《C++程序设计原理与实践》笔记 第17章 向量和自由存储
本章和后面四章介绍C++标准库的容器和算法部分(通常称为STL)。本章和后面两张的重点是最常用、最有用的STL容器——向量的设计和实现。
17.1 引言
C++标准库中最有用的容器是vector。vector提供了给定类型的元素序列。标准库vector是一个方便、灵活、(时间和空间上)高效、静态类型安全的元素容器。
在本章和后面两章中,我们将展示如何用基本语言功能来构建vector,从而说明有用的概念和编程技术,并通过C++语言特性表达出来。我们在实现vector中遇到的语言功能和编程技术是通用并且被广泛使用的。
我们通过一系列逐渐复杂的vector实现来接近标准库vector。
17.2 vector基础
首先考虑vector的一个非常简单的用法:
1
2
3
4
5
vector<double> age(4); // a vector with 4 elements of type double
age[0]=0.33;
age[1]=22.0;
age[2]=27.2;
age[3]=54.2;
这段代码创建了一个有四个double类型元素的向量,并给四个元素分别赋值为0.33、22.0、27.2和54.2。这四个元素编号为0、1、2、3。C++标准库容器中的元素编号始终从0开始。 向量中的元素个数称为大小(size),元素编号(索引)从0到size-1。可以用下图来表示age:

如何在计算机内存中实现这种“图形化设计”?显然,我们需要定义一个类vector,它需要一个存储大小的数据成员和一个存储元素的数据成员。但是如何表示一组数量可变的元素?我们需要第一个元素的内存地址。在C++中,可以存储地址的数据类型称为指针(pointer)。
于是,可以定义我们自己的第一个版本的vector类:
1
2
3
4
5
6
7
8
9
10
// a very simplified vector of doubles
class vector {
int sz; // the size
double* elem; // pointer to the first element (of type double)
public:
vector(int s); // constructor: allocate s doubles,
// let elem point to them
// store s in sz
int size() const { return sz; } // the current size
};
在进行vector的设计之前,首先学习“指针”和与它紧密相关的“数组”的概念——这是C++“内存”概念的关键。
17.3 内存、地址和指针
计算机内存是一个字节序列,这些字节从0开始编号。用于指示内存位置的编号称为地址(address)。地址本质上就是一个整数。例如,可以将1 MB (= 210 KB = 220 B)内存可视化为以下图形:

其中每个方格表示一个字节(内存单元),这些字节的编号(地址)依次为0, 1, 2, …, 220-1。
内存中的任何对象都有一个地址。例如:
1
int var = 17;
该语句为var分配了一块“int大小”(通常是4字节)的内存空间,并将值17放入这块内存。保存地址的对象称为指针(pointer),在语法上T*是“指向T的指针”。例如:
1
int* ptr = &var; // ptr holds the address of var
取地址(address of)运算符&用于获得对象的地址。在这里ptr是指向var的指针,其值是var的地址。假设var的地址是4096,则ptr的值为4096:

注:假设一个int占4字节,则var实际上占用了4096~4099连续的4个字节,对象的地址是首字节的地址。
解引用(dereference)运算符*用于访问指针指向的对象。例如:
1
cout << "pi==" << pi << "; contents of pi==" << *pi << "\n";
可能的输出为
1
pi==0x649ff8b4; contents of pi==17
pi的值取决于编译器在内存中为变量var分配的地址(每次运行程序都会变化)。指针的值(地址)通常用十六进制表示。
解引用运算符也可以用于赋值运算符的左侧(pi是指针本身,*pi是指针指向的对象):
1
*pi = 27; // OK: you can assign 27 to the int pointed to by pi
注意,即使指针的值可以被打印为一个整数,但指针不是int,二者不能混淆:
1
2
int i = pi; // error: can't assign an int* to an int
pi = 7; // error: can't assign an int to an int*
不同类型的指针也不能混用。例如,指向char的指针不能指向int:
1
2
char* pc = pi; // error: can't assign an int* to a char*
pi = pc; // error: can't assign a char* to an int*
17.3.1 sizeof运算符
运算符sizeof用于获取对象或类型的大小(占用的内存字节数):
1
2
3
4
5
void sizes(char ch, int i, int* pi) {
cout << "the size of char is " << sizeof(char) << ' ' << sizeof(ch) << '\n';
cout << "the size of int is " << sizeof(int) << ' ' << sizeof(i) << '\n';
cout << "the size of int* is " << sizeof(int*) << ' ' << sizeof(pi) << '\n';
}
sizeof可用于类型名或表达式。sizeof的结果是一个正整数,单位是sizeof(char)(定义为1)。
C++基本类型的长度如下表所示:
| 类型 | 长度 | 指针类型 | 指针长度 |
|---|---|---|---|
bool | 1 | bool* | 4或8 |
char | 1 | char* | 4或8 |
short | 2 | short* | 4或8 |
int | 2或4 | int* | 4或8 |
long | 4或8 | long* | 4或8 |
long long | 8 | long long* | 4或8 |
float | 4 | float* | 4或8 |
double | 8 | double* | 4或8 |
注:
- C++标准规定
int类型的大小至少是2字节,在不同的机器上可能是2字节或4字节;类似地,long类型的长度可能是4字节或8字节。详见Fundamental types “Integer types” 一节。 - 标准库头文件<cstdint>定义了一组固定宽度整数类型(别名),例如
int32_t、int64_t等。 - 对于指针类型,在32位系统上是4字节,在64位系统上是8字节(指针的大小只与内存地址空间的大小有关,与实际类型无关)。
一个vector占用多少内存?尝试
1
2
3
cout << "the size of vector<int>(10) is " << sizeof(vector<int>(10)) << '\n';
cout << "the size of vector<int>(100) is " << sizeof(vector<int>(100)) << '\n';
cout << "the size of vector<int>(1000) is " << sizeof(vector<int>(1000)) << '\n';
输出为
1
2
3
the size of vector<int>(10) is 24
the size of vector<int>(100) is 24
the size of vector<int>(1000) is 24
看过本章和下一章后,这个解释将会变得很明显,但显然sizeof不计入向量元素。
注:vector对象本身只包含大小和指向元素的指针等成员,元素不属于vector对象的一部分,否则vector对象的大小将是不确定的。
17.4 自由存储和指针
C++程序的内存布局(memory layout)如下图所示:
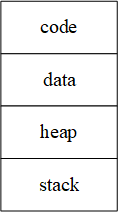
整个内存空间被划分为四部分:
- 代码段(code segment):也称为文本段(text segment),包含由代码编译生成的机器指令。
- 数据段(data segment):也称为静态存储(static storage),包含全局变量和静态变量。
- 栈(stack):也称为自动存储(automatic storage),包含局部变量和函数参数。
- 堆(heap):也称为自由存储(free storage)或动态内存(dynamic memory),可以通过
new运算符动态分配的内存。
参考:Memory Layout of C Programs
注:栈内存中的变量离开作用域时自动释放内存,而堆内存必须手动释放,否则将导致内存泄露。
例如:
1
double* p = new double[4]; // allocate 4 doubles on the free store
该语句在自由存储中分配4个double大小(32字节)的内存空间,并返回指向首地址的指针(假设为850),如下图所示:
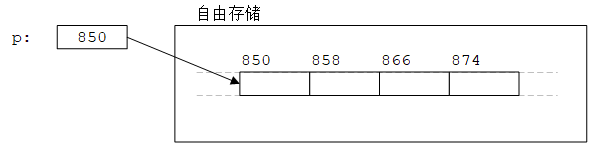
17.4.1 自由存储分配
new运算符从自由存储中分配内存,返回首字节的地址(指向它创建的对象或数组首元素的指针)。如果对象的类型是T,则返回的指针类型是T*。
new运算符可以为单个对象或数组分配内存。例如:
1
2
3
4
5
int* pi = new int // allocate one int
int* qi = new int[4]; // allocate 4 ints (an array of 4 ints)
double* pd = new double; // allocate one double
double* qd = new double[n]; // allocate n doubles (an array of n doubles)
注意分配的元素个数可以是变量,这允许我们在运行时指定分配多少个对象。
17.4.2 通过指针访问
除了在指针上使用解引用运算符*,还可以使用下标运算符[],这两个运算符既可用于读也可用于写。例如:
1
2
3
4
5
6
double* p = new double[4]; // allocate 4 doubles on the free store
double x = *p; // read the (first) object pointed to by p
double y = p[2]; // read the 3rd object pointed to by p
*p = 7.7; // write to the (first) object pointed to by p
p[2] = 9.9; // write to the 3rd object pointed to by p
当用于指针时,[]运算符将内存视为一系列对象(类型由指针声明指定)。p[i]等价于*(p+i)。
注:只有当指针指向数组中的元素时,使用[]运算符才有意义。
17.4.3 范围
指针的主要问题是指针并不“知道”它指向多少个元素(甚至不知道它指向单个对象还是数组中的某个元素)。例如:
1
2
3
4
5
double* p = new double; // allocate a double
double* q = new double[1000]; // allocate 1000 doubles
q[700] = 7.7; // fine
q = p; // let q point to the same as p
double d = q[700]; // out-of-range access!
其中第二个q[700](也就是p[700])是越界(out-of-range)访问,p[700]这个内存位置可能是其他对象的一部分。越界访问是一个典型的灾难性错误:“灾难性”表现为“程序神秘地崩溃”或者“程序给出错误的输出”。越界访问是特别令人讨厌的。越界读取会得到一个“随机”值,这取决于某些完全无关的对象;而越界写入可能会给某些对象意外的错误值。
我们必须保证这种越界访问不会发生。 我们使用vector而不是直接使用new分配的内存的原因之一是vector知道它的大小,因此可以很容易地避免越界访问。
17.4.4 初始化
我们希望确保指针及其指向的对象都是被初始化的。考虑:
1
2
3
4
double* p0; // uninitialized: likely trouble
double* p1 = new double; // get (allocate) an uninitialized double
double* p2 = new double(5.5); // get a double initialized to 5.5
double* p3 = new double[5]; // get (allocate) 5 uninitialized doubles
未初始化的指针是野指针(wild pointer),例如上面的p0。由于其值是随机的,使用未初始化的指针必定导致越界访问。
对于内置类型,new分配的内存是未初始化的,例如p1。可以使用()或{}来初始化,例如p2。
new创建的数组默认也是未初始化的。可以指定初始化列表(此时可以省略元素个数):
1
2
double* p4 = new double[5]{0, 1, 2, 3, 4};
double* p5 = new double[]{0, 1, 2, 3, 4};
注:如果指定了元素个数,但初始化列表中初始值个数少于元素个数,则剩余元素将被默认初始化。
对于自定义类型可以更好地控制初始化。如果类型有默认构造函数,则未指定初始值时将使用默认构造:
1
2
X* px1 = new X; // one default-initialized X
X* px2 = new X[17]; // 17 default-initialized Xs
如果类型有构造函数,但没有默认构造函数,则必须显式地初始化:
1
2
3
4
Y* py1 = new Y; // error: no default constructor
Y* py2 = new Y(13); // OK: initialized to Y(13)
Y* py3 = new Y[17]; // error: no default constructor
Y* py4 = new Y[17]{0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16};
当数组只有几个元素时,初始值列表将会很方便。
注:由此可知,如果自定义类型T没有默认构造函数,则不能使用new T[n]创建长度n为变量的动态数组,因为无法将所有元素初始化。
17.4.5 空指针
如果没有可用的值来初始化指针,则使用空指针(null pointer),nullptr:
1
double* p = nullptr; // the null pointer
空指针的值为0,通常用于测试一个指针是否有效(例如是否指向某个对象),例如if (p != nullptr),等价于if (p)。注意,对于未初始化的指针,这个测试是没有意义的。
注:
- 空指针可用于函数返回值表示异常情况,例如“未找到”或“发生了错误”。
nullptr是C++11引入的关键字,可以隐式转换为任意类型的指针。旧的代码使用0或NULL表示空指针。- 通过空指针或已经被删除的指针访问对象成员属于非法内存访问,会导致程序崩溃(coredump)。然而,可以通过空指针调用成员函数,只要不访问数据成员(不解引用)就没有问题。例如:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <iostream>
#include <map>
#include <string>
struct A {
std::string s;
int f() { return 42; }
const std::string& g() { return s; }
};
int main() {
A* a = nullptr;
std::cout << a->f() << '\n'; // OK, prints "42"
std::cout << &a->g() << '\n'; // OK, prints "0x0"
// std::cout << a->g() << '\n'; // error: segmentation fault
std::map<std::string, int> m;
auto it = m.find(a->g()); // OK, no dereference because m is empty
return 0;
}
17.4.6 自由存储释放
由于一台计算机的内存是有限的,因此在使用结束后应当将内存释放回自由存储,从而自由存储可以将这些内存重新用于新的分配。对于大型程序和长时间运行的程序(例如操作系统、嵌入式系统)来说,这种释放内存并重新使用是很重要的。
如果使用new分配的内存没有被释放,并且离开了保存其地址的指针的作用域,则会发生内存泄露(memory leak)(因为之后再也没有机会去释放)。例如:
1
2
3
4
5
6
7
8
double* calc(int res_size, int max) {
double* p = new double[max]; // leaks memory
double* res = new double[res_size];
// use p to calculate results to be put in res
return res;
}
double* r = calc(100,1000);
每次调用calc()会“泄露”分配给p的double数组所占用的内存(如果调用者不释放r,同样会造成内存泄露)。
将内存释放回自由存储的运算符是delete,用于new返回的指针。有两种形式的delete:
delete p释放由new分配的单个对象的内存。delete[] p释放由new分配的数组的内存。
上面的例子修正后变为
1
2
3
4
5
6
7
8
9
10
11
12
double* calc(int res_size, int max) {
// the caller is responsible for the memory allocated for res
double* p = new double[max];
double* res = new double[res_size];
// use p to calculate results to be put in res
delete[] p; // we don't need that memory anymore: free it
return res;
}
double* r = calc(100,1000);
// use r
delete[] r; // we don't need that memory anymore: free it
这个例子说明了使用自由存储的一个主要原因:我们可以在一个函数中创建对象,并将其返回给调用者(来避免值拷贝)。
注:
- 对于自定义类型,
delete和delete[]将自动调用对象/元素的析构函数。 - 如果函数返回了由
new返回的指针,则调用者负责释放该内存,否则会发生内存泄露。 - C++11引入了智能指针
shared_ptr和unique_ptr,能够自动释放内存,定义在头文件<memory>中(见19.5.4节)。 - C++17引入了拷贝消除(copy elision)/返回值优化(return value optimization, RVO)特性:在特定情况下,即使函数返回值是值类型也不会发生值拷贝。
删除一个对象两次是一个严重的错误。 例如:
1
2
3
4
int* p = new int(5);
delete p; // fine: p points to an object created by new
// ... no use of p here ...
delete p; // error: p points to memory owned by the free-store manager
第二次delete p时,你已不再拥有p指向的内存,自由存储管理器可能已经将其回收并分配给其他对象,删除该对象(由程序的其他部分拥有)会引起程序错误。
删除空指针不会做任何事,因此删除空指针是无害的。
实际上,编译器可以知道我们什么时候不再需要一块内存,并在没有人为干预的情况下回收它。这叫做自动垃圾收集(garbage collection, GC)。然而自动垃圾收集并不是无代价的,也不是对所有应用都是理想的。在C++中,(通过new使用自由存储时)程序员必须自己处理“垃圾”。
注:
- Java、Python等语言内置了垃圾收集器,能够自动管理内存。
- 在C++中可以通过标准库容器、智能指针等工具来简化垃圾收集工作。
17.5 析构函数
现在可以用自由存储分配实现17.2节中vector的构造函数:
1
vector(int s) :sz(s), elem(new double[s]{0}) {}
构造函数分配了s个double,并全部初始化为0。
然而,这个vector会泄露内存,因为在构造函数中使用new分配的内存没有被释放。考虑:
1
2
3
4
void f(int n) {
vector v(n); // allocate n doubles
// ... use v ...
}
当函数f()返回时,v在自由存储中分配的内存没有被释放。我们可以为vector定义一个clean_up()并调用它:
1
2
3
4
5
void f2(int n) {
vector v(n); // allocate n doubles
// ... use v ...
v.clean_up(); // clean_up() deletes elem
}
这是可以的。但是,关于自由存储的一个最常见的问题是人们忘记delete。clean_up()也有同样的问题:人们可能忘记调用它。更好的做法是使编译器知道一个与构造函数具有相反功能的函数——析构函数(destructor)(如9.4.2节所述,使用构造函数来避免忘记调用初始化函数)。当一个类的对象被创建时构造函数将被隐式调用,同样,当一个对象离开作用域时析构函数将被隐式调用。构造函数确保对象被正确地创建和初始化,相反,析构函数确保对象被正确地销毁(释放了拥有的“资源”)。
类T的析构函数名为~T。例如:
1
2
3
4
// destructor: free memory
~vector() {
delete[] elem;
}
这样就可以写出:
1
2
3
4
5
6
void f3(int n) {
double* p = new double[n]; // allocate n doubles
vector v(n); // the vector allocates n doubles
// ... use p and v ...
delete[ ] p; // deallocate p's doubles
} // vector automatically cleans up after v
显然,delete[]相当繁琐并且容易出错。有了vector,就没有必要再使用new分配内存,并记得用delete释放。vector已经做了,而且做得更好。
注:对于new创建的单个对象,可以用智能指针来代替。
每个拥有资源(自由存储、文件、缓冲区、线程、锁等)的类都需要析构函数,在构造函数中获取资源,在析构函数中释放资源。 vector的构造函数/析构函数处理自由存储内存就是一个典型的例子。
17.5.1 生成的析构函数 析构顺序
如果一个类没有定义析构函数,则编译器会自动生成一个析构函数(相当于函数体为空)。
无论是自定义的还是生成的析构函数,在执行完函数体之后,编译器还会依次调用数据成员的析构函数和基类的析构函数。“析构函数应该被调用”这一保证就是这样实现的。
注:这一规则保证了析构顺序和构造顺序是相反的
- 构造顺序:基类 → 成员(按照声明顺序) → 自身
- 析构顺序:自身 → 成员(按照声明相反顺序) → 基类
例如:
1
2
3
4
5
6
7
8
9
10
struct Customer {
string name;
vector<string> addresses;
};
void some_fct() {
Customer fred;
// initialize fred
// use fred
}
当退出some_fct()后,fred将被销毁,其(自动生成的)析构函数将被调用,之后name和addresses的析构函数将被调用。
所有的规则可以总结为:当对象被销毁时(离开作用域、通过delete等),析构函数被调用。
17.5.2 析构函数和自由存储 虚析构函数
考虑一个自由存储和类层次结构结合使用的例子:
1
2
3
4
5
6
7
8
9
10
11
12
Shape* fct() {
Text tt(Point(200, 200), "Annemarie");
// ...
Shape* p = new Text(Point(100, 100), "Nicholas");
return p;
}
void f() {
Shape* q = fct();
// ...
delete q;
}
在函数fct()中,Text对象tt在离开fct()时被销毁,tt及其成员和基类Shape的析构函数将被调用。但是,对于从fct()返回的由new创建的Text对象,调用函数f()不知道q指向一个Text,那么delete q是如何调用Text的析构函数的?
在14.2.1节,我们略过了一个事实:Shape有一个虚析构函数,这正是问题的关键。当执行delete q时,delete会查看q的类型以确定是否需要调用析构函数,如果是则调用。因此delete q调用Shape的析构函数~Shape()。而~Shape()是虚函数,根据虚函数调用机制,实际会调用派生类的析构函数,在这里是~Text()(之后又自动调用了~Shape())。如果~Shape()不是虚函数,则~Text()将不会被调用,Text的string成员将不会被正确销毁。
经验法则:如果一个类作为基类,则需要虚析构函数。 否则当通过基类指针delete一个由new创建的派生类对象时,派生类的析构函数不会被调用,从而派生类对象不会被正确销毁。
17.6 访问元素
为了读写向量元素,我们提供简单的get()和set()成员函数:
1
2
double get(int n) { return elem[n]; } // access: read
void set(int n, double v) { elem[n] = v; } // access: write
这里在elem指针上使用[]运算符访问元素,如17.4.2节所述。
现在可以这样使用vector:
1
2
3
4
5
vector v(5);
for (int i = 0; i < v.size(); ++i) {
v.set(i, 1.1*i);
cout << "v[" << i << "]==" << v.get(i) << '\n';
}
与常用的下标符号相比,使用get()和set()的代码很丑陋。18.4节将为vector定义[]运算符。
当前版本的vector:简单向量v1
17.7 指向类对象的指针
“指针”的概念是通用的,可以指向内存中的任何对象。例如,可以使用vector的指针:
1
2
3
4
5
6
7
8
9
10
11
vector* f(int s) {
vector* p = new vector(s); // allocate a vector on free store
// fill *p
return p;
}
void ff() {
vector* q = f(4);
// use *q
delete q; // free vector on free store
}
请记住:位于构造函数之外的new会带来忘记delete它所创建的对象的机会。除非你有一个好的删除对象的策略(例如Vector_ref),否则尽量将new放在构造函数中、delete放在析构函数中。
给定一个对象名,可以使用.运算符访问成员:
1
2
3
vector v(4);
int x = v.size();
double d = v.get(3);
类似地,给定一个对象指针,可以使用->运算符访问成员:
1
2
3
vector* p = new vector(4);
int x = p->size();
double d = p->get(3);
p->m等价于(*p).m。
.和->通常称为成员访问运算符(member access operators)。
17.8 类型混用:void*和类型转换
偶尔,我们不得不放弃类型系统的保护(例如,与不知道C++类型的其他语言交互,与没有按照静态类型安全设计的旧代码交互)。在这种情况下,我们需要两样东西:
- 一种指针,指向不知道保存的是何种对象的内存
- 一种操作,告诉编译器这种指针指向的是哪种类型(未经证实)
类型void*的含义是“指向编译器不知道类型的内存的指针”。当我们想在代码之间传递不知道实际类型的地址时,就需要使用void*。例如回调函数的“地址”参数(16.3.1节),以及最底层的内存分配器(例如new运算符的实现)。
void用于表示“没有返回值”,不存在void类型的对象,因此void*指针不能被解引用。任何类型的指针都可以赋值给void*指针,反之则必须用static_cast进行显式类型转换(explicit type conversion),或者简称为类型转换(cast)。例如:
1
2
3
4
5
6
void* pv = new int; // OK: int* converts to void*
void* pv2 = pv; // copying is OK (copying is what void*s are for)
double* pd = pv; // error: cannot convert void* to double*
*pv = 7; // error: cannot dereference a void* (we don't know what type of object it points to)
pv[2] = 9; // error: cannot subscript a void*
int* pi = static_cast<int*>(pv); // OK: explicit conversion
C++提供的显式类型转换运算符:
static_cast:将一种类型转换为另一种相关的类型(例如int和double、void*和double*)。dynamic_cast:将基类指针/引用转换为派生类指针/引用(反之不需要转换)。如果转换失败,对于指针类型返回空指针,对于引用类型抛出std::bad_cast异常。const_cast:移除const属性。reinterpret_cast:在两个不相关的类型之间转换,例如int和double*。
只有在完全有必要时才使用static_cast,而const_cast和reinterpret_cast是两个更危险的转换。不要期望使用reinterpret_cast的代码可以移植。
17.9 指针和引用
引用可以看作是一种自动解引用的、不可变的指针,或者是对象的别名。指针和引用的区别:
- 指针可以不初始化(野指针),也可以不指向任何对象(空指针);而引用必须初始化,不存在“空引用”。
- 给指针赋值会改变指针本身的值,使其指向其他对象;而引用在初始化之后不能引用其他对象,给引用赋值改变的是被引用的对象的值。
- 指针通过
new或&获取,使用*或[]解引用;引用通过对象名获取,不需要解引用。
注:
- 指针的
const属性分为指针本身和被指向的对象:
| 类型 | 指针可变 | 指向的对象可变 |
|---|---|---|
T* | 是 | 是 |
const T* (等价于T const*) | 是 | 否 |
T* const | 否 | 是 |
const T* const | 否 | 否 |
- 引用本身是不可变的,因此在
const属性方面,T&相当于T* const,const T&相当于const T* const。
例如:
1
2
3
4
5
6
7
int x = 10;
int* p = &x; // you need & to get a pointer
*p = 7; // use * to assign to x through p
int x2 = *p; // read x through p
int* p2 = &x2; // get a pointer to another int
p2 = p; // p2 and p both point to x
p = &x2; // make p point to another object
对应的引用的例子如下:
1
2
3
4
5
6
7
8
int y = 10;
int& r = y; // the & is in the type, not in the initializer
r = 7; // assign to y through r (no * needed)
int y2 = r; // read y through r (no * needed)
int& r2 = y2; // get a reference to another int
r2 = r; // the value of y is assigned to y2
r = &y2; // error: you can't change the value of a reference
// (no assignment of an int* to an int&)
注意:
r2 = r相当于*p2 = *p,而不是p2 = p。r = &y2是类型错误,不存在给引用本身赋值使其引用另一个对象的操作。- 对引用变量取地址得到的是被引用对象的地址(例如
&r等于&y),无法获取引用变量本身的地址。C++标准甚至不要求编译器为引用变量分配内存,详见Reference declaration:
References are not objects; they do not necessarily occupy storage, although the compiler may allocate storage if it is necessary to implement the desired semantics (e.g. a non-static data member of reference type usually increases the size of the class by the amount necessary to store a memory address).
总之:指针和引用都是使用内存地址实现的,只是在用法上稍有不同。
17.9.1 指针参数和引用参数
当你希望将一个变量的值改为由函数计算的结果时,有三种选择:返回值、指针参数和引用参数。例如:
1
2
3
int incr_v(int x) { return x+1; } // compute a new value and return it
void incr_p(int* p) { ++*p; } // pass a pointer (dereference it and increment the result)
void incr_r(int& r) { ++r; } // pass a reference
每种方法各有利弊,需要根据具体的函数及其用法决定。使用指针参数会提醒程序员参数可能被修改,但需要判断空指针;相反,引用参数“看起来很无辜”(看不出参数会被修改),但可以确保引用了一个对象。
因此,答案是“取决于函数的性质”:
- 对于小的对象,使用传值。
- 对于“没有对象”(用空指针表示)是合法参数的函数,使用指针参数(记得判断空指针)。
- 否则,使用引用参数。
另见8.5.6节。
17.9.2 指针、引用和继承
如14.4节所述,派生类可以被用在需要其公有基类的地方(接口继承)。对于指针或引用,这一思想表达为:如果B是D的公有基类,则D*可以被隐式转换为B*,D&可以被隐式转换为B&。例如:
1
2
3
4
5
6
void rotate(Shape* s, int n); // rotate *s n degrees
Shape* p = new Circle(Point(100, 100), 40);
Circle c(Point(200, 200), 50);
rotate(p, 35);
rotate(&c, 45);
对于引用是类似的:
1
2
3
4
5
6
void rotate(Shape& s, int n); // rotate s n degrees
Shape& r = c;
rotate(r, 55);
rotate(*p, 65);
rotate(c, 75);
这对于大多数面向对象编程技术来说至关重要。
17.9.3 示例:链表
链表(linked list)最常用和有用的数据结构之一。链表由“链接”(link)(节点)组成,每个节点保存一些数据和指向下一个节点的指针。这是指针的典型用途之一。
每个节点具有前驱(predecessor)和后继(successor)节点指针的链表称为双向链表(doubly-linked list),例如:

其中norse_gods是指向头节点的指针。
节点只有后继节点指针的链表称为单向链表(singly-linked list),例如:

注:
- 链表的各个节点在内存中并不是顺序排列的,因此不能像数组一样通过下标访问,只能从头节点开始依次遍历。
- 《C程序设计语言》笔记 第6章 结构 6.6节也介绍了链表。
我们可以这样定义节点:
可以像这样构造上面图中北欧天神(Norse gods)的链表:
1
2
3
4
5
Link* norse_gods = new Link("Thor", nullptr, nullptr);
norse_gods = new Link("Odin", nullptr, norse_gods);
norse_gods->succ->prev = norse_gods;
norse_gods = new Link("Freia", nullptr, norse_gods);
norse_gods->succ->prev = norse_gods;
但是,这段代码比较晦涩难懂,因此定义一个插入操作:
1
2
3
4
5
6
7
8
// insert n before p (incomplete)
Link* insert(Link* p, Link* n) {
n->succ = p; // p comes after n
p->prev->succ = n; // n comes after what used to be p's predecessor
n->prev = p->prev; // p's predecessor becomes n's predecessor
p->prev = n; // n becomes p's predecessor
return n;
}
当p确实指向一个节点,并且该节点确实有一个前驱节点时,该函数可以正常工作。当我们思考指针和链表结构时,通常在纸上画一些方框和箭头的图示来验证代码的正确性。请不要太骄傲以至于不屑使用。
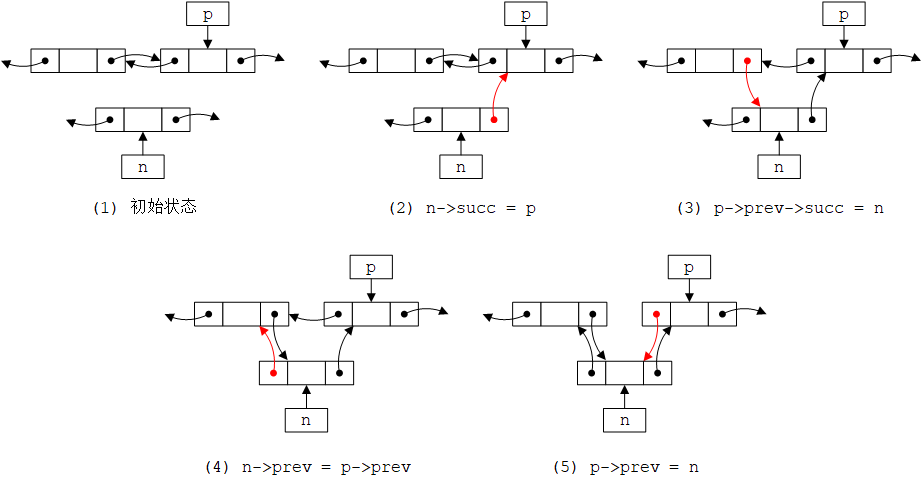
然而,这个版本的insert()是不完整的,因为没有处理n、p或p->prev为nullptr的情况。
注:一个简单的方法是先考虑理想情况,最后对所有出现在->前的指针检查空指针。
增加空指针测试后的正确版本如下:
1
2
3
4
5
6
7
8
9
10
// insert n before p; return n
Link* insert(Link* p, Link* n) {
if (n == nullptr) return p;
if (p == nullptr) return n;
n->succ = p; // p comes after n
if (p->prev) p->prev->succ = n; // n comes after what used to be p's predecessor
n->prev = p->prev; // p's predecessor becomes n's predecessor
p->prev = n; // n becomes p's predecessor
return n;
}
可以验证,当p是头节点(即p->prev == nullptr)时insert()也能正常工作,此时n将成为新的头节点。
这样,前面创建链表的代码就可以写成:
1
2
3
Link* norse_gods = new Link("Thor");
norse_gods = insert(norse_gods, new Link("Odin"));
norse_gods = insert(norse_gods, new Link("Freia"));
17.9.4 链表操作
下面是一组有用的链表操作:
- 构造函数
insert:在节点前插入add:在节点后插入erase:删除节点find:查找具有给定值的节点advance:获得第n个后继节点
这些操作的实现:链表操作
注:
- 如果在头节点前插入节点,或者删除的是头节点,则调用者负责更新头指针。
erase(p)不能delete从链表中删除的节点p,因为不能保证指针p是由new返回的。另一方面,由于p是通过参数传递的,调用者一定能够访问该指针。因此如果需要,调用者负责delete从链表中删除的节点。
注意,后缀形式的++返回自增之前的值,前缀形式的++返回自增之后的值。例如:
1
2
3
int a = 1;
int b = ++a; // a = 2, b = 2
int c = a++; // a = 3, c = 2
17.9.5 链表的应用
作为练习,我们创建两个链表:
1
2
3
4
5
6
7
8
9
Link* norse_gods = new Link("Thor");
norse_gods = insert(norse_gods, new Link("Odin"));
norse_gods = insert(norse_gods, new Link("Zeus"));
norse_gods = insert(norse_gods, new Link("Freia"));
Link* greek_gods = new Link("Hera");
greek_gods = insert(greek_gods, new Link("Athena"));
greek_gods = insert(greek_gods, new Link("Mars"));
greek_gods = insert(greek_gods, new Link("Poseidon"));
“不幸的是”,我们犯了两个错误:Zeus是一位希腊天神,而不是北欧天神;希腊的战争之神是Ares而不是Mars(Mars是他的拉丁/罗马名字)。我们可以修正:
1
2
Link* p = find(greek_gods, "Mars");
if (p) p->value = "Ares";
注意,我们谨慎地防止了find()返回nullptr。虽然在这个例子中不可能发生,但在实际的程序中一定要对返回指针的函数判断空指针!
注:这两个语句可以简写为if (Link* p = find(greek_gods, "Mars")) p->value = "Ares";
类似地,我们可以将Zeus移入正确的位置:
1
2
3
4
5
Link* p = find(norse_gods, "Zeus");
if (p) {
erase(p);
insert(greek_gods, p);
}
注意,这段代码存在两个微妙的bug:
- 如果删除的是
norse_gods指向的节点(即头节点),则必须更新norse_gods,否则它将指向错误的节点。 - 如果在
greek_gods指向的节点(头节点)前插入节点,则同样必须更新greek_gods。
1
2
3
4
5
if (Link* p = find(norse_gods, "Zeus")) {
if (p == norse_gods) norse_gods = p->succ;
erase(p);
greek_gods = insert(greek_gods, p);
}
注:这两个bug都是与头节点的更新相关的。为了解决这类问题,可以使用“虚拟头节点”,即创建一个固定的节点作为头节点,其他节点均作为虚拟头节点的后继。这样可以在链表操作中避免对头节点的特殊处理,简化代码逻辑。
最后打印出这两个链表:
1
2
{ Freia, Odin, Thor }
{ Zeus, Poseidon, Ares, Athena, Hera }
注:书中代码没有将new创建的节点占用的内存释放掉,应该使用一个循环依次遍历并delete各个节点:
1
2
3
4
5
6
7
void destroy(Link* p) {
while (p) {
Link* next = p->succ;
delete p;
p = next;
}
}
17.10 this指针
目前的链表操作函数都接受一个Link*作为第一个参数,并访问这个对象中的数据。我们通常将这种函数实现为成员函数:
我们将指针prev和succ声明为私有,并提供了const成员函数previous()和next()来访问它们;value仍然是公有的,因为它只是数据(提供一对getter & setter并且没有其他检查逻辑等价于直接将成员声明为公有)。
在成员函数中,this是指向当前对象(即调用成员函数的对象)的指针。在访问当前对象的成员时,无需使用this。例如,在Link::insert()中,this->prev等价于prev。只有当需要引用整个对象时才需要显式使用this(例如n->succ = this;、return *this;等)。
注意,this不能被赋值。
注:
- 在
X类的非const成员函数、构造函数和析构函数中,this的类型是X*;在const成员函数中,其类型是const X*。 - 在类模板中访问基类成员时,必须显式地使用
this->(使其成为待决表达式,因为基类模板特化可能没有该成员)。例如:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
template<class T>
struct B {
int var;
};
template<>
struct B<int> {};
template<class T>
struct D : B<T> {
D() {
// var = 1; // error: 'var' was not declared in this scope
this->var = 1; // OK
}
};
17.10.1 链表的应用
下面是链表的应用示例的新版本:
insert()等作为成员函数还是自由函数,在这种情况下差别并不大(成员函数版本只是将第一个参数移至函数之前,即insert(p, n)变为p->insert(n)),见9.7.5节。
注意,我们仍然没有一个链表类,这里的Link只是单个节点。因此调用者必须维护指向第一个元素的指针(即头指针)。标准库提供了一个list类,将在20.4节中介绍。