《Java核心技术》笔记 卷II 第7章 国际化
在本章中,将介绍如何编写国际化的Java程序,以及如何将日期、时间、数字、文本和GUI本地化。还将介绍Java为编写国际化程序提供的工具。最后以一个完整的例子来结束本章——一个带有英语、德语和中文用户界面的退休计算器。
7.1 Locale
7.1.1 为什么需要Locale
当你提供程序的国际化版本时,所有程序消息都需要翻译成本地语言。但是,只翻译用户界面文本是不够的,还有许多更细微的差异。例如,数字在英语和德语中的格式非常不同。对于德国用户,数字123,456.78应该显示为123.456,78——小数点和千位分隔符是相反的。在日期显示上也有类似的变化。在美国,日期显示为月/日/年,德国使用日/月/年,而中国则使用年/月/日。因此,对于德国用户,日期3/22/61应该表示为22.03.1961。
区域设置(locale)描述了像上面这类的本地偏好。每当展示数字、日期、货币值和其他格式因语言或区域而异的项目时,都需要使用感知locale的API。
7.1.2 指定Locale
Locale由五部分组成:
1.语言(language),由2个或3个小写字母表示。例如en(英语)、de(德语)和zh(中文)。完整列表见ISO 639-1语言代码。
2.可选的文字体系(script),由4个字母表示,首字母大写。例如Latn(拉丁字母)、Cyrl(西里尔字母)、Hans(简体中文)和Hant(繁体中文)。例如,塞尔维亚语可以用拉丁字母或西里尔字母书写,中文可以用简体字或繁体字书写。完整列表见ISO 15924文字体系代码。
3.可选的国家(country)或地区(region),由2个大写字母或3个数字表示。例如US(美国)和ZH(中国)。完整列表见ISO 3166-1国家代码。
4.可选的变体(variant),用于指定各种杂项特性,例如方言和拼写规则。变体现在已经很少使用了。
5.可选的扩展(extension),描述日历、数字等的本地偏好。Unicode标准规定了一些扩展,这些扩展以u-和两个字母的代码开头,这两个字母的代码指定该扩展处理的是日历(ca)还是数字(nu)等。例如,扩展u-nu-thai表示使用泰语数字。其他扩展是完全任意的,以x-开头,例如x-java。
Locale的规则在IETF的BCP 47 (https://datatracker.ietf.org/doc/bcp47/)中进行了详细阐述。可以在 https://www.w3.org/International/articles/language-tags/ 找到更容易理解的总结。
语言和国家的代码看起来有点随机,因为其中一些来自当地语言。德语在德语中是Deutsch,中文在中文里是zhōngwén:因此分别是de和zh。瑞士是CH,来自瑞士联邦的拉丁语Confoederatio Helvetica。
Locale是用标签描述的——通过连字符连接各locale元素的字符串。例如,在美国使用en-US,在德国则使用de-DE。瑞士有4种官方语言(德语、法语、意大利语和里托罗曼斯语)。讲德语的瑞士人希望使用de-CH,这个locale使用德语的规则,但货币值表示成瑞士法郎而不是欧元。
如果只指定了语言(例如de),那么该locale就不能用于与国家相关的场景,例如货币。
可以像这样用标签字符串来构造Locale对象:
1
Locale usEnglish = Locale.forLanguageTag("en-US");
toLanguageTag()方法生成给定Locale的语言标签。例如,usEnglish.toLanguageTag()返回字符串"en-US"。
为了方便,有许多为各国家预定义的Locale对象:Locale.CHINA("zh-CN"), Locale.US("en-US"), Locale.GERMANY("de-DE")等。
还有许多预定义的Locale仅指定了语言:Locale.CHINESE("zh"), Locale.ENGLISH("en"), Locale.GERMAN("de")等。
最后,静态方法getAvailableLocales()返回虚拟机能够识别的所有locale构成的数组。
注释:可以用静态方法getISOLanguages()获得所有语言代码,用getISOCountries()获得所有国家代码。
7.1.3 默认Locale
Locale类的静态方法getDefault()获取本地操作系统的默认locale。可以调用setDefault()方法来修改Java的默认locale。但是,这种修改只对Java程序有效,不会影响操作系统。
有些操作系统允许用户为显示消息和格式化指定不同的locale。例如,生活在美国的法国人可以有法语菜单,但货币值用美元。为了获取这些偏好,可以调用
1
2
Locale displayLocale = Locale.getDefault(Locale.Category.DISPLAY);
Locale formatLocale = Locale.getDefault(Locale.Category.FORMAT);
注释:在UNIX中,可以通过设置LC_NUMERIC、LC_MONETARY和LC_TIME环境变量来为数字、货币和日期指定单独的locale。但是Java并不会关注这些设置。
提示:为了测试,你可能希望改变程序的默认locale,可以在启动程序时提供语言和区域设置。例如,下面的命令将默认locale设置为de-CH:
1
java -Duser.language=de -Duser.region=CH MyProgram
7.1.4 显示名称
Locale对象本身能做的事情很有限。Locale类中唯一有用的是那些标识语言和国家代码的方法。其中最重要的是getDisplayName(),它以可呈现给用户的形式返回locale的名称,例如 “German (Switzerland)” 。但是,显示的名称是以默认locale表示的,这可能不太合适。如果用户已经选择了德语作为首选语言,就应该用德语显示名称。通过将德语locale作为参数即可。代码
1
2
var loc = new Locale("de", "CH");
System.out.println(loc.getDisplayName(Locale.GERMAN));
将打印 “Deutsch (Schweiz)” 。
这个例子说明了为什么需要Locale对象。将其传递给感知locale的方法,这些方法将对于不同地区的用户产生不同的文本。在后面各节中将会见到大量的例子。
警告:即使是把字符串转换为小写或大写这样简单的操作也可能是与locale相关的。例如,在土耳其语中,字母 “I” 的小写形式是不带点的 “ı” 。对于土耳其用户来说,试图通过转换为小写形式来规范化字符串的程序会神秘地失败,因为 “I” 和带点的 “i” 小写形式不同。好的做法是始终使用接受Locale参数的toUpperCase()和toLowerCase()。例如:
1
2
String cmd = "QUIT".toLowerCase(Locale.forLanguageTag("tr"));
// "quıt" with a dotless ı
注释:可以显式设置输入/输出操作的locale
- 当从
Scanner读取数字时,可以用useLocale()方法设置其locale。 String.format()和PrintWriter.printf()方法接受可选的Locale参数。
7.2 数字格式
前面已经提到数字和货币格式化高度依赖于locale。Java库在java.text包中提供了一组格式化器(formatter)对象,可以对数值进行格式化和解析。
7.2.1 格式化数值
按照以下步骤对特定locale进行数字格式化:
- 按上一节描述的方法获得
Locale对象。 - 使用工厂方法获取formatter对象。
- 使用formatter对象进行格式化和解析。
工厂方法是NumberFormat类的静态方法,接受一个Locale参数,返回其某个子类的对象。有三个工厂方法:getNumberInstance()、getCurrencyInstance()和getPercentInstance()。这些方法分别返回可以格式化和解析数字、货币值和百分比的对象。例如,可以像这样格式化德语中的货币值:
1
2
3
4
Locale loc = Locale.GERMANY;
NumberFormat formatter = NumberFormat.getCurrencyInstance(loc);
double amt = 123456.78;
String result = formatter.format(amt);
结果是 “123.456,78 €” 。注意货币符号是€(欧元),且位于字符串结尾。同时注意小数点和千位分隔符是相反的。
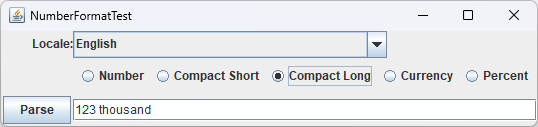
Java 12添加了两种风格的“紧凑”格式:短风格(如 “123K” )和长风格(如 “123 thousand” )。像这样获取短风格:
1
formatter = NumberFormat.getCompactNumberInstance(loc, NumberFormat.Style.SHORT);
反过来,要解析按照某个locale的习惯存储的数字字符串,需要使用parse()方法。例如,下面的代码解析用户输入到文本框中的值:
1
2
3
4
5
TextField inputField;
...
NumberFormat fmt = NumberFormat.getNumberInstance(); // get the number formatter for default locale
Number input = fmt.parse(inputField.getText().strip());
double x = input.doubleValue();
parse()的返回类型是抽象类型Number。返回的对象是一个Double或Long包装器对象,这取决于被解析的数字是否是浮点数。如果不关心这一差异,可以直接使用doubleValue()方法获取被包装的数字。
警告:Number类型的对象不能自动拆箱,因此不能直接将其赋给基本类型变量,而应该使用doubleValue()或intValue()等方法。
如果数字文本的格式不正确,该方法会抛出ParseException。例如,字符串开头的空白符是不允许的(先调用trim()或strip()去掉)。但是,任何跟在数字之后的字符都将被忽略,因此不会抛出异常(例如"123abc"解析为123)。
NumberFormat类的静态方法getAvailableLocales()返回可以获取数字formatter对象的locale的数组。
本书代码包含一个可以让你尝试数字格式化的GUI程序(如下图所示)。上方的组合框可以选择locale,中间可以选择数字、货币或百分比formatter。每次选择后,文本框中的数字就会被重新格式化。也可以输入不同的数字并点击Parse按钮来调用parse()方法尝试解析你输入的内容。如果解析成功,则将其传递给format()并显示结果。如果解析失败,则在文本框中显示错误消息。
numberFormat/NumberFormatTest.java
程序清单7-1给出了这个数字格式探索程序更容易理解的文本版本。
程序清单7-1 numberFormat/NumberFormatTest2.java
7.2.2 DecimalFormat类
在大多数locale中,上一节中看到的NumberFormat工厂方法都会返回一个DecimalFormat类的实例。这个类描述了世界各地的格式化变体。你可以修改单个设置,也可以创建全新的formatter。模式语法使其更简便了。
模式描述了必需和可选的数字位数,以及正数和负数的前缀与后缀。还有一些更深奥的设置,详见下表(注:表中的“属性”实际是一对getter/setter方法)。
| 属性 | 描述 | 模式 |
|---|---|---|
groupingSize | 一起分组的数字位数(通常是3或4) | 最后一个,和整数部分末尾之间的数字位数例如 #,###表示分组大小为3 |
minimum/maximumFractionDigits | 小数部分最小/最大位数 | 在小数部分使用必需(0)和可选(#)的数字例如 .00##表示显示2~4位小数,不足补0 |
minimumIntegerDigits | 整数部分最小位数 | 在整数部分使用0例如 000表示至少显示3位整数,不足补0 |
maximumIntegerDigits | 整数最大位数 | 使用指数表示法时,整数部分的#数量;否则不能在模式中设置例如 ###,##0.00E0表示显示为指数形式,整数部分至少1位,小数部分至少2位,整数和小数部分总共至多8位 |
| - | 指数部分最小位数 | 在E部分使用0例如 #.00E00表示指数部分至少2位 |
multiplier | 百分号和千分号 | %表示百分号,‰ (U+2030)表示千分号 |
positivePrefix/Suffix,negativePrefix/Suffix | 正数和负数的前缀与后缀 | 用字面值表示的前缀或后缀包围模式中的正数或负数部分(用;分隔)例如 +#0.00;(#)对于正数使用+前缀、没有后缀,将负数用括号括起来 |
decimalSeparatorAlwaysShown | 如果为true则小数部分为0时也显示分隔符 | 不能在模式中设置 |
考虑下面的例子:
1
var formatter = new DecimalFormat("0.00;(#)");
模式中的分号将正数和可选的负数部分分隔开。正数部分表示其整数部分至少有一位数字、小数部分至少有两位数字。负数使用会计模式——前缀(和后缀)。
前缀和后缀可能包含货币符号¤ (U+00A4),用来表示货币符号应该出现的位置。
如果需要在前缀或后缀中插入特殊字符,在其前面加一个单引号。例如,前缀'#是一个井号,o''clock包含一个单引号。
模式中的小数点.、分隔符,和百分号%等仅仅是占位符。这些部分的实际符号取自DecimalFormatSymbols对象,也可以自定义该对象。下表列出了它的属性。
| 属性 | 类型 | 描述 |
|---|---|---|
currencySymbol | String | 像"$"或"EUR"这样的字符串,用于前缀或后缀中的货币符号¤ |
decimalSeparator,monetaryDecimalSeparator | char | 用于数字或货币值的小数分隔符 |
exponentSeparator | String | 指数部分之前的字符串,通常是"E" |
groupingSeparator,monetaryGroupingSeparator(Java 15之后) | char | 用于数字或货币值的组分隔符 |
infinity, naN | String | 用于格式化Double.POSITIVE_INFINITY、Double.NEGATIVE_INFINITY和Double.NaN的字符串 |
internationalCurrencySymbol | String | ISO 4217货币符号,见7.2.3节 |
minusSign | char | 未指定负数模式时使用的负号 |
percent, perMill | char | 用于百分号和千分号的字符 |
zeroDigit | char | 用于数字0的字符,其他数字为后续的9个Unicode字符 |
可以用DecimalFormat类的setDecimalFormatSymbols()方法设置格式符号。例如,假设你希望无论使用什么locale,都用美国风格展示数字(组分隔符用,,小数点用.),可以像这样自定义格式符号和formatter:
1
2
3
4
5
DecimalFormatSymbols symbols = new DecimalFormatSymbols(loc);
symbols.setGroupingSeparator(',');
symbols.setDecimalSeparator('.');
DecimalFormat formatter = (DecimalFormat) NumberFormat.getNumberInstance(loc);
formatter.setDecimalFormatSymbols(symbols);
7.2.3 货币
为了格式化货币值,可以使用NumberFormat.getCurrencyInstance()方法。但是,这个方法不是很灵活——它返回只针对一种货币的formatter。假设你为一个美国客户准备了一张货物单,其中有些金额是美元,有些是欧元。你不能只是使用两种formatter:
1
2
NumberFormat dollarFormatter = NumberFormat.getCurrencyInstance(Locale.US);
NumberFormat euroFormatter = NumberFormat.getCurrencyInstance(Locale.GERMANY);
因为这样货物单看起来会非常奇怪:有些金额显示为$100,000.00,而另一些显示为100.000,00€(注意欧元值的小数点和分隔符是相反的)。
这种情况下,应该用Currency类来控制formatter使用的货币。可以通过将货币标识符传递给静态方法getInstance()来得到一个Currency对象,然后对每个formatter调用setCurrency()方法。可以像这样为美国客户设置欧元formatter:
1
2
NumberFormat euroFormatter = NumberFormat.getCurrencyInstance(Locale.US);
euroFormatter.setCurrency(Currency.getInstance("EUR"));
这样欧元金额将显示为€100,000.00(即按照美国locale的习惯显示欧元货币值)。
注:也可以按照7.2.2节所述的方法,先创建一个DecimalFormatSymbols对象,对其调用setCurrencySymbol("€"),然后将该对象设置为formatter的格式符号,将得到同样的结果。实际上,setCurrency()方法底层就是这样实现的。
货币标识符由ISO 4217定义(参见 https://www.iso.org/iso-4217-currency-codes.html )。下表提供了其中的一部分。
| 货币名称 | 标识符 | 数字代码 |
|---|---|---|
| 美元 | USD | 840 |
| 欧元 | EUR | 978 |
| 英镑 | GBP | 826 |
| 日元 | JPY | 392 |
| 人民币 | CNY | 156 |
| 印度卢比 | INR | 356 |
| 俄罗斯卢布 | RUB | 643 |
7.3 日期和时间
在格式化日期和时间时,需要考虑4个与locale相关的问题:
- 月份和星期的名字应该用本地语言表示。
- 年、月、日的顺序应该符合本地习惯。
- 公历可能不是本地表示日期的首选。
- 必需考虑本地的时区。
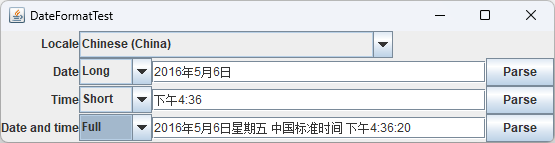
java.time包中的DateTimeFormatter类可以处理这些问题。首先选择下表所示的一种格式化风格(java.time.format.FormatStyle枚举):
| 风格 | 日期 | 时间 |
|---|---|---|
SHORT | 7/16/69 | 9:32 AM |
MEDIUM | Jul 16, 1969 | 9:32:00 AM |
LONG | July 16, 1969 | 9:32:00 AM EDT (en-US) 9:32:00 MSZ (de-DE) (只用于 ZonedDateTime) |
FULL | Wednesday, July 16, 1969 | 9:32:00 AM EDT (en-US) 9:32 Uhr MSZ (de-DE) (只用于 ZonedDateTime) |
然后获得一个formatter:
1
2
3
4
5
FormatStyle style = ...; // One of SHORT, MEDIUM, LONG, FULL
DateTimeFormatter dateFormatter = DateTimeFormatter.ofLocalizedDate(style);
DateTimeFormatter timeFormatter = DateTimeFormatter.ofLocalizedTime(style);
DateTimeFormatter dateTimeFormatter = DateTimeFormatter.ofLocalizedDateTime(style);
// or DateTimeFormatter.ofLocalizedDateTime(style1, style2)
这些formatter都使用当前的locale。要使用不同的locale,需要使用withLocale()方法:
1
DateTimeFormatter dateFormatter = DateTimeFormatter.ofLocalizedDate(style).withLocale(locale);
现在可以格式化LocalDate、LocalTime、LocalDateTime或ZonedDateTime了:
1
2
ZonedDateTime appointment = ...;
String formatted = formatter.format(appointment);
注释:还有一个来自Java 1.1的遗留类java.text.DateFormatter,它操作的是Date和Calendar对象。
可以使用LocalDate、LocalTime、LocalDateTime或ZonedDateTime之一的静态方法parse()来解析字符串中的日期或时间:
1
LocalTime time = LocalTime.parse("9:32 AM", formatter);
这些方法不适合解析(未做预处理的)人类输入。例如,用于美国的SHORT风格时间formatter可以解析 “9:32 AM” ,但不能解析 “9:32AM” 或 “9:32 am” 。
警告:日期formatter可以解析不存在的日期,例如11月31日,它会将其调整为给定月份的最后一天。
有时只需要显示星期和月份的名字,例如在日历应用中。可以调用DayOfWeek和Month枚举的getDisplayName()方法:
1
2
for (Month m : Month.values())
System.out.println(m.getDisplayName(textStyle, locale) + " ");
参数textStyle是文本风格(java.time.format.TextStyle枚举),如下表所示,其中STANDALONE版本用于格式化日期之外的显示。例如,在芬兰语中,一月在日期中是 “tammikuuta” ,但单独显示是 “tammikuu” 。
| 文本风格 | 示例 |
|---|---|
FULL/FULL_STANDALONE | January |
SHORT/SHORT_STANDALONE | Jan |
NARROW/NARROW_STANDALONE | J |
注释:星期的第一天可能是星期六、星期日或星期一,这取决于locale。可以像这样获取它:
1
DayOfWeek first = WeekFields.of(locale).getFirstDayOfWeek();
程序清单7-2展示DateTimeFormatter类的实际应用,可以选择一个locale并查看日期和时间在世界上的不同地方是如何格式化的。
程序清单7-2 dateFormat/DateTimeFormatTest2.java
下图显示了该程序的GUI版本。
dateFormat/DateTimeFormatTest.java
7.4 排序规则和规范化
String类的compareTo()方法使用字符串的UTF-16编码值比较字符串,这可能会导致荒唐的结果,即使在英语中也是如此。例如,下面的5个字符串是根据compareTo()方法排序的:
1
2
3
4
5
America
Zulu
able
zebra
Ångström
对于字典序,你希望将大写和小写看作是等价的。对于说英语的人,这些单词的顺序应该是
1
2
3
4
5
able
America
Ångström
zebra
Zulu
但是在瑞典语中,字母Å和A是不同的,并且排在字母Z之后(这种字母顺序称为排序规则(collation))。也就是说,瑞典用户期望的单词顺序是
1
2
3
4
5
able
America
zebra
Zulu
Ångström
为了获得对locale敏感的比较器,需要调用静态方法Collator.getInstance():
1
2
Collator coll = Collator.getInstance(locale);
words.sort(coll); // Collator implements Comparator<Object>
Collator类实现了Comparator<Object>接口,因此可以将Collator对象传递给List.sort(Comparator)方法来对字符串列表进行排序。
可以设置排序器(collator)的强度(strength)来调整它对字符的区分程度。字符间的差别分为首要的(primary)、其次的(secondary)和再次的(tertiary)。例如,在英语中, “A” 和 “Z” 之间的差别是首要的, “A” 和 “Å” 之间的差别是其次的,而 “A” 和 “a” 之间的差别的再次的。
如果将collator的强度设置成Collator.PRIMARY,那么它将只关注首要的差别,而将其次和再次差别的字符认为是等价的,如下表所示。
| 首要 | 其次 | 再次 |
|---|---|---|
| Angstrom = Ångström | Angstrom ≠ Ångström | Angstrom ≠ Ångström |
| Able = able | Able = able | Able ≠ able |
如果将强度设置为Collator.IDENTICAL,则不允许有任何差别。这种设置在与另一种设置——分解模式(decomposition mode)联合使用时显得非常有用。
偶尔,一个字符或字符序列在Unicode中可以用多种方式描述。例如, “Å” 可以是Unicode字符U+00C5,或者可以表示成普通的 “A” (U+0041)后面跟着 “̊” (U+030A)。字母序列 “ffi” 可以描述成单个字符:拉丁小连字 “ffi” (U+FB03)。
Unicode标准对字符串定义了四种规范化形式(normalization form):D、KD、C和KC。详见 https://www.unicode.org/reports/tr15/ 。在规范化形式C中,重音符号总是组合的(例如 A + ̊ → Å );在规范化形式D中,带重音的字符总是分解为基字母和重音符(例如 Å → A + ̊ )。规范化形式KC和KD也会分解诸如连字(ffi)和商标符号(™)之类的字符。
你可以选择collator所使用的规范化程度:
Collator.NO_DECOMPOSITION不做任何分解。这个选项处理速度较快,但不适用于以多种形式表示字符的文本。Collator.CANONICAL_DECOMPOSITION(默认值)使用规范化形式D,适用于包含重音符但不包含连字的文本。Collator.FULL_DECOMPOSITION使用规范化形式KD。
不同分解模式的示例见下表。
| 不分解 | 规范分解 | 完全分解 |
|---|---|---|
| Å ≠ A ̊ | Å = A ̊ | Å = A ̊ |
| ™ ≠ TM | ™ ≠ TM | ™ = TM |
让collator多次分解一个字符串是很浪费的。如果一个字符串要和其他字符串进行多次比较(例如排序),可以将分解结果保存在一个排序键对象中。Collator类的getCollationKey()方法返回一个CollationKey对象,可用于更快速的比较。例如:
1
2
3
4
String a = ...;
CollationKey aKey = coll.getCollationKey(a);
if (aKey.compareTo(coll.getCollationKey(b)) == 0) // fast comparison
...
最后,即使不进行排序,你也可能希望将字符串转换成其规范化形式。例如,将字符串存储在数据库中或与其他程序通信。java.text.Normalizer类实现了规范化处理。例如:
1
2
String name = "Ångström";
String normalized = Normalizer.normalize(name, Normalizer.Form.NFD); // uses normalization form D
字符串normalized包含10个字符:"A ̊ ngstro ̈ m"。但是,这通常并非用于存储或传输的最佳形式。规范化形式C首先进行分解,然后将重音按照标准化的顺序再组合起来。根据W3C的标准,这是通过互联网传输数据的推荐模式。
程序清单7-3中的程序可以让你尝试排序顺序。
程序清单7-3 collation/CollationTest2.java
本书代码还包括一个GUI版本。在文本框中输入一个单词,然后点击Add按钮将它添加到单词列表中。每次添加一个单词,或改变locale、强度或分解模式时,单词列表就会重新排序。等号表示两个单词被认为是等同的(见下图)。
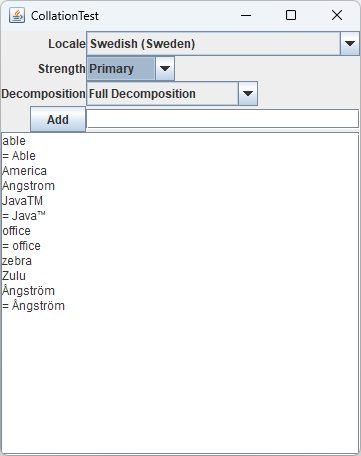
7.5 消息格式化
Java库有一个MessageFormat类,用于格式化具有可变部分的文本。它类似于使用printf()方法进行格式化,但支持数字和日期的locale。后面几节将讨论这一机制。
7.5.1 格式化数字和日期
下面是一个典型的消息格式字符串(模式):
1
"On {2}, a {0} destroyed {1} houses and caused {3} of damage."
花括号中的数字是占位符。静态方法MessageFormat.format()可以用实际值来替换占位符。它是变参方法,所以可以直接像这样提供参数:
1
2
String msg = MessageFormat.format("On {2}, a {0} destroyed {1} houses and caused {3} of damage.",
"hurricane", 99, new GregorianCalendar(1999, 0, 1).getTime(), 10.0E8);
在这个例子中,占位符{0}被替换为"hurricane",{1}被替换为99,以此类推。结果是以下字符串:
1
On 1/1/99 12:00 AM, a hurricane destroyed 99 houses and caused 100,000,000 of damage.
但是,我们不希望显示时间 “12:00 AM” ,而且希望将损失金额打印为货币值。通过为占位符提供可选的格式可以做到这一点:
1
"On {2,date,long}, a {0} destroyed {1} houses and caused {3,number,currency} of damage."
这样结果为
1
On January 1, 1999, a hurricane destroyed 99 houses and caused $100,000,000 of damage.
一般地,占位符索引后面可以跟一个类型(type)和一个风格(style),它们之间用逗号隔开。类型可以是number、time、date或choice。
如果类型是number,那么风格可以是integer、currency、percent或者是DecimalFormat模式(如$,##0,见7.2.2节)。
如果类型是time或date,那么风格可以是short、medium、long、full或者是日期格式模式(如yyyy-MM-dd,支持的格式见SimpleDateFormat类的文档)。
警告:静态方法MessageFormat.format()使用当前locale进行格式化。为了使用自定义的locale,需要构造一个MessageFormat对象并将locale传递给构造器参数。由于实例方法format()没有可变参数,需要把要格式化的值放在Object[]数组中:
1
2
var mf = new MessageFormat(pattern, loc);
String msg = mf.format(new Object[] {values});
7.5.2 choice格式
在上一节的模式中,如果用"earthquake"来替换{0},这句话在英语中的语法就不正确了:
1
On January 1, 1999, a earthquake destroyed ...
应该将冠词集成到占位符中:
1
"On {2}, {0} destroyed {1} houses and caused {3} of damage."
并且应该用"a hurricane"或"an earthquake"来替换{0}。(注:简单来说就是需要人工保证冠词正确,无法自动识别)
下面来看占位符{1}。如果它替换为数字1,消息就变成:
1
On January 1, 1999, a mudslide destroyed 1 houses and ...
这里的 “houses” 是复数形式。我们希望 “house” 能够根据占位符的值变化,例如 “no houses” 、 “one house” 、 “2 houses” 等。格式化选项choice就是为这个目的而设计的。
choice格式是一个(下限, 格式字符串)对的序列。下限和格式字符串由#分隔,对与对之间由|分隔。例如,{1,choice,0#no houses|1#one house|2#{1} houses}。下表显示了这个格式字符串对于{1}的不同值的效果。
{1} | 结果 |
|---|---|
| 0 | “no houses” |
| 1 | “one house” |
| 2 | “2 houses” |
| -1 | “no houses” |
在格式字符串中两次用到了{1},这是因为当替换值为2时,choice格式会返回"{1} houses",这个字符串会再次格式化,得到"2 houses"。
注:choice格式本质上是一个“分段函数”,需要人工列出值在不同区间内对应的结果,并不能自动实现单/复数转换。
注释:choice格式的设计者有些糊涂了。你需要的下限数目比格式字符串少一个。MessageFormat类将忽略第一个下限。如果设计者意识到下限属于两个选择之间,那么语法就会清楚得多,比如no houses|1|one house|2|{1} houses。
可以使用<来表示如果下限严格小于替换值则选择这个选项。也可以使用≤作为#的同义词。如果愿意,甚至可以将第一个下限指定为–∞。例如:
1
-∞<no houses|0<one house|2≤{1} houses
或者使用Unicode转义字符:
1
-\u221E<no houses|0<one house|2\u2264{1} houses
将choice格式放到原始消息字符串中:
1
2
String pattern = "On {2,date,long}, {0} destroyed {1,choice,0#no houses|1#one house|2#{1} houses}"
+ " and caused {3,number,currency} of damage.";
在德语中是
1
2
String pattern = "{0} zerstörte am {2,date,long} {1,choice,0#kein Haus|1#ein Haus|2#{1} Häuser}"
+ " und richtete einen Schaden von {3,number,currency} an.";
messageFormat/MessageFormatTest.java
7.6 文本输入和输出
Java语言自身是完全基于Unicode的。但是,Windows和Mac OS X仍然支持遗留的字符编码,例如西欧国家的Windows-1252和Mac Roman,以及台湾的Big5。因此,通过文本与用户沟通并非看上去那么简单。下面几节将讨论你可能碰到的各种复杂情况。
7.6.1 文本文件
如今,最好使用UTF-8保存和加载文本文件,但是你可能需要处理遗留文件。可以在读写文本文件时指定字符编码:
1
var out = new PrintWriter(filename, "Windows-1252");
可以通过下面的调用获得平台默认编码:
1
Charset platformEncoding = Charset.defaultCharset();
注:另见卷II第2章“文本输入和输出”一节。
7.6.2 行结束符
这不是locale的问题,而是平台的问题。在Windows中,文本文件使用\r\n作为行结束符,而基于UNIX的系统只需要一个\n。
任何用println()方法写出的行都将包含正确的结束符。唯一的问题是如果你打印了包含\n的字符串,它不会被自动修改为平台的行结束符。应该使用printf()方法和%n格式说明符来产生平台相关的行结束符。例如,
1
out.printf("Hello%nWorld%n");
在Windows上会打印Hello\r\nWorld\r\n,在其他平台上会打印Hello\nWorld\n。
7.6.3 控制台
如果你编写的程序是通过System.in/System.out或System.console()与用户交互的,那么就不得不面对控制台可能使用与平台默认不同的字符编码的问题。当使用Windows的CMD命令行时,这个问题尤其需要注意。在美国版的Windows 10中,CMD仍然使用古老的IBM437编码(没有任何官方API透露这一信息),而Charset.defaultCharset()方法返回Windows-1252字符集,二者完全不同(注:在中国版Windows中,这两者都是GBK)。例如,在Windows-1252中有欧元符号€,但是在IBM437中没有。如果调用System.out.println("100 €"),控制台会显示100 ?。
你可以建议用户切换控制台的字符编码。在CMD中,这可以通过chcp命令实现。例如:
1
chcp 1252
会将控制台变为Windows-1252编码页。(注:详见微软官方文档chcp命令)
理想情况下,用户应该将控制台切换到UTF-8。在Windows中,命令是chcp 65001。但是该命令还不足以让Java在控制台中使用UTF-8,还必须使用非官方的file.encoding系统属性来设置平台编码:
1
java -Dfile.encoding=UTF-8 MyProg
7.6.4 日志文件
当来自java.util.logging库的日志消息被发送到控制台时,会用控制台的编码写出。但是,文件中的日志消息会使用FileHandler来处理,它默认使用平台编码。要将编码改为UTF-8,需要在日志配置文件中设置
1
java.util.logging.FileHandler.encoding=UTF-8
注:参见卷I第7章 7.5.3节。
7.6.5 UTF-8字节顺序标记
如前所述,尽可能对文本文件使用UTF-8是个好主意。但是,如果你的应用需要读取其他程序创建的UTF-8文本文件,可能会碰到另一个问题。在文件开头添加字节顺序标记(byte order mark, BOM)字符U+FEFF是完全合法的。在UTF-16编码中,每个码元都是两字节,字节顺序标记可以告诉读取器该文件使用的是大端序还是小端序。UTF-8是单字节编码,因此无需指定字节顺序。但如果一个文件以字节0xEF 0xBB 0xBF(U+FEFF的UTF-8编码)开头,这就是一种强烈暗示表明该文件使用了UTF-8。因此,Unicode标准鼓励这种做法:任何读取器都应该丢弃最前面的字节顺序标记。(注:另见卷II第2章 2.1.8节)
还有一个瑕疵——Oracle的Java实现顽固地拒绝遵循Unicode标准,理由是潜在的兼容性问题。这意味着你必须去做Java平台不会做的操作:在读取文本文件时,如果在开头遇到U+FEFF,就将其忽略。
警告:遗憾的是,JDK实现者没有遵循这项建议。如果向javac编译器传递以字节顺序标记开头的合法UTF-8源文件,编译会失败并报错 “illegal character: ‘\ufeff’” 。
7.6.6 源文件的字符编码
在程序编译和运行过程中,涉及三种字符编码:
- 源文件:本地平台编码
- 类文件:修改版UTF-8
- 虚拟机:UTF-16
可以用-encoding选项指定源文件的字符编码,例如:
1
javac -encoding UTF-8 Myfile.java
7.7 资源包
在本地化应用程序时,可能需要翻译大量的消息字符串、按钮标签等。为了使这项任务可行,应该在外部定义消息字符串(而不是硬编码在源文件中),通常称为资源(resource)。翻译人员可以直接编辑资源文件,无需接触程序源代码。
在Java中,可以使用属性文件来指定字符串资源,对于其他类型的资源实现相应的类。
注释:卷I第5章 5.9.3节描述了JAR文件资源的概念。Class类的getResource()方法可以返回资源文件的URL(由类加载器定位资源文件)。但是,这种机制不支持locale。
7.7.1 定位资源包
在本地化应用程序时,会产生一组资源包(resource bundle)。每个包都是一个属性文件或类,用于描述与locale相关的项(如消息、标签等)。对于每个包,都要为所有希望支持的locale提供相应的版本。
对这些包需要使用一种特定的命名规则。例如,德国特有的资源放在名为baseName_de_DE的包中,而所有说德语的国家共享的资源放在名为baseName_de的包中。
一般地,对于特定国家的资源使用baseName_language_country,对于特定语言的资源使用baseName_language。最后,作为后备(fallback),可以把默认值放在没有任何后缀的包中。
可以使用以下命令加载一个包:
1
ResourceBundle currentResources = ResourceBundle.getBundle(baseName, currentLocale);
getBundle()方法会尝试加载与当前locale的语言和国家匹配的包。如果失败,则查找仅匹配语言的包。然后使用默认locale进行同样的查找,最后查找默认包。如果这也失败了,则抛出MissingResourceException。也就是说,getBundle()方法按以下顺序查找包:
1
2
3
4
5
baseName_currentLocaleLanguage_currentLocaleCountry
baseName_currentLocaleLanguage
baseName_defaultLocaleLanguage_defaultLocaleCountry
baseName_defaultLocaleLanguage
baseName
一旦getBundle()方法定位到一个包,比如MyResource_de_DE,它还会继续查找MyResource_de和MyResource,形成资源层次结构。之后在查找一个资源时,如果在当前包中没有找到,就去父包中查找。例如,如果某个特定资源在MyResource_de_DE中没有找到,则依次查找MyResource_de和MyResource。(注:从而可以将共享的资源放在父包中,不必在每个子包中重复一次)
Java语言的资源包机制是一项非常有用的服务,可以自动定位与给定locale最佳匹配的资源。在现有程序中添加更多本地化很容易,只需创建额外的资源包即可。
注:这里简化了资源包查找过程。如果locale包含文字体系和变体,那么查找会复杂得多。详见Resource Bundle Search and Loading Strategy和ResourceBundle.Control.getCandidateLocales()方法的文档。
提示:不需要把应用程序的所有资源都放到同一个包中。可以用一个包存放按钮标签,另一个包存放错误消息等。
7.7.2 属性文件
对字符串进行国际化很简单。把所有字符串放到一个属性文件中,例如MyProgramStrings.properties。这是一个文本文件,每行一个键值对。例如:
1
2
3
computeButton=Rechnen
colorName=black
defaultPaperSize=210×297
然后按上一节描述的方式命名属性文件,例如
1
2
3
MyProgramStrings.properties
MyProgramStrings_en.properties
MyProgramStrings_de_DE.properties
可以像这样加载资源包:
1
ResourceBundle bundle = ResourceBundle.getBundle("MyProgramStrings", locale);
然后查找特定的字符串:
1
String computeButtonLabel = bundle.getString("computeButton");
警告:在Java 9之前,存储属性的文件必须是ASCII文件。如果使用旧版本的Java,并且需要在属性文件中包含Unicode字符,就使用\uxxxx对其编码。例如,要指定colorName=Grün,使用colorName=Gr\u00FCn。可以使用native2ascii工具自动转换。
7.7.3 Bundle类
为了提供非字符串资源,需要定义扩展ResourceBundle的类。使用前面描述的命名规则来命名这些类,例如
1
2
3
MyProgramResources.java
MyProgramResources_en.java
MyProgramResources_de_DE.java
与加载属性文件一样,使用getBundle()方法来加载bundle类:
1
ResourceBundle bundle = ResourceBundle.getBundle("MyProgramResources", locale);
警告:在查找包时,如果一个bundle类和一个属性文件具有相同的名字,则优先选择bundle类。
每个资源包类实现了一个查询表,使用键字符串来查询相应的资源。例如:
1
2
var backgroundColor = (Color) bundle.getObject("backgroundColor");
double[] paperSize = (double[]) bundle.getObject("defaultPaperSize");
实现bundle类最简单的方法是扩展ListResourceBundle类。把所有资源放到一个Object[][]数组中(每个资源用Object[2]表示,键为字符串,值为任意对象)并作为getContents()方法的返回值,该类会实现查找方法。遵循以下代码框架:
1
2
3
4
5
6
7
8
public class baseName_language_country extends ListResourceBundle {
private static final Object[][] contents = {
{key1, value2},
{key2, value2},
...
}
@Override protected Object[][] getContents() { return contents; }
}
例如:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
public class ProgramResources_de extends ListResourceBundle {
private static final Object[][] contents = {
{"backgroundColor", Color.black},
{"defaultPaperSize", new double[] {210, 297}}
}
@Override protected Object[][] getContents() { return contents; }
}
public class ProgramResources_en_US extends ListResourceBundle {
private static final Object[][] contents = {
{"backgroundColor", Color.blue},
{"defaultPaperSize", new double[] {216, 279}}
}
@Override protected Object[][] getContents() { return contents; }
}
注释:纸张尺寸的单位是毫米。在世界上,除了美国和加拿大,其他国家都使用ISO 216纸张尺寸。详见 https://www.cl.cam.ac.uk/%7Emgk25/iso-paper.html 。
或者,你的bundle类可以直接扩展ResourceBundle,然后实现两个方法:枚举所有键和查找给定键的值。
1
2
Enumeration<String> getKeys()
Object handleGetObject(String key)
ResourceBundle类的getObject()方法会调用handleGetObject()方法。
7.8 一个完整的例子
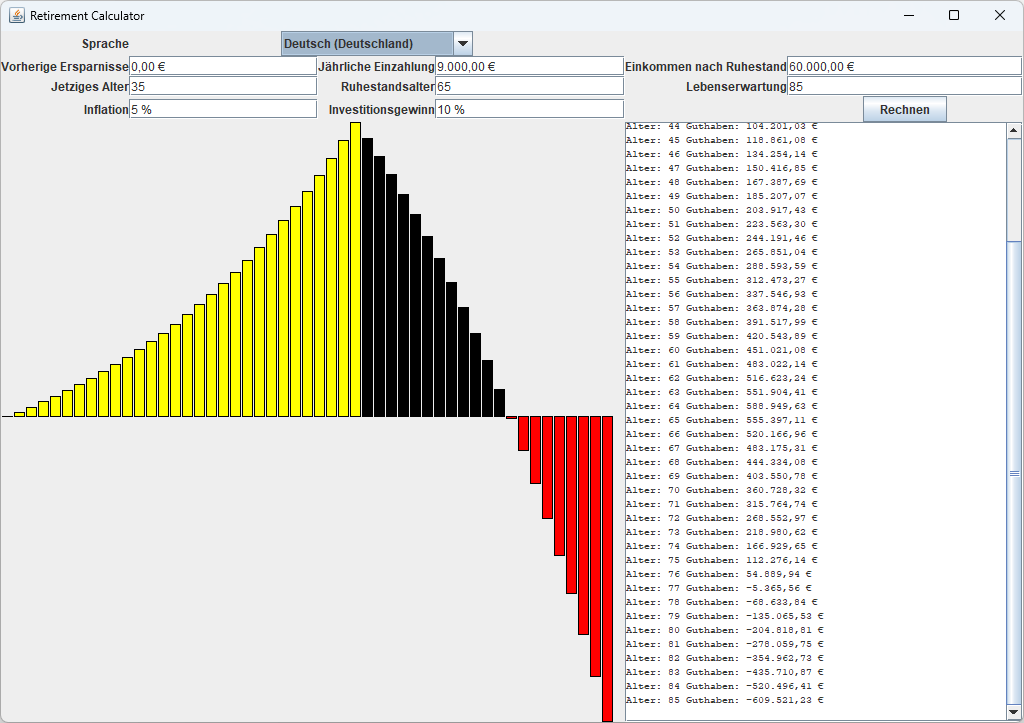
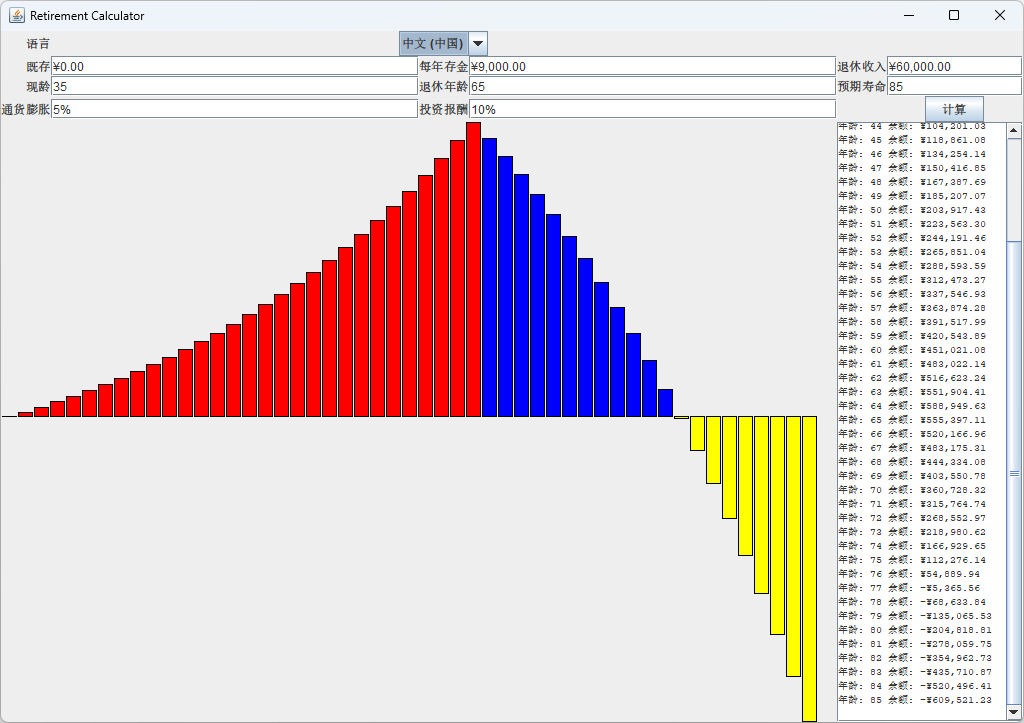
在这一节中,我们应用本章的知识来对退休计算器程序进行本地化。这个程序可以计算你是否为退休存够了钱,你需要输入年龄、每个月存多少钱等信息。文本区和图表显示每年退休金账户中的余额(如下图所示)。
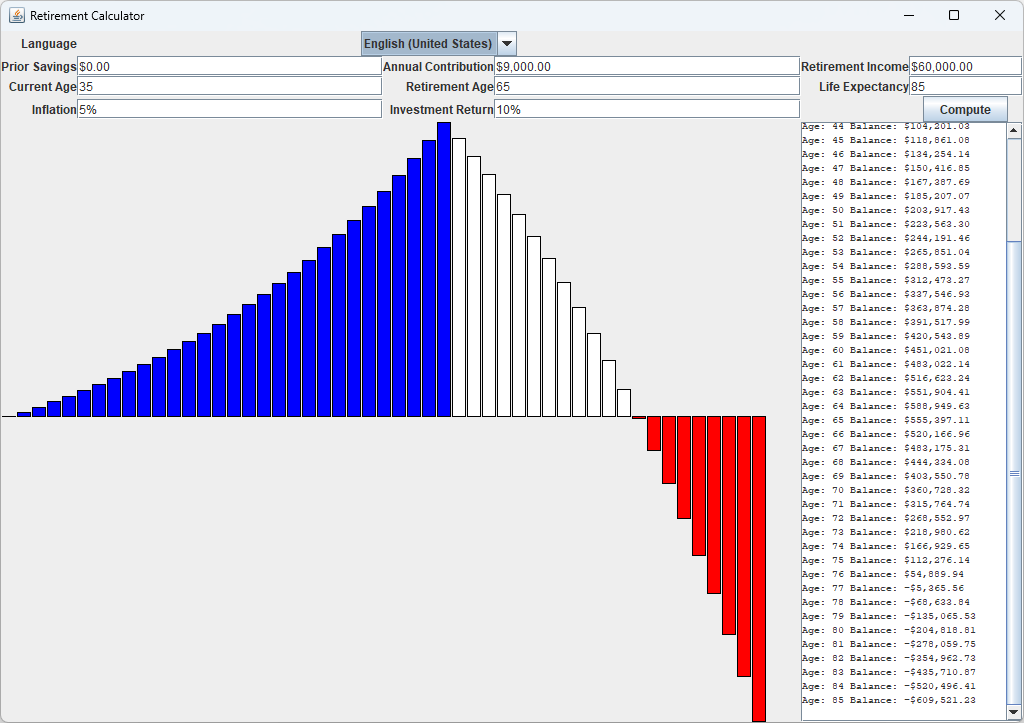
退休计算器支持三种locale:英语、德语和中文。下面是进行国际化时的一些要点:
- 标签、按钮和消息被翻译成德语和中文,可以在RetireStrings_de.properties和RetireStrings_zh.properties文件中找到。英语作为后备,见RetireStrings.properties文件。
- 当改变locale时,重置标签并重新格式化文本框中的内容。
- 文本框以本地格式处理数字、货币值和百分比。
- 文本区使用了
MessageFormat,格式字符串存储在每种语言的资源包中。 - 根据用户选择的语言为柱状图使用不同的颜色,颜色值存储在bundle类
RetireResources、RetireResources_de和RetireResources_zh中。
程序清单7-4到7-7给出了代码,程序清单7-8到7-10是本地化字符串的属性文件。
程序清单7-5 retire/RetireResources.java
程序清单7-6 retire/RetireResources_de.java
程序清单7-7 retire/RetireResources_zh.java
程序清单7-8 retire/RetireStrings.properties
程序清单7-9 retire/RetireStrings_de.properties
程序清单7-10 retire/RetireStrings_zh.properties
下图分别显示了德语和中文界面。为了显示中文字符,确保在Java运行环境中安装并配置了中文字体。