《C++程序设计原理与实践》笔记 第23章 文本处理
本章将介绍如何从文本中提取信息。在本章中,我们首先回顾标准库中最常用的文本处理功能:string、iostream和map。然后,我们将介绍正则表达式(regex),用来表达文本中的模式。
23.1 文本
本质上,我们无时无刻不在处理文本。除了图像和声音等二进制格式数据外,几乎所有其他信息都适合程序进行文本分析和转换。
23.2 字符串
字符串(string)是一个字符序列,并提供了一些有用的操作,完整列表在<string>。
注意,输入操作会按需扩展string,因此不可能发生溢出。
注:string的赋值(=)、拼接(+、+=)和比较(==、<等)操作均支持string和C风格字符串两种版本。
实际上,标准库字符串是一个模板basic_string,支持不同的字符类型(例如char、wchar_t、char8_t、char16_t、char32_t等)。而我们一直使用的string实际上就是basic_string<char>:
1
using string = basic_string<char>;
在文本处理中,几乎所有内容都能表示为字符串是很重要的。例如,数字12.333表示为6个字符。如果要读取这个数字,我们必须将这些字符转换为浮点数。这导致我们需要将值转换为字符串以及将字符串转换为值。在11.4节中,我们使用istringstream将字符串转换为浮点数。这种技术可以推广到任何具有<<和>>运算符的类型:
注:标准库头文件<string>提供了类似的函数:std::to_string()将数值转换为字符串,std::stoi()、std::stod()等将字符串转换为数值。
例如:
1
2
3
4
5
string s1 = to_string(12.333); // "12.333"
string s2 = to_string(1 + 5*6 - 99/7); // "17"
double d = from_string<double>("12.333"); // 12.333
int d = from_string<int>("Mary had a little lamb"); // oops!
与to_string()相比,from_string()更复杂一些,因为一个字符串可能表示很多种类型的值,这意味着我们必须显式指定需要的值类型(通过模板参数)。这也意味着字符串可能并不表示我们所期待的类型的值,因此用异常bad_from_string表示。
from_string()(或类似的函数)对于文本处理是必不可少的。例如,在16.4.3节中,In_box::get_int()用于在GUI代码中从文本输入框提取整数。
实际上,to_string()和from_string()大致为互逆操作。即(忽略空白符、舍入等细节)对于所有“适当的”类型T,有s == to_string(from_string<T>(s))以及t == from_string<T>(to_string(t))。在这里,“适当的”意味着T应该具有默认构造函数、>>运算符以及匹配的<<运算符。
注意,to_string()和from_string()的实现都使用了字符串流来完成所有困难的工作。这可用于定义任意两个(具有<<和>>操作的)类型之间的通用转换操作to():
!(interpreter >> std::ws).eof()将读取剩余的空白符,并检查是否到达输入结尾。结尾允许有空白符,但之后不应该再有任何字符。因此,to<int>("123")和to<int>("123 ")会成功,而to<int>("123.5")会失败。
注:to()是借助字符串完成“类型转换”的,并不是通常意义上的类型转换(像static_cast)。例如,to<int>(123.5)会出错而不是返回123;to<char>(9)会返回'9'而不是'\t'。
注:另见【C++】字符串编码问题。
23.3 I/O流
I/O流建立了字符串和其他类型之间的联系。第10和11章已经介绍了iostream库。标准I/O流的类层次结构:

与string类似,I/O流也支持不同的字符类型,常用的istream、ostream等实际上是char类型的模板特化:
1
2
3
4
5
6
7
8
9
10
11
using istream = basic_istream<char>;
using ostream = basic_ostream<char>;
using iostream = basic_iostream<char>;
using ifstream = basic_ifstream<char>;
using ofstream = basic_ofstream<char>;
using fstream = basic_fstream<char>;
using istringstream = basic_istringstream<char>;
using ostringstream = basic_ostringstream<char>;
using stringstream = basic_stringstream<char>;
23.4 映射
映射是很多文本处理任务的关键,原因在于:当我们处理文本时,收集的信息通常与文本字符串(例如名字、地址、邮政编码等)相关联。21.6节中单词计数的例子是一个很好的示例。
下面考虑电子邮件。电子邮件中的发件人、收件人、发送地址等信息都是以消息头中文本的形式呈现给邮件应用(例如Outlook)的。大多数分析邮件头的工具都使用正则表达式来提取信息,并使用映射来存储相关的邮件消息。
下面使用一个简化的邮件文件来解释一些从文本文件提取数据的技术。邮件头来自RFC 2822消息格式:
每封邮件以一行----(4个连字符)结束。我们将编写一个“玩具程序”,查找所有 “John Doe” 发送的邮件,并输出其主题(Subject)。如果能做到这一点,我们就能做很多有趣的事情。
基本思路是读取一个完整的邮件文件,保存到一个名为Mail_file的结构中。该结构使用vector<string>保存所有的行,并使用vector<Message>指明每个邮件消息的起止位置(行号):
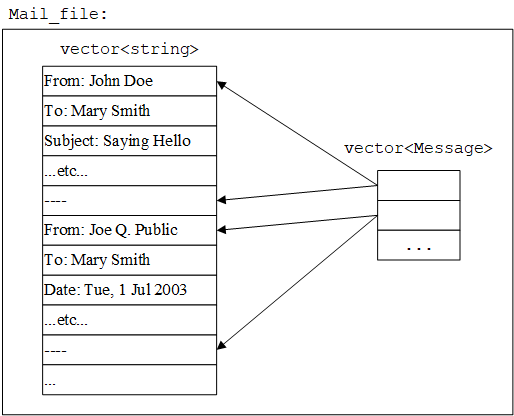
1
2
3
4
5
6
7
8
9
10
11
12
13
14
using Line_iter = vector<string>::const_iterator;
class Message {
Line_iter first;
Line_iter last;
// ...
};
struct Mail_file {
std::string name; // file name
std::vector<std::string> lines; // the lines in order
std::vector<Message> m; // Messages in order
// ...
};
下面开始编写我们的“玩具程序”,打印所有来自 “John Doe” 的邮件的主题。
注意,我们给数据结构添加了迭代器,使其能够很容易地遍历(“元素”是文本行)。如果需要,也可以使用标准库算法。
我们需要两个辅助函数find_from_addr()和find_subject()在邮件中查找和提取信息。
在主程序中,我们使用multimap来保存发件人到邮件消息的映射。首先遍历所有邮件消息,并使用insert()插入到映射。之后使用equal_range()来查询同一个发件人的所有邮件。
注:
sender.insert(make_pair(s, &m))等价于sender.emplace(s, &m)multimap没有[]运算符,因为可能存在多个相同的key,必须使用find()、count()、equal_range()等函数进行查询。find_from_addr()中的if语句直接在括号中声明了一个int变量,并判断该变量的值是否为真(非0),见4.4.1.1节。- C++20引入了
string::starts_with()函数,可以代替这里的is_prefix()。
我们首先将Message放在一个vector中,然后构造了一个multimap,而不是直接将Message放在映射中。原因很简单:
- 首先,构造一个通用的数据结构,可以用来做很多事
- 之后,在一个特定的应用中使用它
这样可以构建或多或少可重用的组件。例如,如果要增加“根据收件人查询邮件”的功能,仍然可以使用这个vector<Message>来构造另一个multimap(收件人到邮件消息的映射),而这里的multimap只能用于“根据发件人查询邮件”这一个特定的应用。
(所以为什么不直接遍历vector<Message>查询指定发件人的邮件,而要先构造一个multimap?因为这样可以多次查询不同发件人的邮件。)
注意,find_from_add()区分了有地址行但内容为空和无地址行两种情况。对于第一种情况,返回true并将s置为"";对于第二种情况,返回false。
23.5 一个问题
处理文本时,通常需要考虑字符串的上下文。考虑一个简单的例子:判断一个字符串是否包含美国州的缩写和邮政编码(“两个字母加五个数字”,例如TX77845):
1
2
3
4
5
6
7
for (string s; cin >> s; ) {
if (s.size() == 7
&& isalpha(s[0]) && isalpha(s[1])
&& isdigit(s[2]) && isdigit(s[3]) && isdigit(s[4])
&& isdigit(s[5]) && isdigit(s[6]))
cout << "found " << s << '\n';
}
这种(过于)简单的解决方案存在几个问题:
- 太冗长了
- 忽略了没有用空白符与上下文分开的邮政编码(例如
"TX77845"、TX77845-1234和ATX77845) - 忽略了字母和数字之间有空格的邮政编码(例如
TX 77845) - 接受了字母是小写的邮政编码(例如
tx77845) - 如果希望查找不同格式的邮政编码(例如
CB30FD),不得不重写全部代码
如果要处理更多情况,会遇到更多的问题:
- 如果希望处理多种格式,不得不加入
if语句或switch语句 - 如果希望处理大小写,必须显式地进行大小写转换,或者再加入一个
if语句 - 我们必须处理单个字符而不是字符串,这意味着失去了
iostream提供的很多优势
一定有更好的解决方法!最简单、最常用的解决方法是正则表达式(regular expression)。
C++11标准库引入了正则表达式。本章将介绍正则表达式的基本概念和一些基本使用方法。
23.6 正则表达式的思想
正则表达式的基本思想是:定义一个可以在文本中查找的模式(pattern)。
描述美国邮政编码模式(“两个字母加五个数字”,例如TX77845)的正则表达式如下:
1
\w\w\d\d\d\d\d
其中,元字符\w(word)匹配字母、数字或下划线,\d(digit)匹配数字。
可以使用{n}表示“重复n次”,因此上面的正则表达式可简化为
1
\w{2}\d{5}
对于9位数字的邮政编码(例如TX77845-5629),模式变为
1
\w{2}\d{5}-\d{4}
如果要同时匹配两种格式,可以使用
1
(\w{2}\d{5})|(\w{2}\d{5}-\d{4})
或
1
\w{2}\d{5}(-\d{4})?
其中,|表示“或”(即“匹配两个子表达式之一”);?表示“可选”(即“重复零次或一次”);()指定子表达式,本身并不匹配任何字符。如果要匹配这些特殊字符本身则需要转义,例如\(匹配左括号。
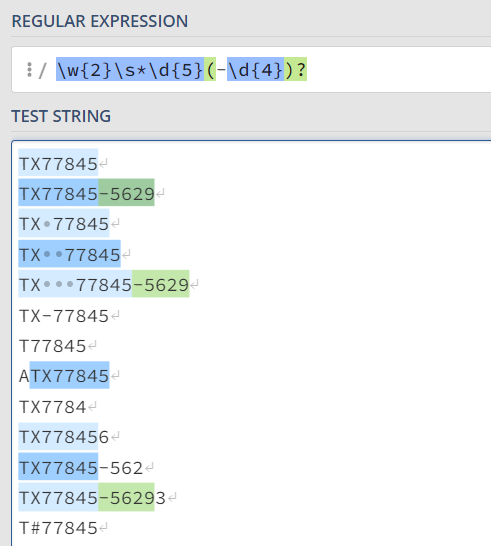
为了解决23.5节的问题,可以在字母和数字之间添加空白符:
1
\w{2}\s*\d{5}(-\d{4})?
其中,\s(space)匹配空白符(空格、制表符、换行符等),*表示“重复零次或多次”。
下面是使用正则表达式测试工具的测试结果,其中蓝色和绿色背景的是匹配的,白色背景的是不匹配的:
23.6.1 原始字符串
注意,正则表达式中的反斜杠(\)在C++字符串常量中必须再次转义。例如,上述模式使用字符串常量表示为
1
"\\w{2}\\s*\\d{5}(-\\d{4})?"
如果要匹配单个反斜杠,正则表达式为\\,C++字符串表示为"\\\\"。这需要写太多的反斜杠。
为了解决这一问题,C++11引入了原始字符串(raw string)字面值。原始字符串以R"(开始,以)"结束,中间的所有字符都不会被转义。上述模式使用原始字符串表示为
1
R"(\w{2}\s*\d{5}(-\d{4})?)"
该字符串包含22个字符(不算最后的空字符),和上面的普通字符串是完全等价的。
注:原始字符串与普通字符串只是在源代码中的写法不同,在内存中没有任何区别。
23.7 使用正则表达式搜索
下面使用上一节的正则表达式来查找文件中的邮政编码。
标准库正则表达式定义在头文件<regex>中。
首先,我们定义了模式pat:
1
regex pat(R"(\w{2}\s*\d{5}(-\d{4})?)"); // postal code pattern
类型regex表示正则表达式,使用字符串初始化。之后将它用于搜索文件的每一行:
1
2
3
smatch matches;
if (regex_search(line, matches, pat))
cout << lineno << ": " << matches[0] << '\n';
regex_search(line, matches, pat)在line中搜索与正则表达式pat匹配的内容。如果找到,则将结果保存在matches中,并返回true;否则返回false。
类型smatch表示匹配结果(s表示 “string” ),本质上是子匹配(sub-match)的向量。假设一个正则表达式有N个子表达式,匹配结果为m,则m.size() == N + 1,其中m[0]是完整匹配,m[i]是第i个子表达式的匹配(1 ≤ i ≤ N)。子表达式/子模式即圆括号中的模式。
例如,正则表达式\w{2}\s*\d{5}(-\d{4})?有1个子表达式-\d{4}。对于文本 “cvzcv TX77845-1234 sdsas” ,匹配结果m如下:
m.size() == 2m[0]: “TX77845-1234” (下图蓝框部分)m[1]: “-1234” (下图绿框部分)
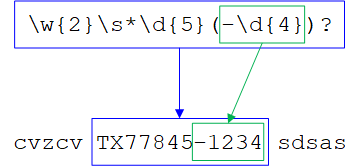
m[i]是一个sub_match对象。如果第i个子表达式未匹配到文本,则m[i].matched为false。
注:
(1)匹配结果实际上是类模板match_results<Iter>,常用的两个特化:
1
2
using cmatch = match_results<const char*>;
using smatch = match_results<string::const_iterator>;
如果待匹配文本(例如regex_search()的第一个参数)是C风格字符串(const char*)则使用cmatch,如果是string则使用smatch。
match_results的[]运算符返回sub_match对象的引用,str(i)返回第i个子匹配对应的字符串(i默认为0),m.str(i)等价于m[i].str()。
(2)类似地,子匹配也是类模板sub_match<Iter>,常用的两个特化:
1
2
using csub_match = sub_match<const char*>;
using ssub_match = sub_match<string::const_iterator>;
sub_match的str()函数返回子匹配对应的字符串,并且定义了类型转换运算符operator string,使其可以直接转换为字符串。
(3)标准库提供的正则表达式相关函数如下:
| 函数 | 功能 |
|---|---|
regex_match(s, m, p) | 如果字符串s整个匹配模式p则返回true,并将匹配结果保存到m |
regex_match(s, p) | 如果字符串s整个匹配模式p则返回true |
regex_search(s, m, p) | 在字符串s中搜索模式p,如果找到则返回true,并将匹配结果保存到m |
regex_search(s, p) | 在字符串s中搜索模式p,如果找到则返回true |
regex_replace(s, p, r) | 将字符串s中所有匹配模式p的部分替换为r |
(4)类模板regex_iterator<Iter>用于遍历文本中指定模式的所有匹配,常用的两个特化:
1
2
using cregex_iterator = regex_iterator<const char*>;
using sregex_iterator = regex_iterator<string::const_iterator>;
regex_iterator使用待匹配字符串的起止迭代器和正则表达式来初始化:regex_iterator(first, last, p),默认值regex_iterator()表示结束迭代器(类似于流迭代器),*运算符返回match_results<Iter>对象的引用。
23.8 正则表达式语法
下面更加系统、完善地介绍一下正则表达式。
正则表达式(regular expression)(简写为 “regexp” 或 “regex” )本质上是一种表达文本模式的小型语言。网络上有很多相关的教程和文档:
- Modified ECMAScript regular expression grammar - cppreference
- Basic POSIX regular expression grammar
- Regular expression - WikiPedia
- Python Regular Expression Syntax
- java.util.regex.Pattern
- 正则表达式30分钟入门教程
- Regular-Expressions.info
- 正则表达式测试工具
IDE的“查找和替换”功能通常都支持正则表达式。
23.8.1 字符和特殊字符
正则表达式指定了一个模式,用于在字符串中匹配字符。默认情况下,模式中的一个字符就匹配它本身。例如,模式abc匹配 “Is there an abc here?” 中的 “abc” 。
正则表达式中以下字符具有特殊含义:
| 特殊字符 | 含义 |
|---|---|
. | 匹配除换行符以外的任意字符(通配符) |
() | 子表达式(分组) |
[] | 字符集 |
{} | 重复 |
* | 重复零次或多次 |
+ | 重复一次或多次 |
? | 重复零次或一次 |
| | 匹配多个子模式之一 |
^ | ①匹配行的开始位置;②字符集取反 |
$ | 匹配行的结尾位置 |
例如,x.y匹配任意“以x开头、以y结尾的长度为3的字符串”,例如 “xxy”, “x3y” 和 “xay” ,但不匹配 “yxy”, “3xy” 和 “xy” 。
如果要匹配特殊字符本身,则必须使用反斜杠转义。例如,\+匹配一个加号。
23.8.2 字符类
| 字符类 | 含义 | 等价字符集 |
|---|---|---|
\d | 匹配数字 | [0-9] |
\w | 匹配字母、数字或下划线 | [a-zA-Z0-9_] |
\s | 匹配空白符 | [ \t\n\r\f\v] |
\b | 匹配单词的开始或结束位置 | - |
\D | 匹配不是数字的字符 | [^0-9] |
\W | 匹配不是字母、数字或下划线的字符 | [^a-zA-Z0-9_] |
\S | 匹配不是空白符的字符 | [^ \t\n\r\f\v] |
\B | 匹配不是单词的开始或结束位置 | - |
注意,大写形式是对应小写形式的反义。
23.8.3 重复
| 重复 | 含义 |
|---|---|
* | 重复零次或多次 |
+ | 重复一次或多次 |
? | 重复零次或一次 |
{n} | 重复n次 |
{n,} | 重复n次或更多次 |
{m,n} | 重复m到n次 |
例如:
Ax*匹配“一个A后面跟着零个或多个x”,例如 “A”, “Ax”, “Axx”, “Axxxxxxxxxxxxxxxxxxxxxxxxxxxxx” 。
Ax+匹配“一个A后面跟着一个或多个x”,例如 “Ax”, “Axx”, “Axxxxxxxxxxxxxxxxxxxxxxxxxxxxx” ,但不匹配 “A” 。
\d-?\d匹配“两个数字,中间有一个可选的连字符”,例如 “1-2”, “12” ,但不匹配 “1--2” 。
\w{2}-\d{4,5}匹配“两个字母(或数字或下划线),一个连字符,后面跟着4个或5个数字”,例如 “Ab-1234”, “XX-54321”, “22-54321” ,但不匹配 “Ab-123”, “?b-1234” 。
23.8.4 分组
圆括号指定子表达式/子模式/分组。例如(\d*:)?(\d+)。
分组的作用:
- 在
|、*等运算符中将子模式视为一个整体。 - 为匹配结果和替换功能提供分组编号。
例如,为了将所有 “yyyy/mm/dd” 格式的日期替换为 “yyyy-mm-dd” 格式,匹配模式为(\d{4})/(\d{2})/(\d{2}),替换模式为$1-$2-$3:
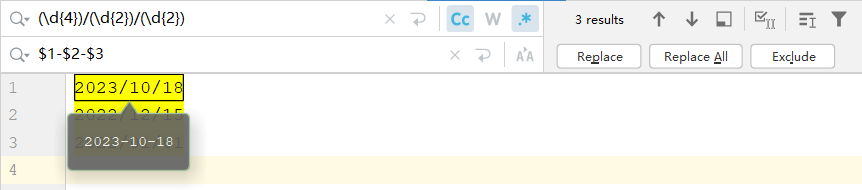
在C++中,替换模式(regex_replace()的第三个参数)使用$&表示整个匹配,$n表示第n个分组,详见ECMA-262语法 表22。
注:不同编程语言表示替换分组的语法可能不同。在Java中,使用$0而不是$&表示整个匹配;在Python中使用\n而不是$n表示分组。
23.8.5 选择
|表示匹配多个子模式之一。例如,Subject: (FW:|Re:)?(.*)匹配邮件主题行,包含可选的 “FW:” 或 “Re:” ,后面跟着零个或多个字符。例如:
1
2
3
Subject: FW: Hello, world!
Subject: Re:
Subject: Norwegian Blue
但不匹配
1
2
SUBJECT: Re: Parrots
Subject FW: No subject!
可以指定多个子模式,例如(bs|Bs|bS|BS)。但子模式不能为空,例如(|def)是错误的。
23.8.6 字符集和范围
字符集[]用于匹配集合中的任意一个字符,字符可以单独列出,可以使用字符类,也可以使用-指定范围。例如:
[Pp]匹配大写或小写字母p[aeiou]匹配元音字母[1-3]匹配1、2或3[a-z]匹配小写字母a~z[a-zA-Z]匹配大写或小写字母a~z[\w @]匹配单词字符(字母、数字或下划线)、空格或@
如果字符集的第一个字符是^则表示反义。例如:
[^aeiou]匹配非元音字母[^\d]匹配非数字(等价于\D)[ ^aeiou]匹配空格、^或元音字母
在最后一个正则表达式中,^不是第一个字符,因此它只是一个普通字符,而不表示反义。
下面是一些常用的标准字符集:
| 字符集 | 含义 | 等价字符集 |
|---|---|---|
[:alnum:] | 任意字母或数字 | [0-9A-Za-z] |
[:alpha:] | 任意字母 | [A-Za-z] |
[:blank:] | 任意空白符(换行符除外) | [ \t] |
[:cntrl:] | 任意控制字符 | [\x00-\x1F\x7F] |
[:digit:] | 任意数字 | [0-9]或\d |
[:graph:] | 任意图形字符 | [!-~] |
[:lower:] | 任意小写字母 | [a-z] |
[:print:] | 任意可打印字符 | [ -~] |
[:punct:] | 任意标点字符 | [!"#$%&'()*+,\-./:;<=>?@\[\\\]^_`{|}~] |
[:space:] | 任意空白符 | [ \t\n\r\f\v]或\s |
[:upper:] | 任意大写字母 | [A-Z] |
[:xdigit:] | 任意十六进制数字 | [0-9A-Fa-f] |
注:
- 这些名字中的中括号是名字的一部分,不是表示字符集的
[]。例如,[[:lower:]]等价于[a-z],[^[:lower:]]等价于[^a-z],[[:lower:][:upper:]]等价于[a-zA-Z]。 - 这些字符集对应标准库头文件<cctype>中的字符分类函数,详见Null-terminated byte strings中的表格。
- 不同编程语言对正则表达式字符集的支持也不同。在Java中,
\p{Lower}表示小写字母字符集;而Python不支持字符集。
23.8.7 正则表达式错误
如果将一个非法的正则表达式赋予regex,将会抛出regex_error异常。例如:
1
2
3
regex pat1("(|ghi)"); // missing alternative
regex pat2("[c-a]"); // not a range
regex pat3("[a"); // mismatched [ and ]
下面的程序对于体会正则表达式匹配很有帮助:
23.9 使用正则表达式匹配
正则表达式主要有两种用途:
- 在字符串中搜索与正则表达式匹配的子串:
regex_search() - 将整个字符串与正则表达式匹配:
regex_match()
23.7节的程序是搜索的例子,下面介绍一个匹配的例子。考虑从下面这样的表格中提取数据:
这张表格(Bjarne Stroustrup的母校在2007年的学生数)是从网页上提取的,是我们需要分析的典型数据:
- 包含数值字段(field)/列(column)
- 包含字符串字段,含义只有了解上下文的人知道(在这里是丹麦文)
- 字符串包含空格
- “字段”使用“分隔符”分隔开(在这里是制表符)
我们将展示正则表达式的以下用途:
- 验证表格布局是否正确(即每行的字段个数是否正确)
- 验证合计值是否正确(即最后一行/列是前面行/列之和)
表头行模式^[\w ]+(\t[\w ]+)*$匹配制表符分隔的若干个列名,每个列名是字母和空格组成的字符串(即[\w ]+),^和$分别匹配行的开头和结尾。
数据行模式^([\w ]+)(\t\d+)(\t\d+)(\t\d+)$匹配一个字符串字段([\w ]+)和三个数值字段(\d+),字段之间用制表符分隔。
为了验证表格中的数据,我们保存了男生(“drenge”)和女生(“piger”)两列的数量总和。对于每一行,检查最后一列(“ELEVER IALT”)是否等于前两列之和。
最后一行(“Alle klasser”)是其他行之和。在这之后,我们不再接受任何非空白符(使用来自to<>()的技术,见23.2节)。如果未找到最后一行则报错。
注:在这个程序中,数据行模式、字段分隔符以及用于识别最后一行的标签都是硬编码的,因此只能用于这一种结构的表格。