《C++程序设计原理与实践》笔记 第3章 对象、类型和值
本章介绍程序中的数据存储和使用的基本知识。
3.1 输入
“Hello, World!” 程序只是打印到屏幕,它不从用户那里得到输入。实际的程序通常基于我们给它的输入产生结果,而不是每次执行都做相同的事。
为了读取数据,需要在计算机内存中的某个地方放置读取的内容,这样的“地方”称为对象。对象(object)是一个某种类型(type)的内存区域,类型指定了可以放置什么样的信息。有名字的对象称为变量(variable)。可以将对象看成一个“盒子”,在其中放置该对象类型的值。例如,下图表示一个名为age的int类型的变量,其中保存的是整数值42:
使用字符串(string,定义在头文件<string>中)变量可以从输入中读取一个字符串,然后将它打印出来:
main()的第一行输出一个信息,鼓励用户输入一个名字,这个信息通常称为提示符(prompt)。
下一行string first_name;定义了一个名为first_name的string变量,这将划分一个可以保存一个字符串的内存区域,并将它命名为first_name,如下图所示:
下一行cin >> first_name;将键盘输入的字符串读取到变量first_name。
名字cin是由标准库定义的标准输入流(读作 “see-in” ,是 “character input” 的缩写)。操作符>>右边的名字指定输入到哪里。因此,如果输入 “Nicholas” 并按回车,则first_name的值将会变成字符串"Nicholas",如下图所示:
注:输出操作符>>和输入操作符<<可以看作是数据流动方向的箭头,cout << x表示将变量x的内容输出到cout(屏幕),cin >> x表示从cin(键盘)读取内容到x。
使用>>运算符读取字符串时,计算机简单地收集输入的字符,直到遇到一个换行符(按下回车键),在按回车键之前可以删除或修改某些字符。这个换行符不会成为字符串的一部分。
最后一行cout << "Hello, " << first_name << "!\n";使用first_name变量输出欢迎词 “Hello, Nicholas!” 。该语句等价于以下三个语句:
1
2
3
cout << "Hello, ";
cout << first_name;
cout << "!\n";
注意,"Hello, "使用了引号,是一个字符串常量,将原样输出;first_name没有引号,是一个变量,输出的是变量中的值。
3.2 变量
用来存储数据的内存区域称为对象(object),命名后的对象称为变量(variable),它有特定的类型(type)(例如int或string)。类型决定可以将什么赋给变量,以及可以使用的操作。赋给变量的数据项称为值(value)。用来定义变量的语句称为定义(definition),定义可以(通常应该)提供一个初始值。例如:
1
2
string name = "Annemarie";
int number_of_steps = 39;
可以像这样可视化这些变量:
不能将错误类型的值赋给变量:
1
2
string name = 39; // error: 39 is not a string
int number_of_steps = "Annemarie"; // error: "Annemarie" is not an int
否则会产生编译错误。编译器会记录每个变量的类型,并确认你对它的使用是否与它的类型一致。
C++提供了相当多的类型。但是只使用其中五种就完全可以写出好的程序:
1
2
3
4
5
int number_of_steps = 39; // int表示整数
double flying_time = 3.5; // double表示浮点数
char decimal_point = '.'; // char表示单个字符
string name = "Annemarie"; // string表示字符串
bool tap_on = true; // bool表示布尔值
每种类型的文字常量/字面值(literal)都有自己特殊的格式:一串数字表示一个整数(例如1234、2或976);带小数点的一串数字表示一个浮点数(例如1.234、0.12或.98);在单引号中的一个字符表示一个字符(例如'1'、'@'或'x');在双引号中的一串字符表示一个字符串(例如"1234"、"Howdy!"或"Annemarie");布尔值只有两个:true或false。
3.3 输入和类型
输入操作>> (“get from”)是对类型敏感的,它读取的值与变量类型需要一致。例如:
如果输入 “Carlos 22” ,>>操作符将 “Carlos” 读入first_name,将22读入age,并输出 “Hello, Carlos (age 22)” 。
为什么它不将 “Carlos 22” 全部读入first_name?这是有由于按照规定,字符串的读取会被空白符(whitespace)终止,包括空格、换行符和制表符(tab);对于数值类型的读取,空白符在默认情况下会被>>忽略。例如,可以在读取的数字之前添加任意多的空格,>>将会跳过它们并读取这个数字。
如果输入 “22 Carlos” , “22” 将被读入first_name,而 “Carlos” 并不是一个整数,因此age的读取失败。这时的输出将是22和某个随机数(例如-96739或0)。这是因为没有给age赋一个初始值,并且没能成功地读取一个值存入它,因此得到的是程序开始执行时碰巧在这块内存中的“垃圾值”。只要初始化age,这样在输入错误时会得到一个可预测的值(初始值):
现在,输入 “22 Carlos” 将会输出 “Hello, 22 (age 0)” 。
注:书中说输出是 “Hello, 22 (age -1)” ,而实际得到的结果是 “Hello, 22 (age 0)” 。这是由于不同版本的C++标准的区别:当>>读取失败时,C++11之前不改变变量的值,而C++11之后将变量置为0。对此cppreference有说明:
If extraction fails (e.g. if a letter was entered where a digit is expected), zero is written to value and failbit is set.
注意,可以在一个输入语句中读取多个值,就像可以在一个输出语句中写入多个值一样,因此cin >> first_name;和cin >> age;这两行等价于一行cin >> first_name >> age;
使用>>读取字符串会被空白符终止,也就是说它只能读取一个单词。但是有时候需要读入多个单词,有多种方法来实现。例如,可以像这样读取由两个单词组成的名字:
输入时会忽略空白符,但输出时必须手动插入空格。
3.4 运算和运算符
变量类型除了指定可以在变量中存储什么值,还决定了可以对它进行什么操作以及这些操作的含义。例如:
1
2
3
4
5
6
7
8
9
10
int count;
cin >> count; // >> reads an integer into count
string name;
cin >> name; // >> reads a string into name
int c2 = count + 2; // + adds integers
string s2 = name + "Jr."; // + appends characters
int c3 = count - 2; // - subtracts integers
string s3 = name - "Jr."; // error: - isn't defined for strings
运算符+对于int类型表示加法,而对于string类型表示字符串拼接;int支持-运算,而string不支持-运算。编译器确切地知道哪种操作可以应用于哪种变量,对变量执行不支持的操作将导致编译错误。
但是,编译器不知道每种操作对于什么样的值是有意义的。例如:
1
int age = -100;
显然年龄不能是一个负数,但对于编译器来说是合法的(编译器并不知道名为 “age” 的变量表示年龄)。
下表给出了一些常见的类型可以使用的运算符:
| 操作 | bool | char | int | double | string |
|---|---|---|---|---|---|
| 赋值 | = | = | = | = | = |
| 加(连接) | + | + | + | ||
| 减 | - | - | |||
| 乘 | * | * | |||
| 除 | / | / | |||
| 取模 | % | ||||
| 加1 | ++ | ++ | |||
| 减1 | -- | -- | |||
| 加(连接)并赋值 | += | += | += | ||
| 减并赋值 | -= | -= | -= | ||
| 乘并赋值 | *= | *= | |||
| 除并赋值 | /= | /= | |||
| 取模并赋值 | %= | ||||
| 从s读取x | s >> x | s >> x | s >> x | s >> x | s >> x |
| 将x写到s | s << x | s << x | s << x | s << x | s << x |
| 等于 | == | == | == | == | == |
| 不等于 | != | != | != | != | != |
| 大于 | > | > | > | > | > |
| 大于等于 | >= | >= | >= | >= | >= |
| 小于 | < | < | < | < | < |
| 小于等于 | <= | <= | <= | <= | <= |
注意:赋值运算符=是一个等号,相等运算符==是两个等号
下面是一个浮点数的例子:
常见的数学运算(加、减、乘、除)有常见的表示法和含义。平方根没有相应的运算符,而是使用标准库中的sqrt()函数。
注意:对于int类型,/是整除,%是取模(余数),因此5/2等于2(而不是2.5或3),5%2等于1。对于整数*、/和%的定义,保证对于两个正整数a和b,有a / b * b + a % b == a。
字符串支持的运算符较少,但都可以按常规方式使用。例如:
对于字符串,+意味着连接(concatenation)。例如,如果s1的值为 “Hello” ,s2的值为 “World” ,那么s1+s2的值为 “HelloWorld” 。(从上面代码中可以看出,字符串也可以和字符进行连接)
字符串比较操作特别有用:
3.5 赋值和初始化
初始化(initialization)在定义变量时指定初值,赋值(assignment)给变量一个新的值,二者使用相同的运算符=。例如:
1
2
3
4
5
int x = 8; // initialize x with 8
x = 9; // assign 9 to x
string s = "howdy!"; // initialize s with "howdy!"
s = "G'day"; // assign "G'day" to s
初始化时变量总是空的,而赋值操作首先销毁旧的值、之后赋予新值(相当于用新值覆盖旧值)。
注意:赋值运算符=不是数学上的“等于”,例如a = a + 7并不意味着“a等于a+7”,而是一个赋值语句,它所做的事如下:
- 得到a的值,例如4
- 计算a+7,得到整数11
- 将整数11赋予a
3.5.1 实例:检测重复单词
下面的程序在一连串单词中找到相邻重复的单词:
while (cin >> current)称为while语句,它意味着当输入操作cin >> current成功时,后面的语句将反复执行,而cin >> current成功的条件是标准输入中有可读取的字符。记住,对于string,>>读取的是空格分隔的单词。可以通过输入文件结尾(end of file, EOF)来终止这个循环。在Windows系统中,使用Ctrl+Z紧接着一个回车;在UNIX或Linux系统中,使用Ctrl+D。
每次读取一个单词到current,将它与前一个单词previous比较,如果相同则打印出来。之后要对下一个单词重复上述操作,因此将current拷贝到previous。对于第一个单词没有前一个单词可以比较,通过将previous初始化为" "(只包含一个空格字符)来解决这一问题,因为输入运算符>>会跳过空格,不可能通过输入得到包含空格的字符串,因此第一次执行while语句时,测试if (previous == current)失败(正如我们所希望的)。
理解程序流程的一种方式是“推演计算机的运行”(play computer),也就是按照程序逐行执行指定的操作。在一张纸上画出很多方块(表示变量),然后在里面写入程序运行的结果,按程序指定的方式修改存储在其中的值。
3.6 组合赋值运算符
对任意二元运算符op,a op= b等价于a = a op b。例如:
1
2
3
a += 7; // means a = a + 7
b -= 9; // means b = b - 9
c *= 2; // means c = c * 2
递增一个变量(加1)在程序中很常用,因此C++提供了一个特殊的语法++:++counter等价于counter += 1和counter = counter + 1,递减也有类似的运算符--。
3.6.1 实例:查找重复单词
考虑上面检测相邻重复单词的例子,可以通过得到重复单词在序列中的位置来改进程序:
使用单词计数器来表示当前档次的位置,每次看到一个单词,就将这个计数器递增:++number_of_words;
注意,这个程序与3.5.1节中的程序是如此相似。很明显,我们只是将这个程序从3.5.1节拿来,并对它进行一点儿修改以实现我们的目标。这是一个非常通用的技术:当需要解决一个问题时,找到一个相似的问题并用我们的方案加以适当修改。不要从头开始,除非你不得不这样做。 在一个程序早期版本的基础上修改通常会节省大量时间,我们将会从深入原始程序中受益良多。
3.7 命名
在C++中,名字必须以字母开头,并且只能包含字母、数字和下划线。例如:
1
2
3
4
5
x
number_of_elements
Fourier_transform
z2
Polygon
下面的不是名字:
1
2
3
2x
time$to$market
Start menu
在系统代码或机器生成的代码中可能看到下划线开头的名字,例如_foo,这样的名字是为编译器和系统实体保留的,在自己的代码中要尽量避免。
名字是区分大小写的,因此x和X是不同的名字。
在定义名字时只用一个字符来区分通常不是一个好主意,例如one和One,它不会使编译器混淆,但容易使程序员混淆。
C++关键字不能用作变量、类型、函数等的名字。例如:
1
int if = 7; // error: "if" is a keyword
可以使用标准库中的名字(例如string),但是不应该这样做(因为这将屏蔽标准库中的名字)。例如:
1
2
int string = 7; // this will lead to trouble
string s = "abc"; // error: expected ';' before 's'
最好为变量、函数、类型等选择有意义的、有助于别人理解你的程序的名字。避免使用简单但无意义的名字(例如x1、s3、p7)和仅有首字母的缩写(例如mtbf、TLA、myw、NBV)。
短名字在按习惯使用时是有意义的,例如习惯上使用i作为循环变量。
不要使用很长的名字,它们难以输入,也难以快速读取,例如the_number_of_elements、remaining_free_slots_in_symbol_table。下面这些名字可能是合适的:partial_sum、element_count、stable_partition。
C++的风格是在标识符中使用小写字母加下划线,例如element_count,而不是其他风格(例如驼峰命名法elementCount或ElementCount)。不使用全部大写字母的名字(例如ELEMENT_COUNT),因为这通常是为宏保留的。自定义类型使用首字母大写,例如Square、Graph。C++语言和标准库不使用首字母大写的风格,因此使用int而不是Int,string而不是String。
避免使用容易打错、读错或混淆的名字,例如字符0、o、O、1、l、I。
3.8 类型和对象
类型的概念是C++和大多数编程语言的核心。
- 类型(type)定义一组可能的值和一组操作(对于一个对象)
- 对象(object)是用来保存一个指定类型的值的一些内存单元
- 值(value)是内存中根据类型来解释的一组比特位
- 变量(variable)是一个命名的对象
- 声明(declaration)是命名一个对象的语句
- 定义(definition)是为一个对象分配内存空间的声明
我们可以非正式地将对象看作一个盒子,可以将指定类型的值放入其中。例如:
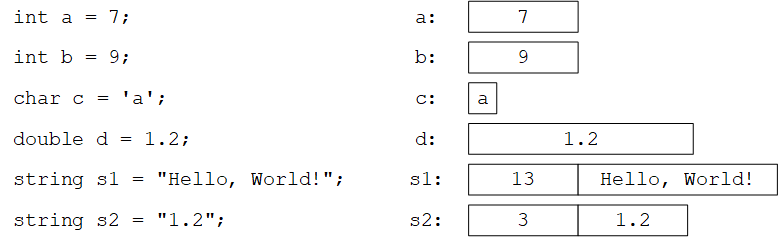
每个int的大小是相同的,通常是4字节(32比特)。与此类似,bool、char和double都是固定大小的,通常分别是1字节、1字节和8字节。而string不是固定大小的,不同大小的字符串占用不同大小的空间。
在内存中比特的含义完全依赖于访问它时所用的类型。计算机内存不知道我们的类型,只是将它保存起来。只有当我们决定如何解释时,内存中的比特位才有意义。例如,我们并不知道12.5的含义是什么,可以是$12.5、12.5 cm或12.5 gallons。只有当我们使用单位时,才会定义12.5的含义。
例如,(除了前导0)相同的比特位视为int时表示值120,而视为char时表示'x':

3.9 类型安全
当一个程序仅按照一个对象的类型的规则(支持的操作)使用该对象时,该程序是类型安全(type-safe)的。然而,有很多执行操作的方式不是类型安全的。例如,使用未初始化的变量:
1
2
3
double x; // we "forgot" to initialize: the value of x in undefined
double y = x; // the value of y is undefined
double z = 2.0 + x; // the meaning of + and value of z are undefined
记得初始化你的变量! 这个规则只有很少的例外,例如立即将一个变量作为输入目标。
3.9.1 安全类型转换
在3.4节中看到不能直接将char相加,或者将double与int比较。但是,C++提供间接方式:在需要时,char可以转换成int,int可以转换成double。例如:
1
2
3
char c = 'x';
int i1 = c;
int i2 = 'x';
这里的i1和i2都被赋值为120,这是字符 ‘x’ 在ASCII字符集中的整数值。这种char到int的转换是安全的,因为没有丢失信息。也就是说,可以将结果int (i1)拷贝回char (c2),并且得到原始的值:
1
2
char c2 = i1;
cout << c << ' ' << i1 << ' ' << c2 << '\n';
将会打印
1
x 120 x
(类似于将500 mL的杯子中的水倒入一个2 L的桶,再倒回杯子)
如果一个值总是被转换成一个相等的值,或者一个最接近相等的值(对于double),那么转换就是安全的。
按照“从小到大”方向的转换是安全的:
1
bool -> char -> int -> double
最常用的转换是从int到double,因为它允许在表达式中混合使用int和double:
1
2
3
4
double d1 = 2.3;
double d2 = d1 + 2; // 2 is converted to 2.0 before adding
if (d1 < 0) // 0 is converted to 2.0 before comparison
error("d1 is negative");
3.9.2 不安全类型转换
C++也允许(隐式的)不安全转换。所谓不安全,是指一个值可以转换成一个不等于原始值的其他类型的值。例如:
1
2
3
4
5
6
7
8
9
int main() {
int a = 20000;
char c = a; // try to squeeze a large int into a small char
int b = c;
if (a != b) // != means "not equal"
cout << "oops!: " << a << "!=" << b << '\n';
else
cout << "Wow! We have large characters\n";
}
b的值将会变成32,在内存中的表示如下图所示:

由于int占4个字节,而char只有1个字节,在将a赋值给c时,前3个字节(红色部分)丢失了。这种转换称为缩小转换(narrowing conversions)(类似于将2 L的桶中的水倒入一个500 mL的杯子,再倒回桶)。
按照“从大到小”方向的转换是不安全的:
1
bool <- char <- int <- double
但这些转换仍然会被编译器接受。
注意:double到int的转换会截断(丢掉小数部分),而不是四舍五入。
C++11引入了{}初始化语法,称为通用统一初始化(universal and uniform initialization),当初始化发生缩小转换时,编译器将报错。例如:
1
2
3
4
5
double d{2.7}; // OK
int y{x}; // error: double -> int might narrow
int a{1000}; // OK
char b{a}; // error: int -> char might narrow
char b2{48}; // OK
如果转换可能导致一个错误值,应该使用{}初始化,或者像本节开头的例子一样在赋值之后对值进行检查。5.6.4节给出了更简单的方式。