文件可以直接使用
- https://docs.janusgraph.org/getting-started/basic-usage/
- https://docs.janusgraph.org/basics/configuration/#janusgraphfactory
3.4 Gremlin查询语法
图数据库的查询本质上是对图进行遍历(traversal),遍历由一系列步骤(step)组成。step是GraphTraversal对象的方法,返回的还是GraphTraversal对象,因此可以链式调用。
(1)从GraphTraversalSource(即上面的g)到GraphTraversal
V():获得所有顶点
V(id):获得指定id的顶点
E():获得所有边
E(id):获得指定id的边
(2) 常用的step
注:更多用法见“更多的step”,完整列表http://tinkerpop.apache.org/docs/current/reference/#graph-traversal-steps)
has(key, value), has(label, key, value):根据标签和属性值过滤顶点或边,value可以是简单值(如30)或谓词(如gt(30))
- 常用谓词:
eq(x),neq(x),gt(x),lt(x),between(x, y),within(x1, x2,...) - 逻辑运算符:
gt(a).and(lt(b))等价于and(gt(a), lt(b))
hasLabel(label), hasId(id), hasKey(key), hasValue(value), has(key), hasNot(key)
hasLabel(label):根据标签过滤顶点或边
outE(), outE(label):将顶点映射到(带有label)的出边(边是有向的!)
inE(), inE(label):将顶点映射到(带有label)的入边
bothE(), bothE(label):将顶点映射到(带有label)的入边和出边
inV():将边映射到其指向的顶点
outV():将边映射到其出发的顶点
bothV():将边映射到其出发和指向的顶点
out(label)=outE(label).inV(), in(label)=inE(label).outV(), both(label)=bothE(label).bothV()
values(key):将顶点或边映射到其属性值
valueMap():将每个顶点或边映射到一个“属性键->值”的映射
count(), sum(), mean(), max(), min():对结果中的元素计数、求和、求平均值、求最大值、求最小值
as(stepLabel):给前一个步骤的结果(可能是顶点、边或属性等)命名(步骤标签)以便后续使用
where(predicate):使用谓词过滤传入的对象
- 例如:删除id为1和2的顶点之间的边
1
g.V(1).bothE().where(otherV().hasId(2)).drop().iterate()
and(), or(), not():逻辑运算
- 例如:
1
2
g.V().or(__.outE('created'), __.inE('created').count().is(gt(1))).
values('name')
next():取得结果中的第一个对象
limit(n):过滤结果,仅保留前n个对象
iterate():遍历结果中的对象,但不返回任何结果,只有当前面的步骤有“副作用”(例如用drop()删除顶点或边)时才有用
drop():从图中删除边或节点
- 注意:在控制台中执行
g.V().has('name', 'marko').drop()能直接删除name属性为marko的顶点,是因为控制台自动对返回的GraphTraversal对象进行了迭代。在代码中一定要在最后调用iterate(),否则drop()不起作用!!
1
2
3
public static void removeByName(GraphTraversalSource g, String name) {
g.V().has("name", name).drop().iterate();
}
properties(keys...):将每个顶点或边映射到其属性对象(Property类型的对象),返回的结果是将每个元素的属性对象“连接”成的列表,而不是每个元素分别映射到一个列表
properties():将每个顶点或边映射到其所有属性对象
propertyMap():将每个顶点或边映射到一个“属性键->属性对象”的映射
- 顶点的属性实际上是VertexProperty类型,一个属性名称可以对应多个值,并且属性本身还可以包含属性(元属性,meta-property)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
gremlin> graph = TinkerFactory.createTheCrew()
==>tinkergraph[vertices:6 edges:14]
gremlin> g = graph.traversal()
==>graphtraversalsource[tinkergraph[vertices:6 edges:14], standard]
gremlin> g.V(1).properties('location')
==>vp[location->san diego]
==>vp[location->santa cruz]
==>vp[location->brussels]
==>vp[location->santa fe]
gremlin> p = g.V(1).properties('location').next()
==>vp[location->san diego]
gremlin> p.key()
==>location
gremlin> p.value()
==>san diego
gremlin> p.properties()
==>p[startTime->1997]
==>p[endTime->2001]
properties()与values()的区别:values()仅返回属性的值,而properties()返回一个Property类型的对象
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
gremlin> graph = TinkerFactory.createModern()
==>tinkergraph[vertices:6 edges:6]
gremlin> g = graph.traversal()
==>graphtraversalsource[tinkergraph[vertices:6 edges:6], standard]
gremlin> g.V(1).values()
==>marko
==>29
gremlin> g.V(1).properties()
==>vp[name->marko]
==>vp[age->29]
gremlin> g.V(1).values('name')
==>marko
gremlin> g.V(1).properties('name')
==>vp[name->marko]
gremlin> g.V(1).values('name').next().getClass()
==>class java.lang.String
gremlin> g.V(1).properties('name').next().getClass()
==>class org.apache.tinkerpop.gremlin.tinkergraph.structure.TinkerVertexProperty
gremlin> g.V(1,2).values()
==>marko
==>29
==>vadas
==>27
gremlin> g.V(1,2).properties()
==>vp[name->marko]
==>vp[age->29]
==>vp[name->vadas]
==>vp[age->27]
gremlin> g.V(1,2).valueMap()
==>[name:[marko],age:[29]]
==>[name:[vadas],age:[27]]
gremlin> g.V(1,2).propertyMap()
==>[name:[vp[name->marko]],age:[vp[age->29]]]
==>[name:[vp[name->vadas]],age:[vp[age->27]]]
GraphTraversal接口实际有两个类型参数:GraphTraversal<S, E>,S表示步骤的传入类型对象,E表示步骤的传出类型对象,这两个参数限制了对每一步的结果可以执行的后序步骤,即后一步的S必须与前一步的E相同。例如:g.E()返回的是GraphTraversal<Edge, Edge>,就不能对其调用outE(),因为该步骤返回GraphTraversal<Vertex, Edge>。
3.5 Gremlin增删改语法
注意:任何产生副作用的遍历过程必须通过next()或iterate() 手动迭代才能生效!控制台会对遍历结果自动迭代,因此不调用也能生效。
(1)从GraphTraversalSource(即g)开始
addV(label):添加一个顶点,结果中包含新添加的顶点
- 可通过以下方式获取新添加顶点的id:
1
g.addV('person').property('name', 'ZZy').property('age', 22).next().id()
addE(label):添加一个边(后边必须通过from()和to()指定出顶点和入顶点)
(2)在GraphTraversal遍历过程中
addV(label):添加一个顶点
addE(label):添加一个边(后边必须通过from()和to()指定出顶点和入顶点,若当前步骤的结果是顶点则可仅指定from()或to())
property(key, value):设置属性值(可用于添加或修改)
from(vertex), from(stepLabel):指定新添加边的出顶点
to(vertex), to(stepLabel):指定新添加边的入顶点
drop():删除顶点或边及其属性
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
gremlin> graph = TinkerGraph.open()
==>tinkergraph[vertices:0 edges:0]
gremlin> g = graph.traversal()
==>graphtraversalsource[tinkergraph[vertices:0 edges:0], standard]
gremlin> v1 = g.addV("person").property(id, 1).property("name", "marko").property("age", 29).next()
==>v[1]
gremlin> v2 = g.addV("software").property(id, 3).property("name", "lop").property("lang", "java").next()
==>v[3]
gremlin> g.addE("created").from(v1).to(v2).property(id, 9).property("weight", 0.4)
==>e[9][1-created->3]
gremlin> g.V(1).valueMap()
==>[name:[marko],age:[29]]
gremlin> g.V(1).property('age', 30)
==>v[1]
gremlin> g.V(1).valueMap()
==>[name:[marko],age:[30]]
gremlin> g.V(1).outE().drop()
gremlin> g.E()
gremlin> g.V(1).valueMap()
==>[name:[marko],age:[30]]
gremlin> g.V(1).properties('name').drop()
gremlin> g.V(1).valueMap()
==>[age:[30]]
gremlin> g.V().has('name', 'lop').drop()
gremlin> g.V()
==>v[1]
from()和to()的参数也可以是通过as()指定的别名:
1
2
gremlin> g.V(3).as('a').V(1).addE("created").to('a').property(id, 9).property("weight", 0.4)
==>e[9][1-created->3]
3.6 更多的step
path():将结果中的每个顶点或边映射到其走过的路径
select(labels...):将每条路径映射到一个“标签->顶点”的映射(这里的“标签”是指通过as()指定的别名),见下例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
gremlin> graph = TinkerFactory.createModern()
==>tinkergraph[vertices:6 edges:6]
gremlin> g = graph.traversal()
==>graphtraversalsource[tinkergraph[vertices:6 edges:6], standard]
gremlin> g.V().out()
==>v[3]
==>v[2]
==>v[4]
==>v[5]
==>v[3]
==>v[3]
gremlin> g.V().out().out()
==>v[5]
==>v[3]
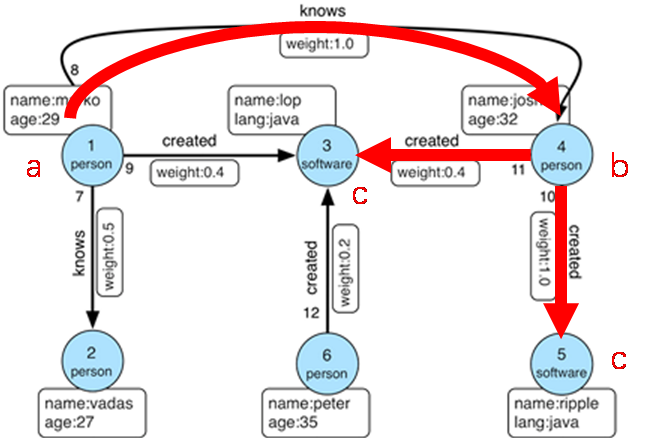
gremlin> g.V().as('a').out().as('b').out().as('c').path()
==>[v[1],v[4],v[5]]
==>[v[1],v[4],v[3]]
gremlin> g.V().as('a').out().as('b').out().as('c').select('a','b','c')
==>[a:v[1],b:v[4],c:v[5]]
==>[a:v[1],b:v[4],c:v[3]]
- 从所有顶点开始,沿出边遍历两次,只有1-4-3和1-4-5两条路径
- 注意:若要将顶点替换为其属性值则应使用
by()而不是values():
1
2
3
4
5
6
gremlin> g.V().as('a').out().as('b').out().as('c').select('a','b','c').by('name')
==>[a:marko,b:josh,c:ripple]
==>[a:marko,b:josh,c:lop]
gremlin> g.V().as('a').out().as('b').out().as('c').select('a','b','c').by(valueMap())
==>[a:[name:[marko],age:[29]],b:[name:[josh],age:[32]],c:[name:[ripple],lang:[java]]]
==>[a:[name:[marko],age:[29]],b:[name:[josh],age:[32]],c:[name:[lop],lang:[java]]]
group(), by(token), by(key):分组
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
gremlin> graph = TinkerFactory.createModern()
==>tinkergraph[vertices:6 edges:6]
gremlin> g = graph.traversal()
==>graphtraversalsource[tinkergraph[vertices:6 edges:6], standard]
gremlin> g.V().group().by(label)
==>[software:[v[3],v[5]],person:[v[1],v[2],v[4],v[6]]]
gremlin> g.V().group().by(label).by('name')
==>[software:[lop,ripple],person:[marko,vadas,josh,peter]]
gremlin> g.V(1).outE()
==>e[9][1-created->3]
==>e[7][1-knows->2]
==>e[8][1-knows->4]
gremlin> g.V(1).outE().group().by(label).by(inV())
==>[created:v[3],knows:v[4]]
gremlin> g.E()
==>e[7][1-knows->2]
==>e[8][1-knows->4]
==>e[9][1-created->3]
==>e[10][4-created->5]
==>e[11][4-created->3]
==>e[12][6-created->3]
gremlin> g.E().group().by(outV()).by(id)
==>[v[1]:[7,8,9],v[4]:[10,11],v[6]:[12]]
gremlin> g.E().group().by(outV()).by(count())
==>[v[1]:3,v[4]:2,v[6]:1]
label也是枚举org.apache.tinkerpop.gremlin.structure.T的成员- 最后一个
inV()实际上是org.apache.tinkerpop.gremlin.process.traversal.dsl.graph.__类的静态方法 - 注意:顶点v[1]通过knows标签的出边指向的顶点有v[2]和v[4]两个,但根据出边的标签分组再通过
by(inV())映射到指向的顶点后knows仅对应一个v[4]。这是因为控制台没有对内层的遍历进行迭代,而仅调用next()获取了结果中的一个顶点。要获得完整的结果需要借助fold(),见下。
fold():将结果收集到一个列表中(返回的结果仅包含一个列表对象)
1
2
3
4
5
6
7
8
9
10
11
12
gremlin> graph = TinkerFactory.createModern()
==>tinkergraph[vertices:6 edges:6]
gremlin> g = graph.traversal()
==>graphtraversalsource[tinkergraph[vertices:6 edges:6], standard]
gremlin> g.V(1).out('knows')
==>v[2]
==>v[4]
gremlin> g.V(1).out('knows').fold()
==>[v[2],v[4]]
gremlin> g.V(1).outE().group().by(label).by(inV().fold()).next()
==>created=[v[3]]
==>knows=[v[2], v[4]]
order():排序
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
gremlin> graph = TinkerFactory.createModern()
==>tinkergraph[vertices:6 edges:6]
gremlin> g = graph.traversal()
==>graphtraversalsource[tinkergraph[vertices:6 edges:6], standard]
gremlin> g.E().hasLabel('created')
==>e[9][1-created->3]
==>e[10][4-created->5]
==>e[11][4-created->3]
==>e[12][6-created->3]
gremlin> g.V().hasLabel('person').order().by(outE('created').count(), incr)
==>v[2]
==>v[1]
==>v[6]
==>v[4]
gremlin> g.V().hasLabel('person').
......1> order().by(outE('created').count(), incr).
......2> order().by('name', decr).values('name')
==>vadas
==>peter
==>marko
==>josh
local():对上一步结果中的每一个对象执行括号内的遍历过程,而不是对所有对象整体
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
gremlin> graph = TinkerFactory.createTheCrew()
==>tinkergraph[vertices:6 edges:14]
gremlin> g = graph.traversal()
==>graphtraversalsource[tinkergraph[vertices:6 edges:14], standard]
gremlin> g.V().hasLabel('person').as('person').
......1> properties('location').as('location').
......2> select('person','location').by('name').by(valueMap())
==>[person:marko,location:[startTime:1997,endTime:2001]]
==>[person:marko,location:[startTime:2001,endTime:2004]]
==>[person:marko,location:[startTime:2004,endTime:2005]]
==>[person:marko,location:[startTime:2005]]
==>[person:stephen,location:[startTime:1990,endTime:2000]]
==>[person:stephen,location:[startTime:2000,endTime:2006]]
==>[person:stephen,location:[startTime:2006]]
==>[person:matthias,location:[startTime:2004,endTime:2007]]
==>[person:matthias,location:[startTime:2007,endTime:2011]]
==>[person:matthias,location:[startTime:2011,endTime:2014]]
==>[person:matthias,location:[startTime:2014]]
==>[person:daniel,location:[startTime:1982,endTime:2005]]
==>[person:daniel,location:[startTime:2005,endTime:2009]]
==>[person:daniel,location:[startTime:2009]]
gremlin> g.V().hasLabel('person').
......1> properties('location').values('startTime').min()
==>1982
gremlin> g.V().hasLabel('person').
......1> local(properties('location').values('startTime').min())
==>1997
==>1990
==>2004
==>1982
倒数第二个命令将所有人的所有location属性(每个人有多个)的startTime元属性放在一起求最小值,而最后一个命令分别对每一个人(g.V().hasLabel('person')的结果)的所有location属性的startTime元属性求最小值
filter():使用自定义的谓词过滤结果
- 注意:谓词的类型是
java.util.function.Predicate<Traverser<E>>,E表示结果对象的类型(Vertex,Edge,Property等),使用Traverser.get()方法获取结果对象
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
gremlin> graph = TinkerFactory.createModern()
==>tinkergraph[vertices:6 edges:6]
gremlin> g = graph.traversal()
==>graphtraversalsource[tinkergraph[vertices:6 edges:6], standard]
gremlin> g.V().hasLabel('person')
==>v[1]
==>v[2]
==>v[4]
==>v[6]
gremlin> g.V().hasLabel('person').valueMap()
==>[name:[marko],age:[29]]
==>[name:[vadas],age:[27]]
==>[name:[josh],age:[32]]
==>[name:[peter],age:[35]]
gremlin> g.V().hasLabel('person').filter {it.get().value('age') < 30}
==>v[1]
==>v[2]
这里filter后的{}是Groovy闭包的语法,在代码中可以使用Java的Lambda表达式:
1
g.V().hasLabel("person").filter(it -> it.get().value("age") < 30)
dedup():去重
4.连接远程Gremlin服务器
在Gremlin Console中创建的图数据库保存在内存中,退出后就丢失了。若要将数据保存到磁盘则需要Gremlin服务器,运行下载的Gremlin Server或JanusGraph解压后bin文件夹下的gremlin-server.bat或gremlin-server.sh,之后便可通过8182端口(默认)连接该主机上的Gremlin服务器。
4.1 使用Gremlin Console连接Gremlin服务器
配置文件:conf/remote.yaml,将其中的hosts改为远程服务器的IP地址,其他保持默认

在Gremlin控制台中通过以下命令连接到远程Gremlin服务器:
1
2
:remote connect tinkerpop.server conf/remote.yaml
:remote console
之后输入的所有命令将会被发送到远程Gremlin服务器,并且可直接使用graph和g两个变量
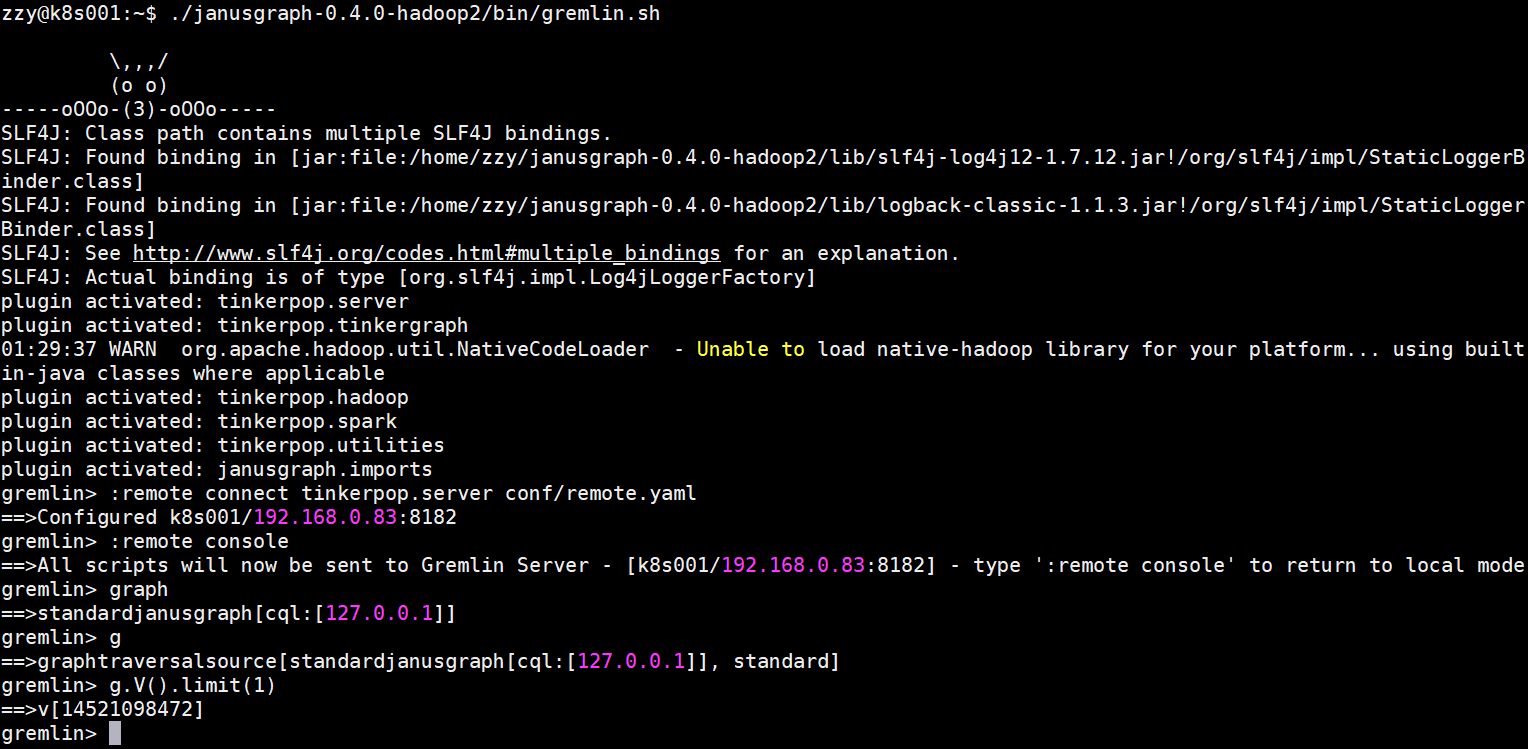
注意:连接远程Gremlin服务器后Gremlin Console会失去为变量赋值的功能,即使给变量赋值,再次使用该变量时会报错:No such property: xxx for class: Scriptxxx
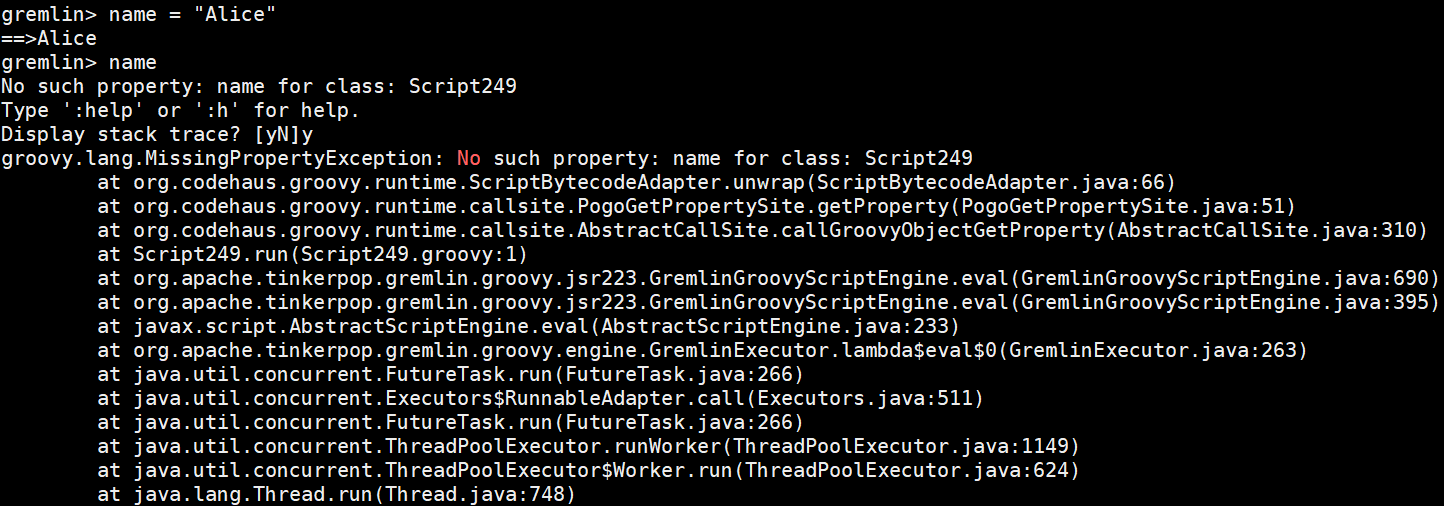
在网上查了很久都没有查到解决方法,后来终于在官方文档JanusGraph服务器的一个示例中找到对这个问题的说明
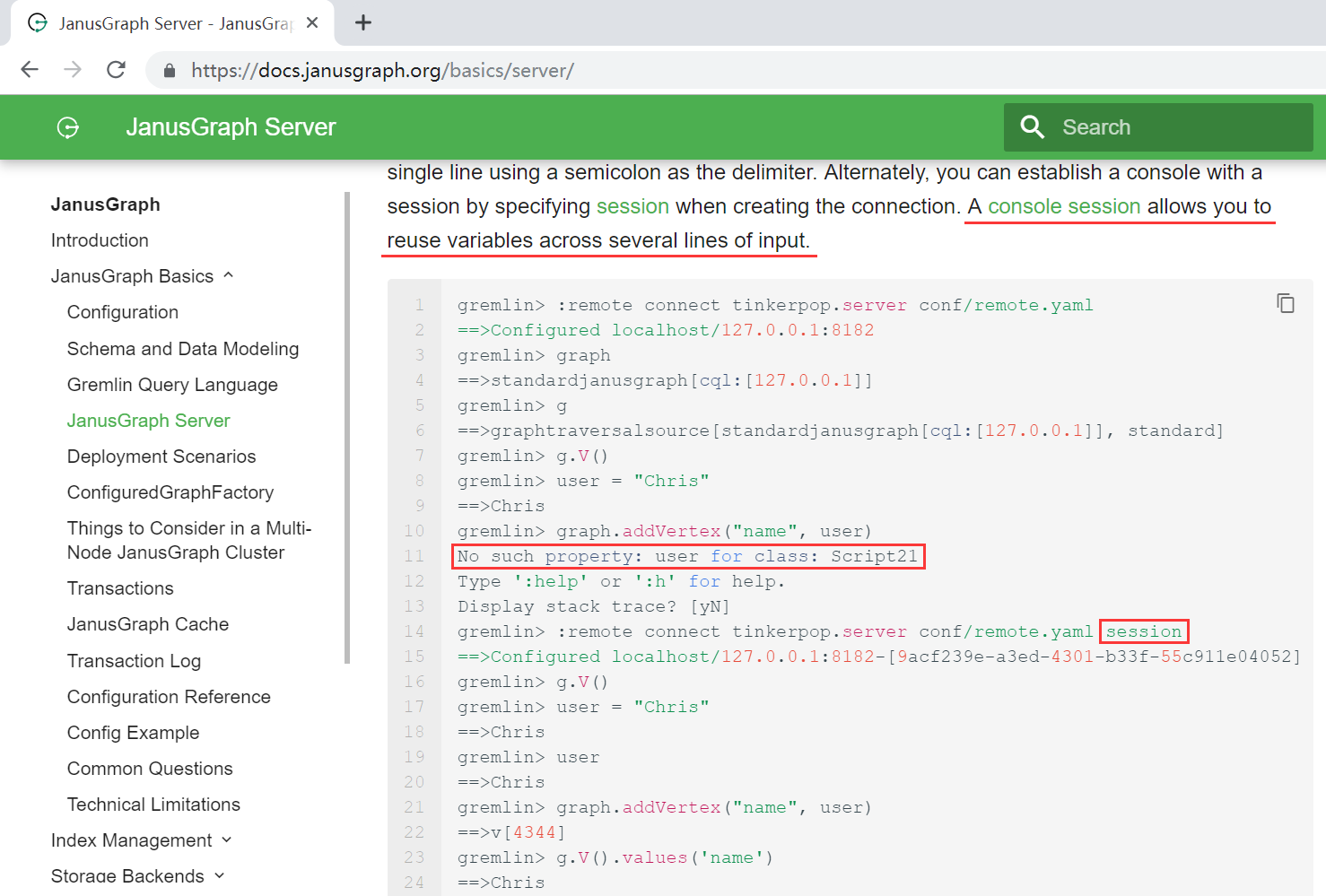
Tinkerpop官方文档也有相应说明:http://tinkerpop.apache.org/docs/current/reference/#considering-state
解决方法很简单,只需在连接Gremlin服务器的第一条命令最后加一个 “session” 即可:
1
:remote connect tinkerpop.server conf/remote.yaml session

4.2 使用Java连接Gremlin服务器
https://docs.janusgraph.org/connecting/java/
添加Maven依赖:
1
2
3
4
5
6
7
8
9
10
<dependency>
<groupId>org.janusgraph</groupId>
<artifactId>janusgraph-driver</artifactId>
<version>0.5.2</version>
</dependency>
<dependency>
<groupId>org.apache.tinkerpop</groupId>
<artifactId>gremlin-driver</artifactId>
<version>3.4.6</version>
</dependency>
添加Gradle依赖:
1
2
compile "org.janusgraph:janusgraph-driver:0.5.2"
compile "org.apache.tinkerpop:gremlin-driver:3.4.6"
4.3 使用Python连接Gremlin服务器
https://docs.janusgraph.org/connecting/python/
安装依赖库:
1
pip install gremlinpython
连接服务器:
1
2
3
4
5
6
7
from gremlin_python import statics
from gremlin_python.driver.driver_remote_connection import DriverRemoteConnection
from gremlin_python.process.graph_traversal import __
from gremlin_python.structure.graph import Graph
graph = Graph()
connection = DriverRemoteConnection('ws://192.168.0.83:8182/gremlin', 'g')
g = graph.traversal().withRemote(connection)
查询:
1
names = g.V('1').outE('knows').inV().values('name').toList()
注意:由id获取顶点需要用statics.long或字符串,直接用整数或用参考文档中的g.V(('id', 14372606192))当id较大时会报错KeyError: None
关闭连接:
1
connection.close()
5.图数据库结构
图数据库的结构(schema)包括顶点标签、边标签以及各自的属性。尽管JanusGraph支持创建任意的标签和属性,但JanusGraph官方鼓励用户显式地定义图数据库结构,从而提高应用的健壮性,并且便于合作开发。
官方文档:https://docs.janusgraph.org/basics/schema/
5.1 打印结构信息
1
2
mgmt = graph.openManagement()
mgmt.printSchema()
5.2 定义顶点标签
1
2
3
mgmt = graph.openManagement()
mgmt.makeVertexLabel(name).make()
mgmt.commit()
其中name是一个字符串,指定顶点标签的名字,在一个图数据库中必须是唯一的
5.3 定义边标签
1
2
3
mgmt = graph.openManagement()
mgmt.makeEdgeLabel(name).multiplicity(multiplicity).make()
mgmt.commit()
其中name是一个字符串,指定边标签的名字,在一个图数据库中必须是唯一的;multiplicity是枚举类型org.janusgraph.core.Multiplicity的对象,指定了顶点对之间该标签的边的最大数量限制,有5种选项(默认为MULTI):
| 选项 | 含义 |
| MULTI | 每对顶点之间可以有多条该标签的边(多图) |
| SIMPLE | 每对顶点之间至多有一条该标签的边(简单图) |
| MANY2ONE | 每个顶点至多有一条该标签的出边,入边无限制(例如 “mother” ) |
| ONE2MANY | 每个顶点至多有一条该标签的入边,出边无限制(例如 “winnerOf” ) |
| ONE2ONE | 每个顶点至多有一条该标签的入边和一条该标签出边(例如 “marriedTo” ) |
例如:
1
2
3
4
mgmt = graph.openManagement()
mgmt.makeEdgeLabel('follow').make()
mgmt.makeEdgeLabel('mother').multiplicity(MANY2ONE).make()
mgmt.commit()
5.4 定义属性键
顶点和边都可以有属性,属性就是键值对,图数据库结构可以定义每种顶点和边的属性键(property key),以及限制属性值的类型和基数(单个/多个)。
1
2
3
mgmt = graph.openManagement()
mgmt.makePropertyKey(name).dataType(clazz).cardinality(cardinality).make()
mgmt.commit()
其中name是一个字符串,指定属性键的名字,在一个图数据库中必须是唯一的;clazz是一个Class类型的对象,指定属性值的类型,可选的类型有String, Character, Boolean, Byte, Short, Integer, Long, Float, Double, java.util.Date, org.janusgraph.core.attribute.Geoshape, java.util.UUID(注意,不能是原始类型,如int);cardinality是枚举类型org.janusgraph.core.Cardinality的对象,指定属性值的基数,即每个顶点上该属性键对应的值的数量,有3种选项(默认为SINGLE):
| 选项 | 含义 |
|---|---|
| SINGLE | 单个值 |
| LIST | 多个值、可重复 |
| SET | 多个值、无重复 |
例如:
1
2
3
4
5
mgmt = graph.openManagement()
mgmt.makePropertyKey('birthDate').dataType(Date.class).make()
mgmt.makePropertyKey('name').dataType(String.class).cardinality(Cardinality.SET).make()
mgmt.makePropertyKey('sensorReading').dataType(Double.class).cardinality(Cardinality.LIST).make()
mgmt.commit()
注意
- 如果未定义结构就添加顶点和边,则JanusGraph会根据所添加的元素自动定义标签和属性键。
- 默认情况下,JanusGraph不会根据结构定义对新创建的元素的标签和属性键、边所关联的顶点标签以及属性所属的顶点或边的标签进行限制,但可以通过开启结构限制来实现,参考https://docs.janusgraph.org/basics/schema/#schema-constraints。
- JanusGraph会根据结构定义对新创建元素的属性值的类型进行限制,如果类型不同会尝试进行转换,如果无法转换则会报错。
- 定义边标签时没有限制关联的顶点的标签,每种标签的边都可以在任意两个顶点之间创建,但边的数量必须符合结构中定义的重数,否则会报错。
6.存储后端
官方文档:https://docs.janusgraph.org/storage-backend/
7.索引后端
官方文档:https://docs.janusgraph.org/index-backend/
8.创建索引
官方文档:https://docs.janusgraph.org/index-management/index-performance/
参考: