《Java核心技术》笔记 卷I 第7章 异常、断言和日志
对于异常情况,Java使用一种称为异常处理(exception handling)的错误捕获机制。本章的第1部分将介绍Java的异常。
在测试期间,需要运行大量检查以确保程序的正确性。但是这些检查可能非常耗时,在测试完成后也不必保留。本章的第2部分将介绍如何使用断言来选择性地启用检查。
当程序出现错误时,你可能希望记录出现的问题,以便日后分析。本章的第3部分将讨论标准Java日志框架。
7.1 处理错误
假设在Java运行期间出现了一个错误(例如错误的用户输入、打开不存在的文件、网络连接出现问题、使用非法的数组索引或者null引用),程序应该:
- 返回到一种安全状态,并允许用户执行其他命令;或者
- 允许用户保存所有工作,并妥善地终止程序。
要做到这些并不容易,因为引发错误的代码通常与错误处理代码相距很远。异常处理的任务就是将控制权从产生错误的地方转移到能够处理错误的代码。
对于方法中的错误,传统的处理方式是返回一个特殊的错误码(例如-1或null),由调用方法分析。遗憾的是,并不是任何情况下都能够返回错误码。例如,返回整型的方法就不能返回-1表示错误,因为-1很可能是一个完全合法的结果。
在Java中,如果一个方法不能以正常的方式完成任务,就可以选择另一个退出路径。在这种情况下,方法不会返回任何值,而是抛出(throw)一个封装了错误信息的对象——异常。注意,这个方法会立刻退出。此外,也不会从调用这个方法的代码处继续执行;相反,异常处理机制开始搜索一个能够处理这种异常状况的异常处理器(exception handler)。
异常有自己的语法和特殊的继承层次结构。
7.1.1 异常分类
在Java中,异常(exception)对象都是派生于Throwable的类的实例。如果Java中内置的异常类不能满足需求,还可以创建自己的异常类。
下图是Java异常层次结构的简化示意图。
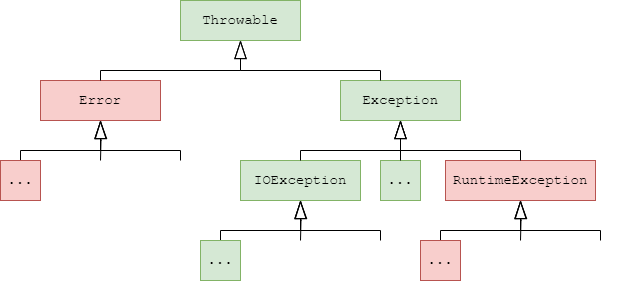
所有的异常都是由Throwable继承而来,但下一层立即分为两个分支:Error和Exception。
Error层次结构描述了Java运行时系统的内部错误和资源耗尽问题(例如OutOfMemoryError表示内存不足)。你不应该抛出这种类型的异常。如果出现了这样的内部错误,除了通知用户并尽力妥善地终止程序之外,几乎无能为力。这种情况很少出现。
编写Java程序时,要重点关注Exception层次结构。Exception层次结构又分为两个分支:继承自RuntimeException的异常和其他异常。一般规则是:由编程错误导致的、完全可以避免的异常属于RuntimeException;程序本身没有问题,由于像I/O错误这类不可预测的问题导致的异常属于其他异常。
继承自RuntimeException的异常包括:
- 数组下标越界(
ArrayIndexOutOfBoundsException) - 访问空指针(
NullPointerException) - 不合法的参数(
IllegalArgumentException) - 错误的强制类型转换(
ClassCastException)
不继承自RuntimeException的异常包括:
- 试图在文件末尾后读取数据(
EOFException) - 试图打开一个不存在的文件(
FileNotFoundException) - 试图根据字符串查找不存在的类(
ClassNotFoundException)
“如果出现RuntimeException,那么一定是你的问题。”例如,应该通过检测索引是否越界来避免ArrayIndexOutOfBoundsException;如果在使用变量之前检查它是否为null,NullPointerException就不会发生。
Java语言规范将派生于Error或RuntimeException类的所有异常称为非检查型(unchecked)异常(上图中红色部分),所有其他异常称为检查型(checked)异常(上图中绿色部分)。
注释:RuntimeException这个名字有点令人困惑。现在讨论的所有错误都发生在运行时(相对于编译时的语法错误)。
C++注释:C++有两个基本的异常类:runtime_error和logic_error。logic_error类表示程序中的逻辑错误,相当于Java中的RuntimeException;runtime_error类表示由于不可预测的问题导致的异常,相当于Java中的非RuntimeException异常。
7.1.2 声明检查型异常
在方法的首部使用throws子句声明可能抛出的异常。例如:
1
public FileInputStream(String name) throws FileNotFoundException
这个声明表示这个构造器将根据字符串参数构造一个FileInputStream对象,但也有可能抛出一个FileNotFoundException异常。
编写自己的方法时,如果出现以下两种情况:
- 使用
throw语句抛出了检查型异常 - 调用了会抛出检查型异常的方法(且没有捕获)
则必须使用throws子句声明,告诉使用这个方法的程序员有可能抛出异常。多个异常类之间用逗号隔开。例如:
1
2
3
4
5
6
class MyAnimation {
...
public Image loadImage(String s) throws FileNotFoundException, EOFException {
...
}
}
但是,不需要(也不应该)声明非检查型异常:
1
2
3
4
5
6
class MyAnimation {
...
void drawImage(int i) throws ArrayIndexOutOfBoundsException { // bad style
...
}
}
总之,方法必须声明所有可能抛出的检查型异常,否则编译器将报错;而不需要声明非检查型异常,因为非检查型异常要么完全无法控制(Error),要么完全可以避免(RuntimeException)。
当然,也可以捕获异常,这样异常不会被抛出到这个方法之外,也就不必使用throws声明。
方法抛出的异常可能属于它声明的异常类,也可能属于这个类的子类(注:即方法抛出的异常也适用替换原则,见5.1.5节)。例如,FileInputStream构造器声明throws IOException,实际抛出的异常可能是IOException,也可能是其子类FileNotFoundException。
警告:如果覆盖了超类方法,子类方法声明的检查型异常不能比超类方法声明的异常更通用(子类方法可以抛出更具体的异常,或者不抛出任何异常)(注:例如,如果超类方法声明throws IOException,则子类方法可以声明throws FileNotFoundException或者不声明,但不能声明throws Exception)。特别地,如果超类方法没有抛出任何检查型异常,子类方法也不能抛出。
7.1.3 抛出异常
假设有一个readData()方法正在读取一个文件,文件首部承诺长度为1024个字符,但是读取733个字符之后就遇到了文件结尾(end of file, EOF)。你认为这是一种不正常的情况,希望抛出一个异常。EOFException正合适。
使用throw语句抛出一个异常:
1
throw new ExceptionClass(...);
下面是完整的代码:
1
2
3
4
5
6
7
8
9
10
11
String readData(Scanner in) throws EOFException {
...
while (...) {
if (!in.hasNext()) { // EOF encountered
if (n < len)
throw new EOFException();
}
...
}
return s;
}
EOFException还有一个带字符串参数的构造器,可用于更详细地描述异常情况。
1
throw new EOFException("Content-length: " + len + ", Received: " + n);
C++注释:在C++中抛出异常与Java基本相同,只有一点微小的差别。在Java中,只能抛出Throwable子类的对象。而在C++中,可以抛出任何类型的值(如int)。
7.1.4 创建异常类
你的代码可能会遇到任何标准异常类都无法描述清楚的问题。在这种情况下,可以创建自己的异常类,只需继承Exception或其子类。习惯上应该提供默认构造器和包含详细信息的构造器。(超类Throwable的getMessage()和toString()方法会返回包含这个详细信息的字符串,这在调试中非常有用。)
1
2
3
4
class FileFormatException extends IOException {
public FileFormatException() {}
public FileFormatException(String message) { super(message); }
}
现在就可以抛出自己定义的异常类型了。
1
2
3
4
5
6
7
8
9
10
11
String readData(Scanner in) throws FileFormatException {
...
while (...) {
if (!in.hasNext()) { // EOF encountered
if (n < len)
throw new FileFormatException("Content-length: " + len + ", Received: " + n);
}
...
}
return s;
}
7.2 捕获异常
7.2.1 捕获一个异常
要捕获异常,需要使用try/catch语句。最简单的try语句形式如下:
1
2
3
4
5
6
try {
// code
}
catch (ExceptionType e) {
// handler for this type
}
如果try语句块中的任何代码抛出了catch子句中指定的类型的异常,那么程序将跳过try语句块的剩余代码,并执行catch子句中的处理器代码。
如果try语句块中的代码没有抛出任何异常,那么程序将跳过catch子句。
如果try语句块中的代码抛出了不是catch子句中指定的类型的异常(或者根本没有使用try语句捕获异常),那么这个方法会立即退出,异常继续向调用者传播,直到main()方法。如果没有在任何地方捕获这个异常,程序就会终止并在控制台上打印一条消息,包括异常类型和栈轨迹。
注:catch子句指定的异常必须在try语句块中有抛出对应异常的方法调用,否则编译器会报错。
为了展示这一过程,下面给出一段读取数据的典型代码:
1
2
3
4
5
6
7
8
9
10
11
12
public void read(String filename) {
try {
var in = new FileInputStream(filename);
int b;
while ((b = in.read()) != -1) {
// process input
}
}
catch (IOException e) {
e.printStackTrace();
}
}
FileInputStream.read()方法有可能抛出IOException。在这种情况下,将跳出整个while循环,并打印栈轨迹。
通常,最好的选择是什么也不做,而直接将异常传递给调用者。如果采用这种方式,就必须声明这个方法可能会抛出IOException:
1
2
3
4
5
6
7
public void read(String filename) throws IOException {
var in = new FileInputStream(filename);
int b;
while ((b = in.read()) != -1) {
// process input
}
}
一般规则是:捕获那些你知道如何处理的异常,继续传播那些你不知道如何处理的异常。
这个规则有一个例外。前面曾提到过:如果覆盖的超类方法没有抛出异常,子类方法也不能抛出异常(见7.1.2节),那么就必须捕获方法代码中出现的所有检查型异常。
7.2.2 捕获多个异常
可以在一个try语句中捕获多种类型的异常,需要为每种异常使用一个单独的catch子句,并做出不同的处理。如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
try {
// code that might throw exceptions
}
catch (FileNotFoundException e) {
// emergency action for missing files
}
catch (UnknownHostException e) {
// emergency action for unknown hosts
}
catch (IOException e) {
// emergency action for all other I/O problems
}
从Java 7起,可以在一个catch子句中捕获多种类型的异常,使用|分隔。例如,假设缺少文件和未知主机对应的动作是一样的,就可以合并catch子句:
1
2
3
4
5
6
7
8
9
try {
// code that might throw exceptions
}
catch (FileNotFoundException | UnknownHostException e) {
// emergency action for missing files and unknown hosts
}
catch (IOException e) {
// emergency action for all other I/O problems
}
只有当捕获的异常类型彼此之间不存在子类关系时才需要这个特性。
注释:捕获多个异常时,异常变量隐式为final(因为类型不确定,不能赋值)。
7.2.3 再次抛出异常与异常链
可以在catch子句中抛出异常。通常,希望改变异常的类型时会这样做。例如:
1
2
3
4
5
6
try {
// access the database
}
catch (SQLException e) {
throw new ServletException("database error: " + e.getMessage());
}
不过,更好的做法是将原始异常设置为新异常的“原因”:
1
2
3
4
5
6
7
8
try {
// access the database
}
catch (SQLException original) {
var e = new ServletException("database error");
e.initCause(original);
throw e;
}
注:除了initCause()方法,异常类通常也会提供接受“原因”参数的构造器。
捕获到这个异常时,可以使用getCause()获取原始异常。
强烈建议使用这种包装技术。这样可以在子系统中抛出高层异常,而不会丢失原始异常的细节。
提示:如果在一个不允许抛出检查型异常的方法中出现了检查型异常,这种包装技术也很有用。可以捕获这个检查型异常,并将它包装成一个RuntimeException。
7.2.4 finally子句
当代码抛出异常时,就会停止处理方法中剩余的代码并退出这个方法。如果这个方法已经获得了一些只有它自己知道的本地资源,而且这些资源必须被清理,这就会有问题。finally子句可以解决这个问题。
不管是否捕获到异常,finally子句中的代码都会执行。在下面的示例中,所有情况下程序都将关闭输入流。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
var in = new FileInputStream(...);
try {
// 1
// code that might throw exceptions
// 2
}
catch (IOException e) {
// 3
// show error message
// 4
}
finally {
// 5
in.close();
}
// 6
在这段代码中,有3种情况会执行finally子句:
- 代码没有抛出异常。在这种情况下,首先执行
try语句块中的全部代码,然后执行finally子句中的代码。执行顺序是1、2、5、6。 - 代码抛出了异常,并在
catch子句中捕获。在这种情况下,将执行try语句块,直到抛出异常为止。然后跳过try语句块中的剩余代码,执行对应的catch子句,最后执行finally子句。- 如果
catch子句没有抛出异常,则执行顺序是1、3、4、5、6。 - 如果
catch子句抛出了异常,异常将被抛回这个方法的调用者,执行顺序只是1、3、5。
- 如果
- 代码抛出了异常,但没有任何
catch子句捕获。在这种情况下,将执行try语句块,直到抛出异常为止。然后跳过try语句块中的剩余代码,执行finally子句。异常将被抛回这个方法的调用者,执行顺序是1、5。
try语句可以只有finally子句,而没有catch子句。例如:
1
2
3
4
5
6
7
InputStream in = ...;
try {
// code that might throw exceptions
}
finally {
in.close();
}
然而,in.close()可能会抛出IOException。如果finally子句遇到异常,这个异常将被重新抛出,并且必须由另一个catch子句捕获。
1
2
3
4
5
6
7
8
9
10
11
12
InputStream in = ...;
try {
try {
// code that might throw exceptions
}
finally {
in.close();
}
}
catch (IOException e) {
// show error message
}
内层的try语句只有一个职责:确保关闭输入流。外层的try语句也只有一个职责:确保报告错误。这种解决方案不仅更清晰,而且功能更强:可以报告finally子句中出现的错误。
注:即使try语句块包含return语句,finally子句也会在返回前执行。
警告:当finally子句包含return语句时,有可能产生意想不到的结果。假设使用return语句从try语句块中间退出。在方法返回前,会执行finally子句。如果finally子句也包含return语句,这个返回值将会覆盖原来的返回值。考虑这个例子:
1
2
3
4
5
6
7
8
public static int parseInt(String s) {
try {
return Integer.parseInt(s);
}
finally {
return 0; // ERROR
}
}
如果调用parseInt("42"),方法将返回0,而不是42。如果调用parseInt("zero"),Integer.parseInt()将抛出NumberFormatException,而finally子句会“吞掉”这个异常。
finally子句用于清理资源。不要把改变控制流的语句(return, throw, break, continue)放在finally子句中。
7.2.5 带资源的try语句
从Java 7开始,对于以下代码模式
1
2
3
4
5
6
7
// open a resource
try {
// work with the resource
}
finally {
// close the resource
}
有一个很有用的快捷方式——带资源的try语句,前提是资源属于实现了AutoCloseable接口的类。AutoCloseable接口只有一个close()方法,声明为抛出Exception。
注释:还有一个Closeable,它是AutoCloseable的子接口。不过,其close()方法声明为抛出IOException。
带资源的try语句(try-with-resources statement)最简单的形式为:
1
2
3
try (Resource res = ...) {
// work with res
}
try语句块退出时,会自动调用res.close()(就像使用了finally子句一样)。下面是一个典型的例子——读取一个文件中的所有单词:
1
2
3
4
try (var in = new Scanner(Path.of("in.txt"), StandardCharsets.UTF_8)) {
while (in.hasNext())
System.out.println(in.next());
}
注:带资源的try语句类似于Python的with语句或C++的RAII思想。
可以指定多个资源。例如:
1
2
3
4
5
try (var in = new Scanner(Path.of("in.txt"), StandardCharsets.UTF_8);
var out = new PrintWriter("out.txt", StandardCharsets.UTF_8)) {
while (in.hasNext())
out.println(in.next().toUpperCase());
}
不论这个块如何退出,in和out都会关闭。如果用常规方式手动编程,就需要两个嵌套的try/finally语句。
从Java 9起,可以在try首部提供之前声明的事实最终变量:
1
2
3
4
5
6
public static void printAll(String[] lines, PrintWriter out) {
try (out) { // effectively final variable
for (String line : lines)
out.println(line);
} // out.close() called here
}
在常规的try语句中,如果try块抛出异常并且close()方法也抛出异常,就会带来一个难题。带资源的try语句可以很好地处理这种情况:原来的异常会重新抛出,而close()方法抛出的异常会“被抑制”——被自动捕获,并使用addSuppressed()方法添加到原来的异常中,之后可以调用getSuppressed()方法获取。
注释:带资源的try语句也可以有catch子句和finally子句。这些子句会在关闭资源之后执行。
7.2.6 分析栈轨迹元素
栈轨迹(stack trace)是程序执行过程中某个特定点上所有挂起的方法调用的列表(即:从main()方法到当前方法的调用序列)。当Java程序因为未捕获的异常而终止时,就会显示栈轨迹。
可以调用Throwable类的printStackTrace()方法打印栈轨迹的文本描述,如下所示(调用者在下,被调用者在上)。
1
2
3
4
Exception in thread "main" java.lang.NullPointerException
at MyClass.mash(MyClass.java:9)
at MyClass.crunch(MyClass.java:6)
at MyClass.main(MyClass.java:3)
注:该方法默认打印到标准错误流(System.err),也可以指定输出流。
一种更灵活的方法是使用StackWalker类(Java 9引入),它会生成一个StackWalker.StackFrame实例的流,其中每个实例分别描述一个栈帧(stack frame)。可以使用forEach()或walk()方法处理这些栈帧:
1
2
StackWalker walker = StackWalker.getInstance();
walker.forEach(frame -> /* analyze frame */)
StackWalker.StackFrame类有一些方法可以获得正在执行的代码行的文件名和行号,以及类对象和方法名。toString()方法会生成包含所有这些信息的格式化字符串。
注释:在Java 9之前,可以使用Throwable.getStackTrace()方法分析堆栈元素。该方法会生成一个StackTraceElement数组,其中包含与StackWalker.StackFrame类似的信息。不过,这个方法的效率不高,因为即使调用者只需要几个栈帧,它也会捕获整个栈。另外,它只能访问挂起方法的类名,而不能访问类对象。
程序清单7-1打印了递归阶乘函数的栈轨迹。例如,如果计算factorial(3),输出结果为
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
factorial(3):
stackTrace.StackTraceTest.factorial(StackTraceTest.java:19)
stackTrace.StackTraceTest.main(StackTraceTest.java:31)
factorial(2):
stackTrace.StackTraceTest.factorial(StackTraceTest.java:19)
stackTrace.StackTraceTest.factorial(StackTraceTest.java:22)
stackTrace.StackTraceTest.main(StackTraceTest.java:31)
factorial(1):
stackTrace.StackTraceTest.factorial(StackTraceTest.java:19)
stackTrace.StackTraceTest.factorial(StackTraceTest.java:22)
stackTrace.StackTraceTest.factorial(StackTraceTest.java:22)
stackTrace.StackTraceTest.main(StackTraceTest.java:31)
return 1
return 2
return 6
程序清单7-1 stackTrace/StackTraceTest.java
7.3 使用异常的提示
下面给出一些合理使用异常的提示。
1.异常处理不应该代替简单测试。 作为一个示例,下面的代码尝试将一个空栈弹出10000000次。第一种做法是首先查看栈是否为空:
1
if (!stack.empty()) stack.pop();
第二种做法是捕获异常:
1
2
3
4
5
try {
stack.pop();
}
catch (EmptyStackException e) {
}
exceptional/ExceptionalTest.java
在我的测试机器上,第一个版本的运行时间为646毫秒,第二个版本的运行时间为21739毫秒。
可以看出,捕获异常所花费的时间比执行简单测试要长得多(前者是后者的30多倍)。因此,只在异常情况下使用异常。
2.不要过分地细化异常。 有些程序员将每条语句都放在一个单独的try语句块中:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
PrintStream out;
Stack s;
for (i = 0; i < 100; i++) {
try {
n = s.pop();
}
catch (EmptyStackException e) {
// stack was empty
}
try {
out.writeInt(n);
}
catch (IOException e) {
// problem writing to file
}
}
这种方式将导致代码量急剧膨胀。合理的做法是将整个任务放在一个try语句块中。如果任何一个操作失败,就可以放弃整个任务。
1
2
3
4
5
6
7
8
9
10
11
12
try {
for (i = 0; i < 100; i++) {
n = s.pop();
out.writeInt(n);
}
}
catch (IOException e) {
// problem writing to file
}
catch (EmptyStackException e) {
// stack was empty
}
这样也满足了异常处理的一个承诺:将正常处理与错误处理分离。
3.合理利用异常层次结构。 不要只抛出RuntimeException,应该找一个合适的子类或创建自己的异常类。不要只捕获Throwable,这会使代码难以阅读和维护。
如果能够将一种异常转换成另一种更加合适的异常,那么不要犹豫。例如,在解析文件中的整数时,可以捕获NumberFormatException并将其转换为IOException的一个子类或自定义异常。
4.不要压制异常。 例如:
1
2
3
4
5
6
public Image loadImage(String s) {
try {
// code that threatens to throw checked exceptions
}
catch (Exception e) {} // so there
}
如果发生了异常,异常将被悄无声息地忽略。如果你认为异常很重要,就应该努力正确处理它们。
5.检测到错误时,“苛刻”要比放任更好。 有些程序员很担心抛出异常。例如,当栈为空时,pop()应该返回null还是抛出异常?我们认为,在出错时抛出EmptyStackException要比以后出现NullPointerException更好。
6.不要羞于传播异常。 有些程序员感觉应该捕获所有抛出的异常。其实在很多情况下,传播异常比捕获异常更好。例如:
1
2
3
4
public void readStuff(String filename) throws IOException { // not a sign of shame!
var in = new FileInputStream(filename, StandardCharsets.UTF_8);
...
}
更高层的方法通常可以更好地通知用户发生了错误,或者放弃不成功的命令。
注释:规则5和6可以归纳为“早抛出,晚捕获”。
7.使用标准方法报告空指针和越界异常。 Objects类有requireNonNull()、checkIndex()、checkFromToIndex()、checkFromIndexSize()等方法来完成这些常见的检查。使用这些方法进行参数验证:
1
2
3
4
5
public void putData(int position, Object newValue) {
Objects.checkIndex(position, data.length);
Objects.requireNonNull(newValue);
...
}
如果验证失败,将使用适当的消息抛出异常。
8.不要向最终用户显示栈轨迹。 栈轨迹可能包含你不想暴露给潜在攻击者的实现细节,例如你使用的库的版本。应该将栈轨迹记录日志以便以后获取,而只向用户展示一个总结消息。
7.4 使用断言
7.4.1 断言的概念
假设你确信满足某个条件,并且代码依赖于这个条件。例如,需要计算
1
double y = Math.sqrt(x);
你确信x是非负数(原因可能是x是另一个计算的结果,这个计算的结果不可能为负;或者x是一个方法的参数,这个方法要求调用者只能提供正数)。不过,你还是想再次检查,以免计算中潜入NaN值。当然,可以抛出异常:
1
if (x < 0) throw new IllegalArgumentException("x < 0");
但即使测试完成后,这段代码还是会保留在程序中。如果有大量的这种检查,程序运行起来会慢一些。
断言(assertion)机制允许你在测试期间在代码中插入一些检查,而在生产代码中自动将其删除。
Java语言有一个关键字assert,有两种形式:
1
2
assert condition;
assert condition : expression;
这两个语句都会计算条件,如果为假则抛出AssertionError。在第二个语句中,表达式将被传入AssertionError的构造器,并转换成一个消息字符串。
注释:表达式部分的唯一目的是生成消息字符串,AssertionError对象并不存储表达式的具体值。
要断言x是非负数,只需使用语句
1
assert x >= 0;
或者将x的具体值传入AssertionError对象,以便之后显示:
1
assert x >= 0 : x;
7.4.2 启用和禁用断言
默认情况下,断言是禁用的。可以在运行程序时用-enableassertions或-ea选项启用断言:
1
java -enableassertions MyApp
注意,不必重新编译程序来启用或禁用断言,因为这是类加载器(class loader)的功能。禁用断言时,类加载器会去除断言代码。
甚至可以在特定的类或整个包中启用断言,使用选项-ea:类名或-ea:包名...。例如:
1
java -ea:MyClass -ea:com.mycompany.mylib... MyApp
这条命令将为MyClass类以及com.mycompany.mylib包及其子包中的所有类启用断言。选项-ea:...为无名包中的所有类启用断言。
也可以用-disableassertions或-da选项在特定的类和包中禁用断言:
1
java -ea:... -da:MyClass MyApp
有些类不是由类加载器加载,而是直接由虚拟机加载。可以使用带参数的-ea或-da选项启用或禁用这些类中的断言。然而,无参数的-ea和-da选项不作用于没有类加载器的“系统类”。需要使用-enablesystemassertions/-esa选项启用系统类中的断言,使用-disablesystemassertions/-dsa选项禁用断言。
也可以通过编程方式控制类加载器的断言状态,参见ClassLoader类的API文档。
7.4.3 使用断言完成参数检查
Java提供了3种处理系统错误的机制:异常、断言和日志。
什么时候应该选择断言呢?请记住下面几点:
- 断言失败是致命的、不可恢复的错误。
- 断言检查只在开发和测试阶段打开。
因此,不应该使用断言向程序的其他部分通知可恢复的错误,也不应该用于与用户沟通问题。断言只应该用于在测试阶段定位程序内部错误。
下面看一个常见的场景:检查方法参数。是否应该使用断言来检查非法的索引值或null引用呢?要回答这个问题,首先阅读这个方法的文档。假设要实现一个排序方法(参见Arrays.sort()方法文档)。
文档指出,如果索引值不正确,这个方法会抛出一个异常。这是方法与其调用者之间约定的行为。如果实现这个方法,就必须要遵守这个约定。因此这里不适合使用断言。
是否应该断言a不是null呢?这也不太合适。方法文档并没有指出当a是null时的行为。调用者可以假定在这种情况下方法会成功返回,而不会抛出断言错误。
然而,假设对方法约定做一点微小的改动:
1
@param a the array to be sorted (must not be null).
现在,这个方法的调用者就必须注意:使用null数组调用这个方法是不合法的。这样,就可以在这个方法的开头使用断言:
1
assert a != null;
这种约定称为前置条件(precondition)。原来的方法对参数没有前置条件,即承诺在任何情况下都有明确的行为。修改后的方法有一个前置条件:a不是null。如果调用者没有满足这个前置条件,这个方法就能“为所欲为”(可能抛出断言错误或者空指针异常)。
7.4.4 使用断言记录假设
程序员通常使用注释来记录底层假设。考虑这个来自Programming With Assertions的示例:
1
2
3
4
5
6
7
if (i % 3 == 0) {
...
} else if (i % 3 == 1) {
...
} else { // We know (i % 3 == 2)
...
}
在这种情况下,使用断言会很有意义。
1
2
3
4
5
6
7
8
if (i % 3 == 0) {
...
} else if (i % 3 == 1) {
...
} else {
assert i % 3 == 2 : i;
...
}
深入思考这个问题会更有意义。如果i是正数,则i % 3肯定是0、1或2。而如果i是负数,余数可能是-1和-2(见3.5.2节)。因此,真正的假设是i为非负数。更好的做法是在if语句之前使用断言assert i >= 0;。
无论如何,这个示例很好地展示了程序员如何使用断言来进行自我检查。
7.5 日志
每个Java程序员都很熟悉将System.out.println()插入到有问题的代码中来观察程序的行为。一旦发现问题的根源,就要将这些打印语句删除,下次遇到问题时再加回来。日志(logging) API就是为了解决这个问题而设计的。这个API的主要优点:
- 可以很容易地抑制全部或特定级别以下的日志记录,也很容易将其重新打开。
- 开销很小,唯一的一点坏处就是将日志代码留在程序中。
- 日志记录可以被定向到不同的处理器,如控制台、文件等。
- 日志记录器和处理器都可以对日志进行过滤,过滤器可以根据指定的标准丢弃无用的日志记录。
- 日志记录可以采用不同的方式格式化,例如纯文本或XML。
- 应用程序可以使用多个日志记录器,它们使用类似于包名的有层次的名字(例如com.mycompany.myapp)。
- 日志配置由配置文件控制。
注释:很多应用会使用其他的日志框架,例如Log4j和Logback,它们能提供比标准Java日志框架更高的性能。SLF4J和Commons Logging等日志外观库(logging facade)提供了一个统一的API,使你无需重写应用就可以替换日志框架。在本书中只介绍标准Java日志框架。
注释:从Java 9起,Java平台有一个单独的轻量级日志系统(System.Logger)。这个系统只用于Java API,不是给开发应用的程序员使用的。
注:日志API包含在java.util.logging包中。应用程序通过日志记录器(Logger)进行日志记录。Logger会构造日志记录(LogRecord)对象,并传递给处理器(Handler)进行处理(发布)。Logger和Handler都可以使用日志等级(Level)和(可选的)过滤器(Filter)来决定是否对特定的日志记录感兴趣。在处理LogRecord对象时,Handler对象可以(可选地)使用格式化器(Formatter)对消息进行本地化和格式化。Java日志控制流如下图所示,详见官方文档Java Logging Overview。

7.5.1 基本日志
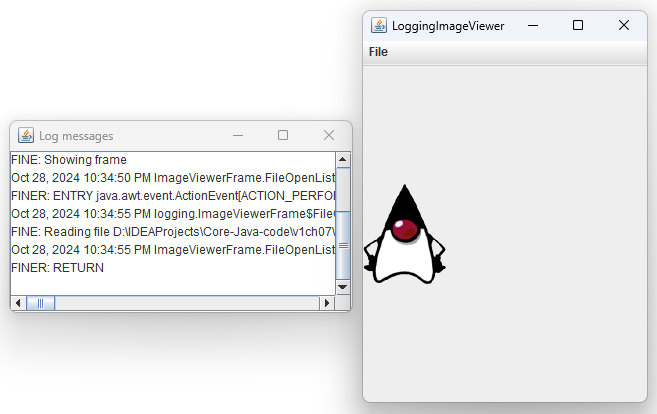
对于简单的日志记录,可以使用全局日志记录器并调用其info()方法:
1
Logger.getGlobal().info("File->Open menu item selected");
默认情况下,会打印如下的日志记录:
1
2
May 10, 2013 10:12:15 PM LoggingImageViewer fileOpen
INFO: File->Open menu item selected
7.5.2 高级日志
在专业的应用程序中,不会将所有的日志都记录到一个全局日志记录器中,而是会定义自己的日志记录器。
调用getLogger()方法创建或获取一个记录器:
1
private static final Logger myLogger = Logger.getLogger("com.mycompany.myapp");
与包名类似,记录器名也有层次,而且层次性更强。包与父包之间没有语义关系,但是父子记录器之间会共享某些属性。例如,如果对记录器 “com.mycompany” 设置了日志级别,其子记录器 “com.mycompany.myapp” 也会继承这个级别。
有7个日志级别,从高到低依次为SEVERE、WARNING、INFO、CONFIG、FINE、FINER和FINEST。默认情况下,只记录前3个级别。也可以设置不同的级别,例如:
1
logger.setLevel(Level.FINE);
现在会记录FINE和更高级别的日志。
还可以使用Level.ALL开启所有级别的日志,或者使用Level.OFF关闭所有日志。
所有级别都有对应的日志记录方法,例如logger.warning(message)等。另外,还可以使用log()方法并指定级别,例如logger.log(Level.FINE, message)。
提示:默认的日志级别为INFO。因此,对于那些有助于诊断但对用户意义不大的调试信息,应该使用CONFIG、FINE、FINER和FINEST级别。
注释:如果将记录器的日志级别设置为比INFO更低,还需要修改处理器的配置。详见下一节。
默认的日志记录会显示包含日志调用的类和方法的名字(根据调用栈得出)。但是,如果虚拟机对执行过程进行了优化,就可能得不到准确的调用信息。此时可以使用logp()方法给出调用类和方法的名称。
有一些方便的方法用来跟踪执行流:entering()和exiting()(用于记录进入/退出方法,底层调用了logp())。例如:
1
2
3
4
5
6
int read(String file, String pattern) {
logger.entering("Reader", "read", new Object[] {file, pattern});
...
logger.exiting("Reader", "read", count);
return count;
}
这些调用将生成FINER级别、以字符串 “ENTRY” 和 “RETURN” 开头的日志记录。
日志的一个常见用途是记录预料之外的异常。可以使用throwing()和带Throwable参数的log()方法在日志记录中包含异常的描述。典型用法是
1
2
3
4
5
if (...) {
var e = new IOException("...");
logger.throwing("Reader", "read", e);
throw e;
}
以及
1
2
3
4
5
6
try {
...
}
catch (IOException e) {
logger.log(Level.WARNING, "Reading image", e);
}
throwing()调用将生成FINER级别、以 “THROW” 开头的日志记录。
7.5.3 修改日志管理器配置
可以通过编辑配置文件来修改日志系统的各种属性。默认的配置文件位于$jdk/conf/logging.properties(在Java 9之前位于$jre/lib/logging.properties)。
要使用其他配置文件,需要(使用-D选项)将系统属性java.util.logging.config.file设置为配置文件的位置,使用以下命令启动程序:
1
java -Djava.util.logging.config.file=configFile MainClass
属性.level指定默认的日志级别,<logger-name>.level指定记录器的日志级别,例如:
1
2
.level=INFO
com.mycompany.myapp.level=FINE
稍后将看到,记录器并不将消息发送到控制台——那是处理器的任务。处理器也有级别,可以通过<handler-name>.level属性指定。要在控制台上看到FINE级别的日志,就需要设置
1
java.util.logging.ConsoleHandler.level=FINE
警告:日志配置中的设置不是系统属性。因此,用-Dcom.mycompany.myapp.level=FINE启动程序不会对记录器产生任何影响。
注:日志配置文件支持的属性参见LogManager、ConsoleHandler和FileHandler类的API文档。
要自定义日志配置文件,除了使用命令行选项-Djava.util.logging.config.file=configFile启动程序,还可以在程序中调用System.setProperty("java.util.logging.config.file", configFile),之后必须调用LogManager.getLogManager().readConfiguration()重新初始化日志管理器。
从Java 9起,可以通过调用LogManager.getLogManager().updateConfiguration(mapper);更新日志配置,详见API文档。
还可以使用jconsole程序改变正在运行的程序的日志级别,参见 https://www.oracle.com/technical-resources/articles/java/jconsole.html#LoggingControl 。
注释:日志配置文件由LogManager类处理。可以通过将系统属性java.util.logging.manager设置为某个子类的名字来指定不同的日志管理器。或者,仍然使用标准日志管理器,而将系统属性java.util.logging.config.class设置为某个以其他方式设置日志管理器属性的类的名字。详见LogManager类的API文档。
7.5.4 本地化
你可能希望将日志消息本地化,以便全球用户都可以阅读。
本地化的应用程序在资源包(resource bundle)中包含地区特定的信息。资源包由一组映射组成,分别对应各个地区(locale)(例如美国或德国)。例如,一个资源包可能将字符串 “readingFile” 映射为英语的 “Reading file” 或者德语的 “Achtung! Datei wird eingelesen” 。
一个程序可以包含多个资源包(例如,一个用于菜单,另一个用于日志消息)。每个资源包都有一个名字(如 “com.mycompany.logmessages” )。要为资源包添加映射,需要为每个地区提供一个文件。例如,英语消息映射位于文件com/mycompany/logmessages_en.properties,德语消息映射位于文件com/mycompany/logmessages_de.properties(en和de是语言代码)。将这些文件与应用程序的类文件放在一起,以便ResourceBundle类自动找到它们。这些文件都是纯文本文件,包含如下所示的条目:
1
2
readingFile=Achtung! Datei wird eingelesen
renamingFile=Datei wird umbenannt
获取记录器时,可以指定资源包:
1
Logger logger = Logger.getLogger(loggerName, "com.mycompany.logmessages");
然后,将日志消息指定为资源包中的键,而不是实际的消息字符串:
1
logger.info("readingFile");
要在本地化的消息中包含参数,可以使用{0}、{1}等占位符。例如:
1
2
readingFile=Reading file {0}
renamingFile=Renaming file {0} to {1}
然后调用下面的方法向占位符传递具体的值:
1
2
logger.log(Level.INFO, "readingFile", fileName);
logger.log(Level.INFO, "renamingFile", new Object[] {oldName, newName});
注:普通的日志消息也可以使用占位符。另外可以使用logrb()方法指定资源包。
从Java 9起,可以在logrb()方法中指定资源包对象(而不是名字):
1
logger.logrb(Level.INFO, bundle, "renamingFile", oldName, newName);
7.5.5 处理器
默认情况下,记录器将日志记录发送到ConsoleHandler,它会将日志打印到System.err。
与记录器一样,处理器也有日志级别。一条日志的级别必须高于记录器和处理器二者的级别才会被记录。默认的记录器和控制台处理器的级别都是INFO。要记录FINE级别的日志,需要修改配置文件:
1
2
3
.level=FINE
handlers=java.util.logging.ConsoleHandler
java.util.logging.ConsoleHandler.level=FINE
或者,可以绕过配置文件,使用自己的处理器:
1
2
3
4
5
6
Logger logger = Logger.getLogger("com.mycompany.myapp");
logger.setLevel(Level.FINE);
logger.setUseParentHandlers(false);
var handler = new ConsoleHandler();
handler.setLevel(Level.FINE);
logger.addHandler(handler);
默认情况下,记录器会把记录发送到自己的处理器和父记录器的处理器,最终的祖先(根记录器,名为"")有一个INFO级别的ConsoleHandler。我们并不想看到这些记录两次,因此将useParentHandlers属性设置为false。
要将日志记录发送到其他地方,就要添加另一个处理器。日志API为此提供了两个有用的处理器:FileHandler和SocketHandler。SocketHandler将记录发送到指定的主机和端口,FileHandler将记录收集到一个文件中。
可以如下将记录发送到默认的文件处理器:
1
2
var handler = new FileHandler();
logger.addHandler(handler);
这些记录被发送到用户主目录的javan.log文件中,其中n是文件的唯一编号。默认情况下,记录会被格式化为XML。可以通过配置文件或构造器来修改文件处理器的默认行为,详见FileHandler类的API文档。
还可以通过扩展Handler或StreamHandler类自定义处理器。在本节结尾的示例程序中就定义了这样一个处理器,在一个窗口中显示日志记录。
7.5.6 过滤器
默认情况下,会根据日志记录的级别进行过滤。每个记录器和处理器都可以有一个可选的过滤器来进行额外的过滤。要定义一个过滤器,需要实现Filter接口并定义isLoggable()方法。
要将过滤器安装到记录器或处理器中,只需调用setFilter()方法。注意,一次最多只能有一个过滤器。
7.5.7 格式化器
ConsoleHandler和FileHandler分别以文本和XML格式生成日志记录。也可以自定义格式。需要扩展Formatter类并覆盖format()方法。调用setFormatter()方法将格式化器安装到处理器中。
7.5.8 日志技巧
下面总结了最常用的日志操作。
1.使用getLogger()创建一个记录器,将记录器命名为与主应用包名相同是一个好主意。
1
private static final Logger logger = Logger.getLogger("com.mycompany.myprog");
2.默认配置会把级别为INFO或更高的日志记录打印到控制台,可以使用setLevel()设置日志级别。
1
logger.setLevel(Level.WARNING);
3.使用logger.info()等方法记录日志。
程序清单7-2使用了上述技巧,还做了一点调整:日志消息还会显示在一个日志窗口中。
程序清单7-2 logging/LoggingImageViewer.java
7.6 调试技巧
像Eclipse、IntelliJ IDEA和NetBeans之类的专业集成开发环境都提供了调试器。本节会提供一些在使用调试器之前值得尝试的技巧。
1.可以打印或日志记录任意变量的值:
1
System.out.println("x=" + x);
或
1
Logger.getGlobal().info("x=" + x);
Java标准库中的绝大多数类都覆盖了toString()方法,能够提供关于类的有用信息。这对调试非常有帮助。在你自定义的类中也应该这样做。
2.一个不太为人所知但非常有用的技巧是在每个类中放置一个单独的main()方法。在里面可以提供一个单元测试桩(stub),允许你独立地测试类。
1
2
3
4
5
6
7
public class MyClass {
// methods and fields
...
public static void main(String[] args) {
// test code
}
}
3.使用JUnit。JUnit是一个非常流行的单元测试框架,可以很容易地组织测试用例套件。每当对类做了修改就运行测试,一旦发现bug就再补充另一个测试用例。
4.日志代理(logging proxy)是一个子类的对象,它可以拦截方法调用,记录日志,然后调用超类方法。例如,如果Random.nextDouble()方法有问题,可以创建一个匿名子类的实例作为代理对象:
1
2
3
4
5
6
7
var generator = new Random() {
public double nextDouble() {
double result = super.nextDouble();
Logger.getGlobal().info("nextDouble: " + result);
return result;
}
};
要想知道谁调用了这个方法,可以生成栈轨迹。
5.利用Throwable.printStackTrace()方法,可以从任意的异常对象获得栈轨迹。例如:
1
2
3
4
5
6
7
try {
...
}
catch (Throwable t) {
t.printStackTrace();
throw t;
}
甚至不需要捕获异常来生成栈轨迹。只需在代码的任意位置插入语句Thread.dumpStack();
6.一般来说,栈轨迹显示在System.err上,也可以打印到指定的输出流。例如,将其捕获到一个字符串中:
1
2
3
var out = new StringWriter();
new Throwable().printStackTrace(new PrintWriter(out));
String description = out.toString();
7.将程序错误流捕获到文件通常会很有用:
1
java MyProgram 2> errors.txt
要将输出流和错误流捕获到同一个文件中,使用
1
java MyProgram > errors.txt 2>&1
这在Linux和Windows中都有效。
8.在System.err中显示未捕获异常的栈轨迹并不是一个理想的方法。更好的方法是通过日志记录到一个文件中。可以用静态方法Thread.setDefaultUncaughtExceptionHandler()改变未捕获异常的处理器:
1
2
3
4
5
Thread.setDefaultUncaughtExceptionHandler(new Thread.UncaughtExceptionHandler() {
public void uncaughtException(Thread t, Throwable e) {
// save information in log file
};
});
9.要想观察类的加载过程,可以使用-verbose选项启动Java虚拟机。有时候,这对诊断类路径问题会有帮助。
10.-Xlint选项告诉编译器检查常见的代码问题(例如switch语句的fallthrough):
1
javac -Xlint sourceFiles
可以启用和禁用各种类别的警告:
1
javac -Xlint:all,-fallthrough,-serial sourceFiles
可以用命令javac -help -X获得所有警告的列表。
11.Java虚拟机提供了对Java应用的监控和管理支持,允许跟踪内存消耗、线程使用、类加载等情况。这个特性对于大规模、长时间运行的Java程序(如应用服务器)尤其重要。JDK附带了一个名为jconsole的图形工具,可以显示虚拟机性能的统计结果。详见 https://www.oracle.com/technical-resources/articles/java/jconsole.html 。
12.Java任务控制器(Java Mission Control)是一个专业级性能分析和诊断工具,可以从 https://adoptium.net/jmc/ 或 https://jdk.java.net/jmc/8/ 得到。https://github.com/thegreystone/jmc-tutorial 提供了一个全面的教程。