《C++程序设计原理与实践》笔记 第10章 输入/输出流
在本章和下一章中,我们将介绍C++标准库中用于处理来自各种源的输入和输出的功能:I/O流。本章关注基本模型:如何读写单个值,以及如何打开和读写整个文件。下一章将介绍具体细节。
10.1 输入和输出
如果没有数据,计算就毫无意义。我们需要将数据输入到程序中来进行一些有价值的计算,并获取输出。数据的输入源和输出目标非常广泛。因此,我们需要一种将程序的读写操作与实际使用的输入/输出设备分离的方法。
I/O库提供了I/O的一个抽象,从而程序员不必关心设备和设备驱动程序:
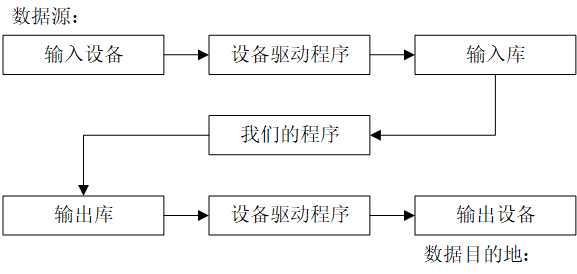
使用这样是模型,输入和输出就可以看作由I/O库处理的字节(字符)流。程序员的工作就变为:
- 创建数据源或目的地的I/O流
- 读写这些流
从程序员的角度,输入和输出有很多种。例如:
- 大量数据项构成的流(文件、网络连接、录音设备、显示设备等)
- 通过键盘与用户交互
- 通过图形界面与用户交互
其中,前两种I/O由C++标准库I/O流提供,图形用户交互则由其他一些库支持(第12~16章)。
10.2 I/O流模型
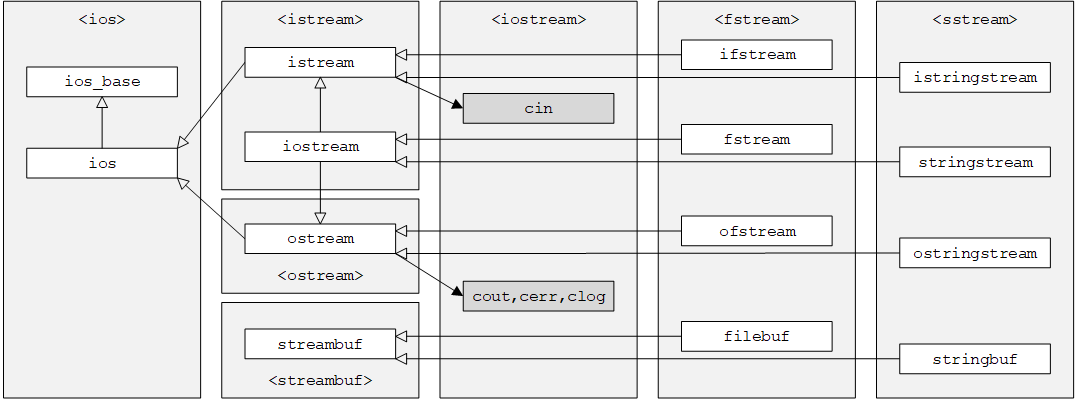
C++标准库<iostream>提供了istream类型来处理输入流、ostream类型来处理输出流。我们已经使用过标准输入流cin和标准输出流cout。
注:各种I/O流及继承关系如下图所示(详见Input/Output library)
ostream负责
- 将不同类型的值转换为字符序列
- 将这些字符发送到“某处”(例如控制台、文件、内存或者另一台计算机)
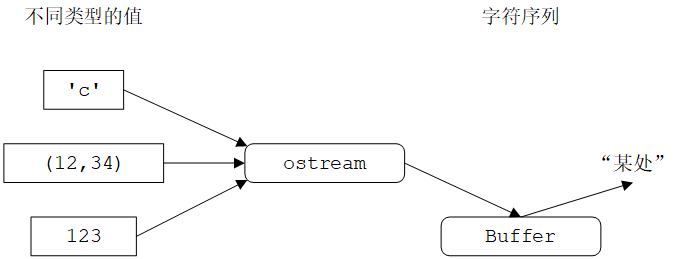
缓冲区(buffer)是ostream内部用于保存数据并与操作系统通信的数据结构。如果写入ostream和字符出现在目的设备之间存在“延迟”,通常是因为字符还在缓冲区中。缓冲是提高性能的重要技术,而处理大量数据时性能是很重要的。
istream负责
- 将字符序列转换为不同类型的值
- 从“某处”(例如控制台、文件、内存或者另一台计算机)读取字符
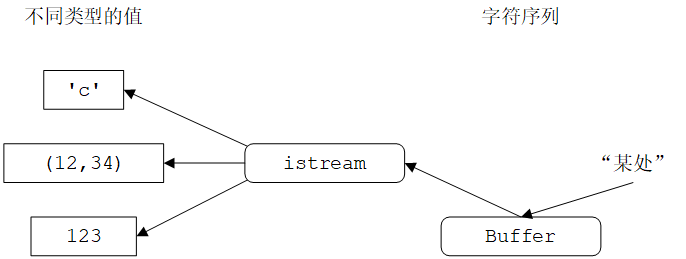
与ostream一样,istream也使用缓冲区来与操作系统通信。对于istream,缓冲区对用户是可见的。例如,使用cin从键盘输入数据时,输入的内容都留在缓冲区中,直到按Enter键,在此之前可以通退格键清除字符来“改变主意”。
10.3 文件
基本上,文件就是一个从0开始编号的字节序列:

文件具有格式,即有一组规则来确定字节的含义。 例如,文本文件中,一个字节表示一个字符(在特定字符集下的编码);使用二进制表示整数的文件中,4个字节表示一个整数,如下图所示。只有知道文件的格式才能知道文件中字节数据的含义。

例如,在文本文件中,48 65 6c 70四个字节分别表示 ‘H’, ‘e’, ‘l’, ‘p’ 四个字符;而在二进制整数文件中,同样的四个字节表示十六进制数0x706c6548(小端顺序),等于十进制的1886152008。
注:一个字节(byte)是8个比特位(bit),能表示的二进制数范围是00000000~11111111,即十进制的0~255、十六进制的00~ff。
对于一个文件,ostream将内存中的对象转换为字节流,并将其写入磁盘。istream进行相反的操作:从磁盘读取字节流,并将其转换为对象:

为了读一个文件,需要知道文件名,(以读模式)打开文件,读入字符,关闭文件(通常隐式完成)。为了写一个文件,需要知道文件名,(以写模式)打开文件,写出对象,关闭文件(通常隐式完成)。
10.4 打开文件
如果要读写文件,必须打开一个专门用于该文件的流。ifstream是用于读文件的istream,ofstream是用于写文件的ostream,fstream是既可以读文件又可以写文件的iostream,这些类型定义在标准库头文件 <fstream> 中。在使用文件流之前,必须将其关联到文件。例如:
1
2
3
4
5
6
7
// write to file
string filename = "test.txt";
ofstream ofs(filename); // open file for writing
if (!ofs.is_open()) // check if file is open
cout << "failed to open " << filename << endl;
else
ofs << 123 << "abc"; // write to ofstream
ofstream的构造函数参数指定文件名,如果文件不存在则创建。成员函数is_open()检查文件是否被成功打开(文件流是否成功关联到文件),如果打开失败则返回false。之后可以像任何ostream一样使用运算符<<写出数据。
例如,如果上面的代码运行成功,则文件test.txt的内容如下:
1
123abc
ifstream的用法与ofstream类似:
1
2
3
4
5
6
7
8
9
10
11
// read from file
string filename = "test.txt";
ifstream ifs(filename); // open file for reading
if (!ifs.is_open()) // check if file is open
cout << "failed to open " << filename << endl;
else {
int n;
string s;
ifs >> n >> s; // read from ifstream
cout << "n = " << n << ", s = " << s << endl;
}
ifstream的构造函数参数指定文件名,文件必须存在。成员函数is_open()检查文件是否被成功打开,如果因文件不存在、没有权限等原因打开失败则返回false。之后可以像任何istream一样使用运算符>>读取数据。
例如,test.txt的内容为上一段代码的输出结果,则这段代码的输出如下:
1
n = 123, s = abc
通常,最好在重要的计算开始之前就打开文件。毕竟,如果在完成计算之后才发现无法保存结果将会浪费计算资源。
当一个文件流离开作用域时,它关联的文件将被关闭,文件流内部的缓冲区会被刷新(flush),即缓冲区中的字符会被写入文件。
在创建文件流时打开文件、依赖流的作用域来隐式关闭文件是一种理想的方法。 另外,也可以通过open()和close()函数显式打开和关闭文件。然而,依赖作用域的方式避免了两类错误:在打开文件之前或关闭文件之后使用文件流对象。例如:
1
2
3
4
5
6
7
8
9
10
ifstream ifs;
// ...
ifs >> foo; // won't succeed: no file opened for ifs
// ...
ifs.open(name); // open file named name for reading
// ...
ifs.close(); // close file
// ...
ifs >> bar; // won't succeed: ifs's file was closed
// ...
不能在关闭一个文件流之前第二次打开它。例如:
1
2
3
4
5
fstream fs;
fs.open("foo", ios_base::in); // open for input
// close() missing
fs.open("foo", ios_base::out); // won't succeed: fs is already open
if (!fs) error("impossible");
其中,第二次调用open()后,fs通过运算符operator bool转换为布尔值false,表示处于失败状态(详见10.6节),但is_open()仍然为true;如果第一次open()失败了,则fs和is_open()都是false。
在打开一个流之后不要忘记检测是否成功。
注:fstream构造函数的第二个参数是打开模式,详见11.3.1节。
10.5 读写文件
考虑这样一个问题:如何从文件读取一组测量结果并在内存中表示?例如,从气象站获取的温度数据:
1
2
3
4
5
0 60.7
1 60.6
2 60.3
3 59.22
...
这个数据文件包含了一系列(小时,温度)数值对。小时的值为0~23,温度为华氏度,没有任何其他格式。这是最简单的情况。
其中的while循环是一个典型的输入循环,ifs可以是任何一种istream,这段代码都能够适用,因为所有的istream都支持运算符>>。对于输出流也是同理。
10.6 I/O错误处理
在处理输入时,我们必须预料到并处理错误。 错误的原因可能是人为失误(理解错了指令、打字错误、让猫在键盘上散步等)、文件格式不符合规范、我们(程序员)预料错误,等等。输入错误的可能性是无限的,但istream将所有可能的情况归结为四类,称为流状态(stream state)。
流状态用枚举ios_base::iostate表示,其各枚举值都是只有一个二进制位为1、其他位均为0的整数(2的幂),即位掩码,可以使用按位或(bitwise OR)运算符|组合:
| 流状态 | 含义 |
|---|---|
goodbit | 操作成功 |
eofbit | 到达输入结尾(“end of file”, EOF) |
failbit | 发生意外情况 |
badbit | 发生严重意外情况 |
注:istream提供了一些成员函数来检查和更新错误状态
| 成员函数 | 作用 |
|---|---|
rdstate() | 返回流状态 |
setstate() | 将流状态与给定值按位取或(即设置指定的状态位,其他状态位不变) |
clear() | 将流状态设置为给定值,默认为goodbit(即设置指定的状态位,清除其他状态位) |
good() | 如果没有任何错误标识被置位则返回true,等价于rdstate() == goodbit |
eof() | 如果eofbit被置位则返回true |
fail() | 如果failbit或badbit被置位则返回true |
bad() | 如果badbit被置位则返回true |
operator bool | 等价于!fail() |
operator! | 等价于fail() |
failbit和badbit之间的区别并未准确定义(由流的作者决定),但基本思想是:如果输入操作遇到简单的格式错误(例如读取数字时遇到 ‘x’)则设置failbit,即假定此时可以从错误中恢复;如果遇到严重错误(例如磁盘读故障)则设置badbit,即假定此时只能放弃从这个流获取数据。bad()状态的流也是fail()状态,因此有如下的通用逻辑:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
int i = 0;
s >> i;
if (!s) {
// we get here (only) if an input operation failed
if (s.bad()) // stream corrupted: let's get out of here!
error("cin is bad");
if (s.eof()) {
// no more input
// this is often how we want a sequence of input operations to end
}
if (s.fail()) {
// stream encountered something unexpected
s.clear(); // make ready for more input
// somehow recover
}
}
注意处理fail()时所使用的clear():为了从错误中恢复,通过clear()将流恢复到good()状态(否则后续输入操作都会失败)。
下面是一个如何使用流状态的例子。假设要读取一系列整数到一个vector中,以字符 “*” 或EOF(Windows系统是Ctrl+Z,UNIX系统是Ctrl+D)结束。例如:
1
1 2 3 4 5 *
可以使用以下函数实现:
这段代码看似不复杂,但实际上有很多需要注意的细节:
- 运算符
>>遇到输入结尾时,输入流的eofbit和failbit都会被设置。运算符>>的返回值是输入流本身,而istream定义了operator bool(即将输入流本身解释为布尔值),因此将ist >> i作为for循环测试条件的含义是:先执行输入操作,之后判断ist.operator bool()是否为true。另外,operator bool等价于!fail(),而fail()在failbit或badbit被设置时都会返回true。综上,无论输入操作遇到输入结尾、格式错误还是严重错误,fail()都会返回true,operator bool都会返回false。 - 在尝试读取终结符之前,必须先调用
clear()将所有的错误状态清除,否则输入操作ist >> c将会失败。 - 如果读取的字符不是终结符,则使用
unget()将该字符放回ist(输入操作不能随意丢弃未使用的字符),并通过ist.clear(ios_base::failbit)将流状态重新设置为failbit(表示遇到了格式错误)。带参数的clear()有些令人迷惑:设置指定的状态位,清除其他状态位(名字叫 “clear” ,但也会 “set” )。unget()是putback()(见6.8.1节)的简洁版,它依赖流记住最后一个字符是什么,而不需要在参数中给出。 exceptions()是作用是:当流处于指定的状态时,将抛出标准库异常ios_base::failure。因此在fill_vector()中不必单独处理bad()(在几乎所有情况下,我们能做的也只是抛出异常)。- 如果需要,
fill_vector()的调用者可以通过测试ist的eof()、fail()或捕获异常来知道输入终止的原因。
ostream也有与istream相同的四种状态。但对于本书中的程序,输出错误比输入错误罕见得多,因此通常不检测ostream的状态。
10.7 读取单个值
上一节展示了如何读取一系列值,并以EOF或特定终结符结束。本节来看一个非常常见的例子:不断要求用户输入一个值,直到输入的值满足要求。例如,要求用户输入一个1到10之间的整数:
1
2
3
4
5
cout << "Please enter an integer in the range 1 to 10 (inclusive):\n";
int n = 0;
while (cin >> n && !(1 <= n && n <= 10)) // read and check range
cout << "Sorry " << n << " is not in the [1:10] range; please try again\n";
// ... use n here ...
这段代码只“在某种程度上正常工作”(只有在用户小心地输入整数的情况下),因为没有处理两种情况:(1)输入的不是整数,例如输入 “t” ;(2)遇到EOF,例如用户(测试人员)直接按了Ctrl+Z。这会导致程序直接退出循环而没有改变n的值,使得n的值(初始值0)在要求的范围之外。为了获得可靠的输入,我们必须处理三个问题:
- 用户输入超出范围的值
- 没有输入任何值(EOF)
- 用户输入错误类型的值(不是整数)
在这三种情况下我们想要做什么?这也是编写程序时经常遇到的问题:我们真正想要的是什么? 在这里,对于每个错误都有三种选择:
- 在负责输入的代码中(局部)处理错误
- 抛出异常,让其他人来处理(可能会终止程序)
- 忽略错误
个人使用的简单程序可以做任何想做的事,包括忽略错误检查。但是,对于想要长时间运行的程序,忽略这些错误就是愚蠢的;如果想要和其他人共享程序,就不应该在代码的错误检查中留坑。因此,只要有两个人参与,第三种策略就是不能接受的。
在第一种和第二种策略之间选择是困难的,应该具体问题具体分析。例如,对于读取一系列值的程序(例如10.5节和10.6节中的例子):
- 遇到EOF:正常结束
- 遇到超出范围的值:抛出异常
- 遇到错误类型的值:直接结束(10.5节),或者尝试从错误中恢复并继续读取(10.6节)
对于本节中读取单个值的例子:
- 遇到EOF:抛出异常
- 遇到超出范围的值:输出错误信息并继续读取
- 遇到错误类型的值:尝试从错误中恢复并继续读取
10.7.1 将问题分解为可处理的部分
下面尝试既处理超出范围的输入,又处理错误类型的输入:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
cout << "Please enter an integer in the range 1 to 10 (inclusive):\n";
int n = 0;
while (true) {
cin >> n;
if (cin) { // we got an integer; now check it
if (1 <= n && n <= 10) break;
cout << "Sorry " << n << " is not in the [1:10] range; please try again\n";
}
else if (cin.fail()) { // we found something that wasn't an integer
cin.clear(); // set the state back to good(); we want to look at the characters
cout << "Sorry, that was not a number; please try again\n";
for (char ch; cin >> ch && !isdigit(ch);) // throw away non-digits
/* nothing */ ;
if (!cin) error("no input"); // we didn't find a digit: give up
cin.unget(); // put the digit back, so that we can read the number
}
else {
error("no input"); // eof or bad: give up
}
}
// if we get here n is in [1:10]
这段代码又乱又冗长,但我们确实需要处理潜在的错误。这段代码之所以乱是因为处理好几件不同事情的代码都混在一起了:
- 读取值
- 提示用户输入
- 输出错误信息
- 跳过“有问题的”(“bad”)字符(这里指非数字字符)
- 判断整数范围
一种常用的令代码更加清晰的方法是将逻辑上独立的代码划分为独立的函数(见4.5.1节):
函数skip_to_int()跳过所有的非数字字符,直到遇到下一个数字或EOF(抛出异常)。函数get_int()持续读取输入,直到成功读取一个整数,读取失败时调用skip_to_int()尝试从错误中恢复。要想结束get_int(),必须输入一个整数或EOF。带参数的get_int()不断地从无参数的get_int()获取整数,直到整数在指定范围内。
注:C++支持函数重载(function overloading),即定义两个名字相同、参数表不同的函数或运算符(但不能只有返回类型不同)。调用函数时,编译器将根据实际参数进行重载解析,确定调用哪一个重载函数。例如,get_int()调用的是int get_int(),get_int(1, 10)调用的是int get_int(int, int),get_int(1)则是编译错误。
10.7.2 将对话与函数分离
get_int()函数仍然混合着读取输入和输出提示信息。对于简单的程序这没什么问题,但在大型程序中可能需要输出不同的提示信息。可以将(一部分)提示信息作为函数参数,从而可以像这样调用get_int():
1
2
3
4
5
6
7
int strength = get_int(cin, 1, 10, "Enter strength", "Not in range, try again");
cout << "strength: " << strength << endl;
int altitude = get_int(cin, 0, 50000,
"Please enter altitude in feet",
"Not in range, please try again");
cout << "altitude: " << altitude << "f above sea level\n";
10.8 用户自定义输出运算符
为一个给定类型定义输出运算符<<很简单。即使无法提供一种令所有用户都满意的输出格式,为用户自定义类型定义<<通常也是个好主意,这样可以在调试时很容易地输出这个类型的对象。
自定义输出运算符的语法如下:
1
ostream& operator<<(ostream& os, const T& obj);
例如,为9.8节中的Date定义的输出运算符简单地打印年、月、日,用逗号分隔,两边加括号:Chrono.cpp,这会将2004年8月30日输出为 “(2004,8,30)” 。这种简单的成员列表表示法适合用于成员较少的类型。
9.6节提到,用户自定义运算符本质上是函数调用,因此cout << d1等价于operator<<(cout, d1)。
注意,operator<<将接受ostream&作为第一个参数,又将其作为返回值,这就是为什么可以将输出操作“链式”调用。 例如,以下四种形式是等价的:
1
2
3
4
cout << d1 << d2;
operator<<(cout, d1) << d2;
operator<<(cout << d1, d2);
operator<<(operator<<(cout, d1), d2);
显然第一种形式最易读。
10.9 用户自定义输入运算符
为一个给定类型和指定的输入格式定义输入运算符>>难点在于错误处理,因此可能会很棘手。语法如下:
1
istream& operator>>(istream& is, T& obj);
当读取失败时,应当通过setstate()或clear()设置相应的错误状态。
例如,为Date定义的输入运算符按照运算符<<的输出格式读取日期:Chrono.cpp。显然,输入比输出更难处理,因为输入更容易出错(输出不存在EOF和格式错误,设备故障也基本不需要考虑)。
如果运算符»遇到输入格式错误,应该使输入流进入非正常状态(通常是fail),并且不改变目标对象。
对于运算符»,理想情况是不要丢弃任何未使用的字符,但这通常很困难,因为在发现格式错误时可能已经读取了大量字符。例如,考虑输入 “(2004, 8, 30}” ,只有当看到最后的 “}” 时才能知道遇到了格式错误。一般来说,不能putback()多个字符,唯一可以保证的是unget()一个字符(例如,多次调用cin.putback()会使cin进入bad状态)。
10.10 一个标准的输入循环
10.5节的例子中的输入循环假定能够从头到尾地读取文件,没有仔细地处理错误(只要读取失败就立即结束,无论遇到EOF、格式错误还是设备故障)。这个假设或许是合理的,因为我们通常单独检查文件是否有效(例如在读取之前检查文件格式)。但是,我们通常想要在读取的同时进行检查。下面是一种通用的策略,假设ist是一个istream:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
// somewhere: make ist throw an exception if it goes bad:
ist.exceptions(ios_base::badbit);
My_type var;
while (ist >> var) { // read until end of file
// maybe check that var is valid
// do something with var
}
end_of_loop(ist, '|', "bad termination of file"); // test if we can continue
// carry on: we found end of file
void end_of_loop(istream& ist, char terminator, const string& message) {
if (ist.fail()) { // use term as terminator and/or separator
ist.clear();
char ch;
if (ist >> ch && ch == terminator) return; // all is fine
error(message);
}
}
注:基本上,这段代码是将10.5节中的输入循环与10.6节中的错误处理结合起来。
这样一个输入循环对于很多用途足够简单、足够通用。
10.11 读取结构化的文件
下面尝试应用这个“标准输入循环”来解决一个实际问题。假设你有一个温度读数的文件,其结构为:
- 文件包含若干年份的读数
- 年份的读数以 “{ year” 开始,后面跟着一个表示年份的整数(例如1900)和若干个月份的读数,最后以 “}” 结束
- 月份的读数以 “{ month” 开始,后面跟着三个字母的月份名称(例如jan)和若干个读数,最后以 “}” 结束
- 读数以 “(“ 开始,后面跟着日、小时和温度,最后以 “)” 结束
例如:
1
2
3
4
5
6
7
{ year 1990 }
{year 1991 { month jun }}
{ year 1992 { month jan ( 1 0 61.5) } {month feb (1 1 64) (2 2 65.2) } }
{year 2000
{ month feb (1 1 68 ) (2 3 66.66 ) ( 1 0 67.2)}
{month dec (15 15 -9.2 ) (15 14 -8.8) (14 0 -2) }
}
注:这个文件格式可以用文法来定义
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
G = (V, T, P, YearList)
V = {YearList, Year, MonthList, Month, MonthName, ReadingList, Reading}
T = {"{", "}", "(", ")", "year", "month", "jan", ..., "dec", integer-literal, float-literal}
产生式规则如下:
YearList:
Year YearList
Year
Year:
"{" "year" integer-literal MonthList "}"
MonthList:
Month MonthList
Month
Month:
"{" "month" MonthName ReadingList "}"
MonthName:
"jan"
...
"dec"
ReadingList:
Reading ReadingList
Reading
Reading:
"(" integer-literal integer-literal float-literal ")"
10.11.1 内存表示
如何在内存中表示这些数据?显而易见的首选是三个类(分别对应文法中同名的非终结符):
Year:包含年份和各个月份的数据Month:包含月份和各个读数Reading:读数(日, 小时, 温度)
其中Year和Month与我们考虑温度和天气的一般方式是吻合的;而Reading是底层硬件(如传感器)的表示形式,并且是非结构化的(读数不保证按照日期或小时的顺序给出)。因此,Reading仅用于读取原始数据,用Day表示一天中各个小时的数据,从而可以将Year表示为12个Month的向量、Month表示为31个Day的向量、Day表示为24个double(温度)的向量。
10.11.2 读取结构化的值
分别为Reading、Month和Year定义运算符>>:
基本上,我们先检查格式开头是否合理(是否以 “(“ 或 “{“ 开始),如果不是,则直接将流状态置为fail()并返回。另一方面,如果在读取了一些数据后才发现格式错误,则没有恢复的机会,直接抛出异常。
注:
- 在
Month的>>中,使用一个循环读取任意数量的Reading。无论一个月份的数据中是否包含具体读数,最后的 “}” 都可以作为读取Reading结束的标志。如果发现某个日期、小时的温度数据已经有值了(即!= not_a_reading)则表示当前读数是重复的。 - 由于
Reading的>>(在读取成功时)会覆盖Reading的所有成员,因此在Month的>>中每次循环都可以使用同一个Reading对象。相反,在Year的>>中每次循环必须创建一个新的Month对象(通过将m放在循环体内),否则每次读取的月份的数据都会包含上一个月份的数据(因为没有重置day向量)。
10.11.3 改变表示
Month的>>需要读取月份的符号表示并转换为整数。这里用一个vector<string>加一个查询函数int_to_month()来实现:正向转换(月份名称→整数)时需要遍历向量查找月份名称并返回对应的下标,反向转换(整数→月份名称)只需用[]即可。
C++标准库提供了一种简单的方式:map<string, int>(见21.6.1节)(但不便于反向转换)。
本例中使用的技术很简单,但在没有帮助的情况下发现它并不容易。读取数据、正确编写输出循环(正确初始化用到的每一个变量)、转换表示方式都是很基本的。因此,你应该学会这些。