《Java核心技术》笔记 卷II 第3章 XML
可扩展标记语言(Extensible Markup Language, XML)是一种非常有用的描述结构化信息的技术。本章介绍XML,并涵盖了Java库的XML特性。
3.1 XML简介
XML能够表示层次结构,这比属性文件(参见卷I第9章 9.7.3节)的平面结构更灵活。
XML文件的格式很简单,看起来类似于HTML文件。描述程序配置的XML文件可能会像这样:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
<config>
<entry id="title">
<font>
<name>Helvetica</name>
<size>36</size>
</font>
</entry>
<entry id="body">
<font>
<name>Times Roman</name>
<size>12</size>
</font>
</entry>
<entry id="background">
<color>
<red>0</red>
<green>50</green>
<blue>100</blue>
</color>
</entry>
</config>
XML标准:
XML和HTML都衍生自标准通用标记语言(Standard Generalized Markup Language, SGML),但是二者之前存在着重要的区别:
- 与HTML不同,XML是大小写敏感的。例如,
<Config>和<config>是不同的XML标签。 - 在HTML中可以省略结束标签(如
</p>或</li>),但在XML中绝对不能省略。 - 在XML中,只有单个标签而没有相应结束标签的元素必须以
/结尾,例如<img src="coffeecup.png"/>。 - 在XML中,属性值必须用引号括起来。例如
width="300"(width=300是合法的HTML,但不是合法的XML)。 - 在HTML中,属性名可以没有值,例如
<input type="radio" name="language" value="Java" checked>。在XML中,所有属性必须都有值,例如checked="true"或checked="checked"。 - 针对HTML 4和5设计的XML称为XHTML。
3.2 XML文档的结构
XML文档应该以一个文档头(header)开始,例如
1
<?xml version="1.0"?>
或者
1
<?xml version="1.0" encoding="UTF-8"?>
文档头是可选的,但是强烈推荐使用文档头。
注释:由于SGML是为了处理真实文档而创建的,因此XML文件被称为文档(document),尽管很多是用于描述数据集的。
文档头后面可以跟着文档类型定义(document type definition, DTD),例如
1
2
3
<!DOCTYPE web-app PUBLIC
"-//Sun Microsystems, Inc.//DTD Web Application 2.2//EN"
"http://java.sun.com/j2ee/dtds/web-app_2_2.dtd">
DTD是确保文档正确性的重要机制,但它不是必需的。
最后,XML文档的主体包含根元素(root element),根元素可以包含其他元素。例如:
1
2
3
4
5
6
7
8
9
10
11
<?xml version="1.0"?>
<!DOCTYPE config ...>
<config>
<entry id="title">
<font>
<name>Helvetica</name>
<size>36</size>
</font>
</entry>
...
</config>
元素可以包含子元素(child element)、文本或二者都有。在上述例子中,font元素有两个子元素name和size。name元素包含文本 “Helvetica” 。
提示:在设计XML文档结构时,最好让元素要么包含子元素,要么包含文本。换句话说,应该避免下面的情况:
1
2
3
4
<font>
Helvetica
<size>36</size>
</font>
在XML规范中,这叫做混合式内容(mixed content)。如果避免了混合式内容,就可以简化解析过程。
元素可以包含属性(attribute),例如:
1
<size unit="pt">36</size>
XML设计者对于何时使用元素、何时使用属性存在一些分歧。例如,相比上面的例子,将字体如下描述似乎更简单一些:
1
<font name="Helvetica" size="36"/>
但是,属性的灵活性差很多。假设你想为字体大小添加单位,如果使用属性,就必须把单位添加到属性值中:
1
<font name="Helvetica" size="36 pt"/>
现在必须解析字符串 “36 pt” ,而这正是XML旨在避免的麻烦。向size元素添加一个属性会清晰得多:
1
2
3
4
<font>
<name>Helvetica</name>
<size unit="pt">36</size>
</font>
一条常用的经验法则是:属性只应该用来修改值的解释,而不是用来指定值。如果你发现自己陷入了争议,就不要使用属性。许多有用的XML文档根本不使用属性。
元素和文本是XML文档的核心内容。下面是一些其他标记指令:
- 字符引用(character reference)的形式是
&#[0-9]+;或&#x[0-9a-fA-F]+;(注:其中的数字是字符在ISO/IEC 10646中的编码)。例如,字符é可以表示为é或é。 - 实体引用(entity reference)的形式是
&name;。预定义的实体引用:
| 实体引用 | 含义 |
|---|---|
< (less than) | < |
> (greater than) | > |
& (ampersand) | & |
" (quote) | ” |
' (apostrophe) | ’ |
可以在DTD中定义其他的实体引用。
- CDATA部分(CDATA section)以
<![CDATA[和]]>为界。它是字符数据(character data)(即文本)的一种特殊形式,其中的文本可以包含< > &等特殊字符而无需转义,但不能包含字符串]]>。例如:
1
<![CDATA[< & > are my favorite delimiters]]>
- 处理指令(processing instruction)是在处理XML文档的应用程序中使用的指令,以
<?和?>为界。例如:
1
<?xml-stylesheet href="mystyle.css" type="text/css"?>
每个XML文档都以下面的处理指令(文档头)开始:
1
<?xml version="1.0"?>
- 注释(comment)以
<!--和-->为界。注释不应该包含字符串--。例如:
1
<!-- This is a comment. -->
3.3 解析XML文档
Java库提供了两种XML解析器:
- 树型解析器(tree parser):将读入的XML文档转换成树结构,如文档对象模型(Document Object Model, DOM)解析器。
- 流式解析器(streaming parser):在读入XML文档时生成相应的事件,如SAX (Simple API for XML)解析器。
注:Java XML处理API (JAXP)官方教程:https://docs.oracle.com/javase/tutorial/jaxp/TOC.html
DOM解析器的接口已经被W3C标准化(https://www.w3.org/TR/DOM-Level-3-Core/)。org.w3c.dom包包含了Document和Element等接口类型的定义,不同的提供者(如Apache和IBM)都编写了实现这些接口的DOM解析器。JDK也附带了一个DOM解析器(在javax.xml.parsers包中)。
为了读取XML文档,需要从DocumentBuilderFactory获得一个DocumentBuilder对象,如下所示:
1
2
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
现在可以从文件读取XML文档:
1
2
File f = ...;
Document doc = builder.parse(f);
也可以使用URL:
1
2
URL u = ...;
Document doc = builder.parse(u.toString());
注:这里的URL是作为字符串传递,也可以是文件名。
还可以指定任意的输入流:
1
2
InputStream in = ...;
Document doc = builder.parse(in);
Document对象是XML文档的树型结构在内存中的表示,它由实现了Node接口及其子接口的对象构成。下图展示了继承层次结构。
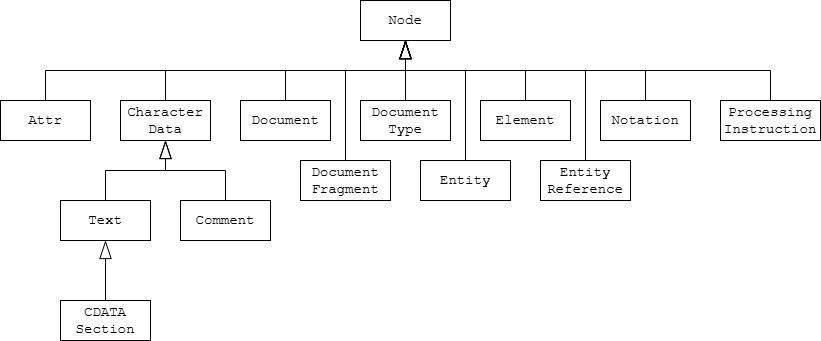
Document.getDocumentElement()方法返回文档的根元素。
1
Element root = doc.getDocumentElement();
Element.getTagName()方法返回元素的标签名。要得到元素的子节点(可能是子元素、文本、注释或其他节点),使用Node.getChildNodes()方法。该方法返回一个NodeList类型的集合,可以如下枚举所有子节点:
1
2
3
4
5
NodeList children = root.getChildNodes();
for (int i = 0; i < children.getLength(); i++) {
Node child = children.item(i);
...
}
分析子节点时要小心空白符问题。例如,对于以下文档
1
2
3
4
<font>
<name>Helvetica</name>
<size>36</size>
</font>
你可能期望font元素有两个子节点,但是解析器报告有5个:
<font>和<name>之间的空白符name元素</name>和<size>之间的空白符size元素</size>和</font>之间的空白符
注:使用getElementsByTagName()获得具有给定标签名的子元素则没有这个问题。
下图展示了其DOM树。
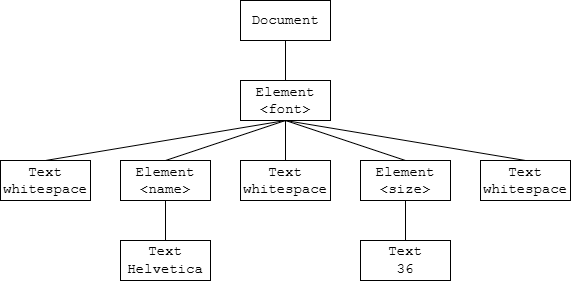
如果只希望得到子元素,可以通过判断子节点类型来忽略空白符:
1
2
3
4
5
6
for (int i = 0; i < children.getLength(); i++) {
Node child = children.item(i);
if (child instanceof Element childElement) {
...
}
}
现在只会看到name和size两个元素。
注:也可以判断child.getNodeType() == Node.ELEMENT_NODE
在下一节将会看到,如果你的文档有DTD,解析器就能知道哪些元素没有文本子节点,并且会剔除空白符。
元素包含的文本字符串(如 “Helvetica” 和 “36” )在Text类型的子节点中。这些Text节点是唯一的子节点,因此可以使用getFirstChild()方法而无需遍历NodeList。然后使用Text.getData()方法获取其中的字符串。
1
2
3
4
5
6
var textNode = (Text) childElement.getFirstChild();
String text = textNode.getData().strip();
if (childElement.getTagName().equals("name"))
name = text;
else if (childElement.getTagName().equals("size"))
size = Integer.parseInt(text);
提示:对getData()的返回值调用strip()或trim()方法是个好主意。如果开始和结束标签在不同的行,结果就会包含所有的换行符和空格。
注:也可以调用getNodeValue()或getTextContent()方法。对于Text节点,二者都等价于getData()。其他类型节点的返回值参见Node接口和getTextContent()方法API文档中的表格。
可以用getLastChild()方法得到最后一个子节点,用getNextSibling()得到下一个兄弟节点。因此,另一种遍历子节点的方法是
1
2
3
4
5
for (Node childNode = element.getFirstChild();
childNode != null;
childNode = childNode.getNextSibling()) {
...
}
要枚举节点的属性,调用getAttributes()方法。它返回一个NamedNodeMap对象,其中包含描述属性的Node对象(实际类型是Attr)。可以如下遍历所有属性:
1
2
3
4
5
6
7
NamedNodeMap attributes = element.getAttributes();
for (int i = 0; i < attributes.getLength(); i++) {
Node attribute = attributes.item(i);
String name = attribute.getNodeName();
String value = attribute.getNodeValue();
...
}
如果知道属性名,可以直接获取相应的值:
1
String unit = element.getAttribute("unit");
程序清单3-1中的程序将一个XML文档转换成JSON格式。
程序清单3-1 dom/JSONConverter.java
3.4 验证XML文档
遍历DOM文档的树结构需要大量繁琐的编程和错误检查。不仅需要处理元素间的空白符,还要检查文档是否包含预期的节点。例如,假设读取下面这个元素:
1
2
3
4
<font>
<name>Helvetica</name>
<size>36</size>
</font>
首先跳过包含空白符的文本节点,找到第一个元素子节点。然后需要检查它的标签名是name并且有一个文本类型的子节点。接下来找到下一个非空白符的子节点并做同样的检查。如果文档作者改变了子元素的顺序或者添加了另一个子元素呢?
XML解析器的一个主要好处是它能自动验证文档是否具有正确的结构,这使得解析变得简单得多。例如,如果知道font元素已经通过了验证,就可以直接得到两个孙节点、将其转换成Text节点并得到文本数据,而无需进一步检查。
为了指定文档结构,可以提供文档类型定义(DTD)或XML Schema定义。DTD或Schema指定了每个元素的合法子元素和属性的规则。例如,以下DTD规则表示“font元素必须有两个子元素,分别是name和size”。
1
<!ELEMENT font (name,size)>
同样的约束用XML Schema表示如下:
1
2
3
4
5
6
<xsd:element name="font">
<xsd:sequence>
<xsd:element name="name" type="xsd:string" />
<xsd:element name="size" type="xsd:int" />
</xsd:sequence>
</xsd:element>
3.4.1 文档类型定义
提供DTD的方式有多种。可以将其包含在XML文档中,如下所示:
1
2
3
4
5
6
7
8
<?xml version="1.0"?>
<!DOCTYPE config [
<!ELEMENT config ...>
more rules...
]>
<config>
...
</config>
规则包含在DOCTYPE声明中,以[]为界。文档类型必须匹配根元素的名字,例如config。
把DTD存储在外部会更有意义。为此可以使用SYSTEM声明,指定一个包含DTD的URL。例如:
1
<!DOCTYPE config SYSTEM "config.dtd">
或者
1
<!DOCTYPE config SYSTEM "http://myserver.com/config.dtd">
警告:如果使用相对URL(如"config.dtd"),那么要给解析器一个File或URL对象(基于文档所在目录解析相对URL),而不是InputStream。如果必须从输入流解析,则提供一个实体解析器(见下面的注释)。
有一种来源于SGML的用于识别“众所周知的”DTD的机制。例如:
1
2
3
<!DOCTYPE web-app
PUBLIC "-//Sun Microsystems, Inc.//DTD Web Application 2.2//EN"
"http://java.sun.com/j2ee/dtds/web-app_2_2.dtd">
如果XML处理器知道如何定位带有公共标识符的DTD,就不需要URL了。
注释:DTD的系统标识符URL可能实际无法工作,或者被故意降速。解决方法是使用实体解析器(entity resolver)将公共标识符映射为本地文件。在Java 9之前,必须为DocumentBuilder提供一个实现了EntityResolver接口的对象。现在可以使用XML目录(XML catalog)来管理这种映射,提供一个或多个具有如下形式的目录文件。
1
2
3
4
5
6
7
<?xml version="1.0"?>
<!DOCTYPE catalog PUBLIC "-//OASIS//DTD XML Catalogs V1.0//EN"
"http://www.oasisopen.org/committees/entity/release/1.0/catalog.dtd">
<catalog xmlns="urn:oasis:names:tc:entity:xmlns:xml:catalog" prefer="public">
<public publicId="..." uri="..."/>
...
</catalog>
然后像下面这样构造并安装实体解析器:
1
2
3
builder.setEntityResolver(CatalogManager.catalogResolver(
CatalogFeatures.defaults(),
Path.of("catalog.xml").toAbsolutePath().toUri()));
除了在程序中设置目录文件位置,还可以在命令行中用javax.xml.catalog.files系统属性来指定,提供由分号分隔的文件绝对URL。
下面来看不同种类的规则。ELEMENT规则指定元素可以有什么样的子节点,使用如下表所示的正则表达式。
| 规则 | 含义 |
|---|---|
E* | 0或多个E |
E+ | 1或多个E |
E? | 0或1个E |
(E1|E2|...|En) | E1, E2, …, En之一 |
(E1,E2,...,En) | 依次E1, E2, …, En |
(#PCDATA) | 文本(parsed character data) |
(#PCDATA|E1|E2|...|En)* | 混合式内容(0个或多个文本和E1, E2, …, En以任意顺序排列) |
ANY | 允许任意子节点 |
EMPTY | 不允许有子节点 |
例如,下面的规则声明menu元素包含0个或多个item元素:
1
<!ELEMENT menu (item)*>
下面这组规则声明font包含一个name和一个size,二者都包含文本:
1
2
3
<!ELEMENT font (name,size)>
<!ELEMENT name (#PCDATA)>
<!ELEMENT size (#PCDATA)>
规则可以包含嵌套的正则表达式。例如,下面的规则描述了一本书的章节构成:每章以简介开头,其后是一个或多个小节,每个小节由标题和一个或多个段落、图片、表格或注释构成。
1
<!ELEMENT chapter (intro,(heading,(para|image|table|note)+)+)>
当一个元素可以包含文本时,只有两种合法的情况。要么该元素只包含文本,比如
1
<!ELEMENT name (#PCDATA)>
要么该元素包含文本和标签的任意组合,比如
1
<!ELEMENT para (#PCDATA|em|strong|code)*>
指定其他类型的包含#PCDATA的规则都是非法的,例如:
1
<!ELEMENT captionedImage (image,#PCDATA)>
这种限制简化了XML解析器在解析混合式内容时的工作。最好在设计DTD时让所有元素要么包含其他元素,要么只包含文本。
注释:实际上,在DTD规则中并不能指定任意的正则表达式。XML解析器可能会拒绝某些导致非确定性解析的复杂规则。例如,正则表达式((x,y)|(x,z))是非确定性的(当解析器看到x时,不知道应该选择两种形式中的哪一个)。这个表达式可以改写成确定性的形式(x,(y|z))。然而,有些表达式无法改写,如((x,y)*|x?)。Java XML库中的解析器在遇到有歧义的DTD时不会给出警告,而是直接选择第一个匹配的形式,这会导致它拒绝一些正确的输入。XML标准允许解析器假设DTD是无歧义的。
还可以指定用于描述元素的合法属性的规则,语法为
1
<!ATTLIST element attribute type default>
下表显示了合法的属性类型(type)。
| 类型 | 含义 |
|---|---|
CDATA | 任意字符串 |
(A1|A2|...|An) | 字符串属性A1, A2, …, An之一 |
ID | 唯一ID |
IDREF, IDREFS | 一个或多个唯一ID的引用 |
ENTITY, ENTITIES | 一个或多个未解析实体 |
NMTOKEN, NMTOKENS | 一个或多个名字符号 |
下表显示了默认值(default)的语法。
| 默认值 | 含义 |
|---|---|
#REQUIRED | 属性是必需的 |
#IMPLIED | 属性是可选的 |
A | 属性是可选的,如果未指定则默认值为A |
#FIXED A | 属性必须未指定或者是A,如果未指定则默认值也为A |
下面是两个典型的属性规则:
1
2
<!ATTLIST font style (plain|bold|italic|bold-italic) "plain">
<!ATTLIST size unit CDATA #IMPLIED>
第一条规则描述了font元素的style属性,有4个合法的属性值,默认值是plain。第二条规则表示size元素的unit属性可以包含任意字符串。
注释:通常推荐使用元素而不是属性来描述数据。然而,属性对于枚举类型有一个优点,即解析器能够检查它是否是允许的值之一,并在未指定时提供默认值。
CDATA属性值的处理与#PCDATA有微妙的差别,与<![CDATA[...]]>部分完全无关。属性值会先被规范化(normalized)——解析器会处理字符引用和实体引用(如é或<),并将空白符替换为空格。
NMTOKEN(name token,名字符号)与CDATA类似,但不允许使用大多数非字母数字字符和内部空白符,并且解析器会删除开头和结尾的空白符。NMTOKENS是空白符分隔的名字符号列表(如<p class="text highlight">)。
ID是在文档中唯一的名字符号,解析器会检查其唯一性(如<input id="name" ...>)。IDREF是同一文档中已有ID的引用(如<label for="name">),解析器也会对其进行检查。IDREFS是空白符分隔的ID引用列表。
ENTITY引用“未解析的外部实体”。这是从SGML遗留下来的,在实际中很少使用。
DTD也可以定义实体(entity),即在解析过程中被替换的缩写。例如:
1
<!ENTITY back.label "Back">
其他地方的文本可以包含实体引用,例如:
1
<menuitem label="&back.label;"/>
解析器会将实体引用替换为对应的字符串。例如,要使应用程序国际化,只需修改实体定义中的字符串。实体的其他用途更复杂、不太常见。
现在可以配置解析器以充分利用DTD。首先,告诉DocumentBuilderFactory对象开启验证:
1
factory.setValidating(true);
要忽略文本节点中的空白符,调用
1
factory.setIgnoringElementContentWhitespace(true);
这样,对于3.4节开头的XML元素,可以依赖font节点只有两个子节点这一事实。不必再编写这样冗长的循环:
1
2
3
4
5
6
7
for (int i = 0; i < children.getLength(); i++) {
Node child = children.item(i);
if (child instanceof Element childElement) {
if (childElement.getTagName().equals("name")) ...;
else if (childElement.getTagName().equals("size")) ...;
}
}
而是可以直接访问第一个和第二个子节点:
1
2
var nameElement = (Element) children.item(0);
var sizeElement = (Element) children.item(1);
当解析器报告错误时,你希望程序执行某些操作(例如记录日志,显示给用户,或者抛出异常)。因此,使用验证时应该安装错误处理器。这需要提供一个实现了ErrorHandler接口的对象,这个接口有三个方法:
1
2
3
void warning(SAXParseException e)
void error(SAXParseException e)
void fatalError(SAXParseException e)
使用DocumentBuilder类的setErrorHandler()方法安装错误处理器:
1
builder.setErrorHandler(handler);
3.4.2 XML Schema
XML Schema比DTD语法复杂得多,因此只介绍基础知识。更多信息参见 https://www.w3.org/TR/xmlschema-0/ 。
要在文档中引用Schema文件,需要在根元素中添加属性,例如:
1
2
3
4
5
<?xml version="1.0"?>
<config xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="config.xsd">
...
</config>
Schema文件为每个元素和属性都定义了类型。简单类型是字符串(可能有内容限制),其他都是复杂类型。简单类型的元素可以没有属性和子元素,否则它必须是复杂类型。属性总是简单类型。
XML Schema内置了一些简单类型,包括xsd:string、xsd:int和xsd:boolean。
注释:我们用前缀xsd:表示XML Schema定义命名空间。有些作者使用前缀xs:。
可以自定义简单类型。例如,下面是一个枚举类型:
1
2
3
4
5
6
7
8
<xsd:simpleType name="StyleType">
<xsd:restriction base="xsd:string">
<xsd:enumeration value="PLAIN" />
<xsd:enumeration value="BOLD" />
<xsd:enumeration value="ITALIC" />
<xsd:enumeration value="BOLD_ITALIC" />
</xsd:restriction>
</xsd:simpleType>
定义元素时,要指定其类型:
1
2
3
<xsd:element name="name" type="xsd:string"/>
<xsd:element name="size" type="xsd:int"/>
<xsd:element name="style" type="StyleType"/>
类型限制了元素内容。例如,元素<size>default</size>将验证失败。
可以把类型组合成复杂类型,例如:
1
2
3
4
5
6
7
<xsd:complexType name="FontType">
<xsd:sequence>
<xsd:element ref="name" />
<xsd:element ref="size" />
<xsd:element ref="style" />
</xsd:sequence>
</xsd:complexType>
FontType是name、size和style元素的序列。在这个类型定义中使用了ref属性来引用别处的定义。也可以嵌套定义,如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
<xsd:complexType name="FontType">
<xsd:sequence>
<xsd:element name="name" type="xsd:string" />
<xsd:element name="size" type="xsd:int" />
<xsd:element name="style">
<xsd:simpleType>
<xsd:restriction base="xsd:string">
<xsd:enumeration value="PLAIN" />
<xsd:enumeration value="BOLD" />
<xsd:enumeration value="ITALIC" />
<xsd:enumeration value="BOLD_ITALIC" />
</xsd:restriction>
</xsd:simpleType>
</xsd:element>
</xsd:sequence>
注意style元素的匿名类型定义。
xsd:sequence结构等价于DTD中的拼接(,),而xsd:choice等价于选择(|)。例如,
1
2
3
4
5
6
<xsd:complexType name="contactinfo">
<xsd:choice>
<xsd:element ref="email" />
<xsd:element ref="phone" />
</xsd:choice>
</xsd:complexType>
等价于DTD类型email|phone。
为了允许重复的元素,使用minoccurs和maxoccurs属性。例如,与DTD类型item*等价的形式如下:
1
<xsd:element name="item" type="..." minoccurs="0" maxoccurs="unbounded">
要指定属性,需要将xsd:attribute元素添加到complexType定义中:
1
2
3
4
5
6
<xsd:element name="size">
<xsd:complexType>
...
<xsd:attribute name="unit" type="xsd:string" use="optional" default="cm" />
</xsd:complexType>
</xsd:element>
这等价于下面的DTD语句:
1
<!ATTLIST size unit CDATA #IMPLIED "cm">
把Schema的元素和类型定义放在根元素xsd:schema中:
1
2
3
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema">
...
</xsd:schema>
解析带有Schema的XML文件与解析带有DTD的文件类似,但有两点区别:
1.必须打开对命名空间的支持,即使在XML文件中并没有用到它
1
factory.setNamespaceAware(true);
2.必须设置以下工厂属性来处理Schema
1
2
3
final String JAXP_SCHEMA_LANGUAGE = "http://java.sun.com/xml/jaxp/properties/schemaLanguage";
final String W3C_XML_SCHEMA = "http://www.w3.org/2001/XMLSchema";
factory.setAttribute(JAXP_SCHEMA_LANGUAGE, W3C_XML_SCHEMA);
3.4.3 一个实际的例子
在本节中,将通过一个实际的例子来展示XML在现实环境中的使用。
假设一个应用程序需要配置数据,这些数据可以指定任意对象,而不只是文本字符串(注:即简化的Spring Bean配置)。我们提供两种机制来实例化对象:构造器和工厂方法。下面展示了如何使用构造器来创建Color对象:
1
2
3
4
5
<construct class="java.awt.Color">
<int>55</int>
<int>200</int>
<int>100</int>
</construct>
注:等价于new java.awt.Color(55, 200, 100)
下面是使用工厂方法的例子:
1
2
3
<factory class="java.util.logging.Logger" method="getLogger">
<string>com.horstmann.corejava</string>
</factory>
注:等价于java.util.logging.Logger.getLogger("com.horstmann.corejava")
如果省略工厂方法名,则默认为getInstance。
配置(config)是一系列的条目(entry)。每个条目有一个ID(属性)和一个对象(上述两种描述之一)。
1
2
3
4
5
6
7
8
9
10
<config>
<entry id="background">
<construct class="java.awt.Color">
<int>55</int>
<int>200</int>
<int>100</int>
</construct>
</entry>
...
</config>
程序清单3-2中的程序展示了如何解析配置文件。如果选择的文件名包含字符串 “-schema” ,则程序会使用Schema,否则使用DTD。程序清单3-3包含示例配置。DTD在程序清单3-4中。程序清单3-5包含了等价的Schema(注意这里使用了xsd:group结构来定义会反复使用的复杂类型的各个部分)。
3.5 使用XPath定位信息
如果想在XML文档中定位一段特定信息,浏览DOM树的节点会有点麻烦。XPath使访问树节点变得很容易。
XPath可以描述XML文档中的一个节点集合。例如,XPath表达式/html/body/form描述了XHTML文件中body元素的子节点中所有form元素的集合。
可以用[]运算符选择特定的元素。例如,/html/body/form[1]是第一个form(索引从1开始)。
使用@运算符得到属性值。例如,/html/body/form[1]/@action描述了第一个表单的action属性,/html/body/form/@action描述了body元素的子节点中所有form元素的所有action属性节点。
XPath有很多有用的函数。例如,count(/html/body/form)返回body元素的form子元素的数量。
更多语法参见XPath规范 https://www.w3.org/TR/xpath/ 或者在线教程 http://www.zvon.org/xxl/XPathTutorial/General/examples.html 。
为了计算XPath表达式,首先从XPathFactory创建一个XPath对象:
1
2
XPathFactory xpfactory = XPathFactory.newInstance();
XPath path = xpfactory.newXPath();
然后调用evaluate()方法来计算XPath表达式:
1
String username = path.evaluate("/html/head/title/text()", doc);
可以使用同一个XPath对象计算多个表达式。
这种形式的evaluate()方法返回一个字符串,适合用来获取文本(比如前面的例子中title元素的文本子节点)。如果XPath表达式生成多个节点,则调用
1
XPathNodes result = path.evaluateExpression("/html/body/form", doc, XPathNodes.class);
XPathNodes与NodeList类似,但是它实现了Iterable接口,因此可以使用for each循环。这个方法是在Java 9中添加的,在旧版本中,需要使用以下调用:
1
var nodes = (NodeList) path.evaluate("/html/body/form", doc, XPathConstants.NODESET);
如果结果是单个节点,则使用下面的调用之一:
1
2
Node node = path.evaluateExpression("/html/body/form[1]", doc, Node.class);
node = (Node) path.evaluate("/html/body/form[1]", doc, XPathConstants.NODE);
如果结果是一个数字,则使用
1
2
int count = path.evaluateExpression("count(/html/body/form)", doc, Integer.class);
count = ((Number) path.evaluate("count(/html/body/form)", doc, XPathConstants.NUMBER)).intValue();
不必从文档的根节点开始搜索,可以从任意节点或节点列表开始。例如,如果有前一次计算得到的节点,那么可以调用
1
String result = path.evaluate(expression, node);
如果不知道XPath表达式的计算结果是什么(可能来自用户),则调用
1
XPathEvaluationResult<?> result = path.evaluateExpression(expression, doc);
result.type()是下列XPathEvaluationResult.XPathResultType枚举常量之一,调用result.value()获得结果值。
1
STRING NODESET NODE NUMBER BOOLEAN
程序清单3-6中的程序演示了任意XPath表达式的计算。
3.6 使用命名空间
Java语言使用包来避免命名冲突。XML有类似的命名空间(namespace)机制,可用于元素名和属性名。
命名空间是由URI标识的,例如
1
2
3
http://www.w3.org/2001/XMLSchema
uuid:1c759aed-b748-475c-ab68-10679700c4f2
urn:com:books-r-us
HTTP URL格式是最常见的,因为这样容易确保其唯一性。注意,这里的URL只用作标识符字符串,而不是文档定位符。例如,标识符
1
2
http://www.horstmann.com/corejava
http://www.horstmann.com/corejava/index.html
表示不同的命名空间,尽管Web服务器会为这两个URL提供同一个网页。
命名空间URL所表示的位置不需要有任何文档,XML解析器不会去该处查找任何东西。不过,习惯上会将解释命名空间目的的文档放在URL位置上。例如,如果在浏览器访问XML Schema的命名空间URL (http://www.w3.org/2001/XMLSchema),就会发现一个描述XML Schema标准的文档。
在Java中,可以用import机制省略类的包名。在XML中有类似的机制:
1
2
3
<element xmlns="namespaceURI">
children
</element>
现在,该元素及其子元素都属于给定命名空间。
子元素可以提供自己的命名空间,例如:
1
2
3
4
5
6
<element xmlns="namespaceURI1">
<child xmlns="namespaceURI2">
grandchildren
</child>
more children
</element>
这样child及其子节点都属于命名空间2。
还有第二种机制,可以使用一个前缀来表示命名空间,即为特定文档选择的一个短标识符。下面是一个典型的例子,XML Schema文件中的xsd前缀:
1
2
3
4
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<xsd:element name="config"/>
...
</xsd:schema>
属性xmlns:prefix="namespaceURI"定义了一个命名空间和前缀。在这个例子中,前缀是xsd,从而xsd:schema意味着命名空间 http://www.w3.org/2001/XMLSchema 中的schema。
注释:只有子元素会继承父元素的命名空间,而不带显式前缀的属性并不属于命名空间。例如:
1
2
3
4
5
<configuration xmlns="http://www.horstmann.com/corejava"
xmlns:si="http://www.bipm.fr/enus/3_SI/si.html">
<size value="210" si:unit="mm" />
...
</configuration>
在这个示例中,元素configuration和size属于命名空间 http://www.horstmann.com/corejava ,属性si:unit属于命名空间 http://www.bipm.fr/enus/3_SI/si.html ,但是属性value不属于任何命名空间。
默认情况下,Java XML库的DOM解析器不感知命名空间。要开启命名空间处理,调用DocumentBuilderFactory类的setNamespaceAware()方法:
1
2
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
factory.setNamespaceAware(true);
这样,该工厂产生的所有DocumentBuilder都支持命名空间。
从Java 13起,也可以调用
1
DocumentBuilderFactory factory = DocumentBuilderFactory.newNSInstance();
每个节点都有三个属性:
- 限定名(qualified name),带有前缀,由
getNodeName()和getTagName()等方法返回。 - 命名空间URI,由
getNamespaceURI()方法返回。 - 局部名(local name),不带前缀和命名空间,由
getLocalName()方法返回。
例如,对于以下元素:
1
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema">
- 限定名 =
xsd:schema - 命名空间URI = http://www.w3.org/2001/XMLSchema
- 局部名 =
schema
注释:如果未开启命名空间感知,getNamespaceURI()和getLocalName()将返回null。
3.7 流式解析器
DOM解析器会读入整个XML文档,并转换成树结构。但是,如果文档很大,而处理算法无需看到整个树结构,就会显得效率低下。在这种情况下,应该使用流式解析器。
下面几节将讨论Java库提供的流式解析器:SAX解析器和StAX解析器。前者使用事件回调,而后者提供了遍历解析事件的迭代器。
3.7.1 使用SAX解析器
SAX解析器在解析XML输入时报告事件,但不会以任何方式存储文档。使用SAX解析器时,需要提供一个处理器(handler)来为各种解析事件定义动作。ContentHandler接口定义了几个回调方法,解析器在解析文档时会调用这些方法。下面是最重要的几个:
startElement()和endElement():遇到开始和结束标签时调用characters():遇到字符数据时调用startDocument()和endDocument():遇到文档开始和结束时调用
例如,在解析以下片段时
1
2
3
4
<font>
<name>Helvetica</name>
<size unit="pt">36</size>
</font>
解析器会产生以下回调:
startElement(),元素名:fontstartElement(),元素名:namecharacters(),内容:HelveticaendElement(),元素名:namestartElement(),元素名:size,属性:unit="pt"characters(),内容:36endElement(),元素名:sizeendElement(),元素名:font
本节结尾的程序会打印出HTML文件中的所有链接<a href="...">。这可用于实现“网络爬虫”(web crawler),即沿着链接到达越来越多网页的程序。
注释:HTML不一定的合法的XML。许多网页与合法的XML差距太大,以至于示例程序可能无法解析。不过,W3C的大部分网页都是用XHTML(一种是合法XML的HTML方言)编写的,可以用这些网页来测试示例程序。例如:
1
java sax.SAXTest https://www.w3.org/
可以像这样得到SAX解析器:
1
2
SAXParserFactory factory = SAXParserFactory.newInstance();
SAXParser parser = factory.newSAXParser();
现在可以处理文档:
1
parser.parse(source, handler);
其中source可以是文件、URL字符串或输入流,handler属于DefaultHandler的某个子类。DefaultHandler类为以下四个接口定义了不执行任何操作的方法:
1
2
3
4
ContentHandler
DTDHandler
EntityResolver
ErrorHandler
示例程序定义了一个处理器,覆盖了ContentHandler接口的startElement()方法,以寻找带有href属性的a元素。
1
2
3
4
5
6
7
8
9
10
11
12
var handler = new DefaultHandler() {
public void startElement(String namespaceURI, String lname, String qname, Attributes attrs)
throws SAXException {
if (lname.equals("a") && attrs != null) {
for (int i = 0; i < attrs.getLength(); i++) {
String aname = attrs.getLocalName(i);
if (aname.equals("href"))
System.out.println(attrs.getValue(i));
}
}
}
};
startElement()方法有三个描述元素名的参数(见3.6节)。qname参数是限定名,形式为prefix:localname。如果开启了命名空间处理,则namespaceURI和lname参数提供命名空间URI和局部名。
与DOM解析器一样,命名空间处理默认是关闭的。要开启处理,调用工厂类的setNamespaceAware(true)方法。或者从Java 13起,可以用newNSInstance()创建感知命名空间的工厂:
1
2
SAXParserFactory factory = SAXParserFactory.newNSInstance();
SAXParser saxParser = factory.newSAXParser();
如果不需要验证文档,只需调用
1
factory.setFeature("http://apache.org/xml/features/nonvalidating/load-external-dtd", false);
程序清单3-7包含网络爬虫程序的代码。
3.7.2 使用StAX解析器
StAX (Streaming API for XML)解析器是一种“拉式解析器”(pull parser)。只需使用以下基本循环来迭代事件,而不是安装事件处理器:
1
2
3
4
5
6
7
InputStream in = url.openStream();
XMLInputFactory factory = XMLInputFactory.newInstance();
XMLStreamReader parser = factory.createXMLStreamReader(in);
while (parser.hasNext()) {
int event = parser.next();
// Call parser methods to obtain event details
}
例如,在解析以下片段时
1
2
3
4
<font>
<name>Helvetica</name>
<size unit="pt">36</size>
</font>
解析器会产生以下事件:
START_ELEMENT,元素名:fontCHARACTERS,内容:空白符START_ELEMENT,元素名:nameCHARACTERS,内容:HelveticaEND_ELEMENT,元素名:nameCHARACTERS,内容:空白符START_ELEMENT,元素名:size,属性:unit="pt"CHARACTERS,内容:36END_ELEMENT,元素名:sizeCHARACTERS,内容:空白符END_ELEMENT,元素名:font
注:这些事件类型常量定义在XMLStreamConstants接口中。对于每种类型的事件可调用的解析器方法参见XMLStreamReader类API文档中的表格。
要得到属性值,调用XMLStreamReader类的getAttributeValue()方法,例如:
1
String units = parser.getAttributeValue(null, "units");
默认情况下,命名空间处理是开启的,可以像这样关闭:
1
factory.setProperty(XMLInputFactory.IS_NAMESPACE_AWARE, false);
程序清单3-8包含用StAX解析器实现的网络爬虫程序。
3.8 生成XML文档
下面介绍如何产生XML输出。当然,可以直接通过一系列print调用打印出元素、属性和文本内容,但代码会非常冗长,而且容易出错。
一种更好的方式是用文档内容构建DOM树,然后再写出其内容。
3.8.1 无命名空间的文档
要构建DOM树,需要从空文档开始。通过调用DocumentBuilder类的newDocument()方法得到一个空文档:
1
2
3
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
Document doc = builder.newDocument();
使用Document类的createElement()方法创建元素:
1
2
Element rootElement = doc.createElement(rootName);
Element childElement = doc.createElement(childName);
使用createTextNode()方法创建文本节点:
1
Text textNode = doc.createTextNode(textContents);
使用appendChild()方法将根元素添加到文档,子节点添加到父节点:
1
2
3
doc.appendChild(rootElement);
rootElement.appendChild(childElement);
childElement.appendChild(textNode);
可以使用Element类的setAttribute()方法设置元素属性:
1
rootElement.setAttribute(name, value);
3.8.2 有命名空间的文档
如果使用命名空间,创建文档的过程会稍有差异。
首先,将工厂设置为命名空间感知的(与解析时一样),然后创建DocumentBuilder:
1
2
factory.setNamespaceAware(true);
DocumentBuilder builder = factory.newDocumentBuilder();
然后使用createElementNS()而不是createElement()方法创建元素:
1
2
String namespace = "http://www.w3.org/2000/svg";
Element rootElement = doc.createElementNS(namespace, "svg");
如果元素具有带命名空间前缀的限定名,那么所有必要的带xmlns前缀的属性都会被自动创建。例如,如果需要在XHTML中包含SVG,可以像这样创建元素:
1
Element svgElement = doc.createElement(namespace, "svg:svg")
当元素被写出时,会转换为
1
<svg:svg xmlns:svg="http://www.w3.org/2000/svg">
如果需要设置名字位于命名空间中的属性,使用Element类的setAttributeNS()方法:
1
rootElement.setAttributeNS(namespace, qualifiedName, value);
3.8.3 写出文档
将DOM树写到输出流并非易事。最容易的方式是使用XSL转换API,将在下一节介绍。本节考虑直接生成XML输出。
将不做任何操作的转换应用于文档,并捕获其输出。为了在输出中包含DOCTYPE节点,还需要将SYSTEM和PUBLIC标识符设置为输出属性。
1
2
3
4
5
6
7
8
9
10
11
// construct the do-nothing transformation
Transformer t = TransformerFactory.newInstance().newTransformer();
// set output properties to get a DOCTYPE node
t.setOutputProperty(OutputKeys.DOCTYPE_SYSTEM, systemIdentifier);
t.setOutputProperty(OutputKeys.DOCTYPE_PUBLIC, publicIdentifier);
// set indentation
t.setOutputProperty(OutputKeys.INDENT, "yes");
t.setOutputProperty(OutputKeys.METHOD, "xml");
t.setOutputProperty("{http://xml.apache.org/xslt}indent-amount", "2");
// apply the do-nothing transformation and send the output to a file
t.transform(new DOMSource(doc), new StreamResult(new FileOutputStream(file)));
另一种方式是使用LSSerializer接口。像这样获得实例:
1
2
3
DOMImplementation impl = doc.getImplementation();
var implLS = (DOMImplementationLS) impl.getFeature("LS", "3.0");
LSSerializer ser = implLS.createLSSerializer();
如果需要空格和换行,设置以下标志:
1
ser.getDomConfig().setParameter("format-pretty-print", true);
然后将文档转换为字符串:
1
String str = ser.writeToString(doc);
如果想直接将输出写到文件中,则需要LSOutput:
1
2
3
4
LSOutput out = implLS.createLSOutput();
out.setEncoding("UTF-8");
out.setByteStream(Files.newOutputStream(path));
ser.write(doc, out);
3.8.4 使用StAX写出XML文档
通过DOM树写出XML文档的方式不是很高效。
StAX API可以直接写出XML树。首先从输出流构造一个XMLStreamWriter:
1
2
XMLOutputFactory factory = XMLOutputFactory.newInstance();
XMLStreamWriter writer = factory.createXMLStreamWriter(out);
要产生XML文档头,调用writer.writeStartDocument()。
调用writeStartElement(name)添加元素,writeAttribute(name, value)添加属性,writeCharacters(text)添加文本。写完所有子节点之后,调用writeEndElement(),这会关闭当前元素。
要写出没有子节点的元素(如<img .../>),调用writeEmptyElement(name)。
最后,在文档结尾调用writeEndDocument(),这会关闭所有打开的元素。
你需要手动关闭XMLStreamWriter,因为该接口没有扩展AutoCloseable接口。
与DOM/XSLT方式一样,你不必担心属性值和字符数据中的转义字符。但是,仍然有可能产生非良构的XML,例如有多个根节点的文档。另外,当前版本的StAX还不支持产生缩进输出。
3.8.5 示例:生成SVG文件
程序清单3-9中的程序展示了写出XML的两种方式:DOM和StAX。
程序清单3-9 write/XMLWriteTest.java
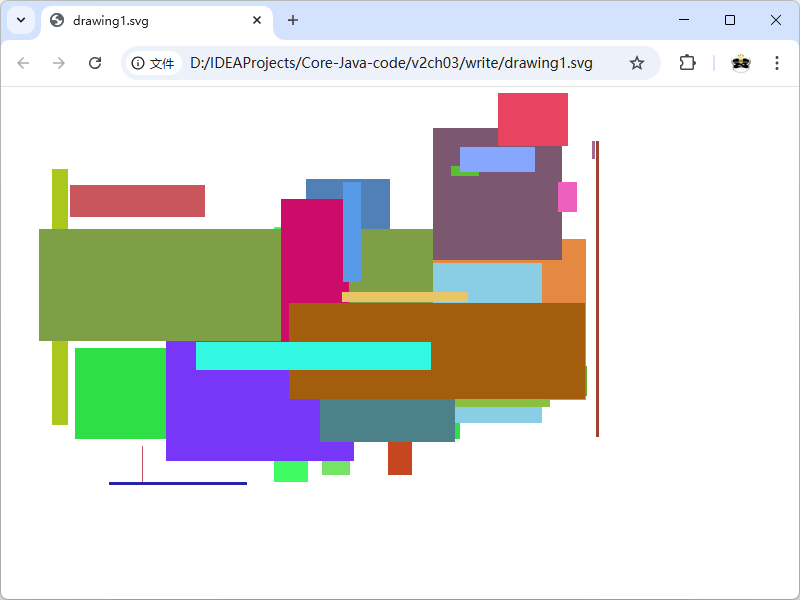
该程序绘制了一幅现代派绘画——一组随机的彩色矩形(如下图所示)。我们使用可缩放矢量图形(Scalable Vector Graphics, SVG)格式保存作品。SVG是一种XML格式,用于以设备无关的方式描述复杂图形。关于SVG的更多信息参见 https://www.w3.org/Graphics/SVG/ 。要查看SVG文件,只需使用任何现代浏览器。
下面是一个使用SVG表示一组彩色矩形的例子:
1
2
3
4
5
6
7
8
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE svg PUBLIC "-//W3C//DTD SVG 20000802//EN"
"http://www.w3.org/TR/2000/CR-SVG-20000802/DTD/svg-20000802.dtd">
<svg xmlns="http://www.w3.org/2000/svg" width="300" height="150">
<rect x="231" y="61" width="9" height="12" fill="#6e4a13" />
<rect x="107" y="106" width="56" height="5" fill="#c406be" />
...
</svg>
3.9 XSL转换
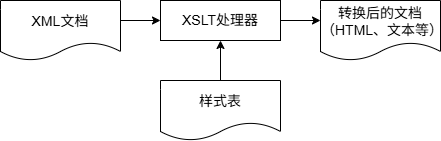
XSL转换(Extensible Stylesheet Language Transformation, XSLT)机制可以指定用于将XML文档转换为其他格式的规则,例如纯文本、XHTML或任何其他XML格式。
你需要提供XSLT样式表。XSLT处理器读取XML文档和这个样式表,并产生所需的输出(如下图所示)。
XSLT规范很复杂,可以在 https://www.w3.org/TR/xslt/ 获得。
下面介绍一个有代表性的例子。假设我们想要把包含员工记录的XML文件转换成HTML页面。对于输入文件:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
<staff>
<employee>
<name>Carl Cracker</name>
<salary>75000.0</salary>
<hiredate year="1987" month="12" day="15" />
</employee>
<employee>
<name>Harry Hacker</name>
<salary>50000.0</salary>
<hiredate year="1989" month="10" day="1" />
</employee>
<employee>
<name>Tony Tester</name>
<salary>40000.0</salary>
<hiredate year="1990" month="3" day="15" />
</employee>
</staff>
希望的输出是一张HTML表格:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
<table border="1">
<tr>
<td>Carl Cracker</td>
<td>$75000.0</td>
<td>1987-12-15</td>
</tr>
<tr>
<td>Harry Hacker</td>
<td>$50000.0</td>
<td>1989-10-1</td>
</tr>
<tr>
<td>Tony Tester</td>
<td>$40000.0</td>
<td>1990-3-15</td>
</tr>
</table>
包含转换模板的样式表(stylesheet)形式如下:
1
2
3
4
5
6
7
<?xml version="1.0" encoding="ISO-8859-1"?>
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="1.0">
<xsl:output method="html" />
template1
template2
...
</xsl:stylesheet>
注:XSL转换类似于Django的模板渲染,只是数据来自XML文件而不是Django视图,样式表相当于Django模板,结果都是渲染后的HTML页面。
在这个例子中,xsl:output元素将method指定为html。其他合法的设置包括xml和text。
下面是一个典型的模板:
1
2
3
<xsl:template match="/staff/employee">
<tr><xsl:apply-templates/></tr>
</xsl:template>
xsl:template的match属性的值是一个XPath表达式。该模板声明,每当遇到XPath /staff/employee描述的节点时,执行以下操作:
- 产生字符串
<tr>。 - 在处理其子节点时继续应用模板。
- 处理完所有子节点后产生字符串
</tr>。
换句话说,该模板生成每条员工记录周围的HTML表格行标签。
XSLT处理器从根元素开始处理。每当一个节点匹配某个模板时,就应用该模板(如果匹配多个模板,就使用最佳匹配的)。如果没有匹配的模板,处理器会执行默认动作:对于文本节点,将其内容包含到输出中;对于元素,不产生输出,但继续处理其子节点。
下面是用于转换员工name节点的模板:
1
2
3
<xsl:template match="/staff/employee/name">
<td><xsl:apply-templates/></td>
</xsl:template>
模板产生标签<td>...</td>,处理器会访问文本子节点并产生其内容(前提是没有其他匹配的模板)。
如果要把属性值复制到输出,需要使用xsl:value-of。下面是一个例子:
1
2
3
<xsl:template match="/staff/employee/hiredate">
<td><xsl:value-of select="@year"/>-<xsl:value-of select="@month"/>-<xsl:value-of select="@day"/></td>
</xsl:template>
xsl:value-of用于计算节点集的字符串值,节点集由select属性的XPath指定。在这里,XPath是相对于当前处理的节点。通过拼接所有节点的字符串值,将节点集转换为字符串。对于属性节点,字符串值就是属性值;对于文本节点是其内容;对于元素节点是其所有子节点(不包括属性)字符串值的拼接。
程序清单3-10包含将员工记录XML文件转换成HTML表格的样式表。
程序清单3-10 transform/makehtml.xsl
程序清单3-11展示了一种不同的转换,输出是属性文件格式的纯文本:
1
2
3
4
5
6
7
8
9
employee.1.name=Carl Cracker
employee.1.salary=75000.0
employee.1.hiredate=1987-12-15
employee.2.name=Harry Hacker
employee.2.salary=50000.0
employee.2.hiredate=1989-10-1
employee.3.name=Tony Tester
employee.3.salary=40000.0
employee.3.hiredate=1990-3-15
程序清单3-11 transform/makeprop.xsl
这个示例使用了position()函数,该函数返回当前节点在父节点中的位置。只要切换样式表就可以得到完全不同的输出。
在Java中生成XSL转换很简单。为每个样式表设置一个转换器工厂,然后得到一个转换器对象,并将一个源转换成结果:
1
2
3
4
var styleSheet = new File(filename);
var styleSource = new StreamSource(styleSheet);
Transformer t = TransformerFactory.newInstance().newTransformer(styleSource);
t.transform(source, result);
transform()方法的参数分别是实现了Source和Result接口的对象。
Source接口有4个实现类:DOMSource, SAXSource, StAXSource, StreamSource。例如,在上一节中调用了如下的恒等转换:
1
t.transform(new DOMSource(doc), result);
在本节的示例程序中,并不是读取现有的XML文件,而是实现了一个SAX XML读取器EmployeeReader,通过产生适当的事件来给人一种解析XML文件的错觉。实际上读取的是一个文本文件,如下所示:
1
2
3
Carl Cracker|75000.0|1987|12|15
Harry Hacker|50000.0|1989|10|1
Tony Tester|40000.0|1990|3|15
例如,对于每一行,生成employee的startElement事件;对于每个字段,生成characters事件。
转换器的源是从XML读取器构造的:
1
t.transform(new SAXSource(new EmployeeReader(), new InputSource(new FileInputStream(filename))), result);
这是一个将非XML的遗留数据转换成XML的技巧。当然,大多数XSLT应用程序读取的都是XML格式的输入数据,只需使用StreamSource()即可:
1
t.transform(new StreamSource(file), result);
转换结果是一个实现了Result接口的对象,Java库提供了4个实现类:DOMResult, SAXResult, StAXResult, StreamResult。
要把结果存储到DOM树中,生成一个新的文档并将其包装到DOMResult中:
1
2
Document doc = builder.newDocument();
t.transform(source, new DOMResult(doc));
要将输出保存到文件中,使用StreamResult:
1
t.transform(source, new StreamResult(file));
程序清单3-12包含完整的代码。