Python多继承的MRO和构造函数问题
Python支持多继承,而多继承比单继承要复杂得多。本文通过实例说明Python多继承中的方法解析顺序和构造函数两个问题。
Python版本:3.8
1.方法解析顺序
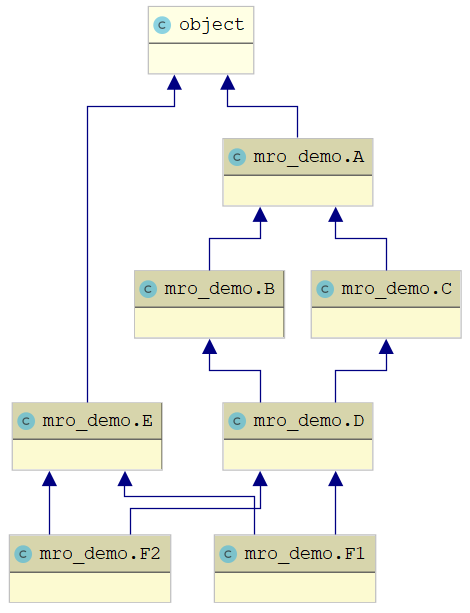
多继承存在菱形继承的问题,即B和C继承A,而D继承B和C,则D类应该以什么样的顺序继承B和C中的方法?实际上,Python中所有的多继承都是菱形继承,因为所有的类都是object的子类,但一般只有公共基类是自定义类时才叫菱形继承。
Python定义了一种方法解析顺序(MRO)规则,简单来说就是“深度优先搜索+从左到右”。每个类都有一个mro()方法,返回该类的方法解析顺序。以下面的代码为例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
class A:
def f(self):
print('A.f()')
def g(self):
print('A.g()')
class B(A):
def f(self):
print('B.f()')
class C(A):
def f(self):
print('C.f()')
def g(self):
print('C.g()')
class D(B, C):
pass
class E:
def f(self):
print('E.f()')
class F1(D, E):
pass
class F2(E, D):
pass
if __name__ == '__main__':
print(D.mro())
d = D()
d.f()
d.g()
print(F1.mro())
f1 = F1()
f1.f()
f1.g()
print(F2.mro())
f2 = F2()
f2.f()
f2.g()
这段代码的输出如下
1
2
3
4
5
6
7
8
9
[<class '__main__.D'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.A'>, <class 'object'>]
B.f()
C.g()
[<class '__main__.F1'>, <class '__main__.D'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.A'>, <class '__main__.E'>, <class 'object'>]
B.f()
C.g()
[<class '__main__.F2'>, <class '__main__.E'>, <class '__main__.D'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.A'>, <class 'object'>]
E.f()
C.g()
以F1的方法解析顺序为例,在查找一个方法时,先搜索D类及其基类(除object外)(深度优先搜索),再搜索E类及其基类(从左到右)。
F1和F2两个类的方法解析顺序的区别说明多继承的声明顺序也会影响MRO。
MRO的详细计算方法参见官方文档:
2.构造函数
在Python中,子类可以通过以下方式调用被覆盖的超类方法:
1
2
3
4
5
6
class C(B):
def __init__(self, arg):
B.__init__(self, arg)
def method(self, arg):
B.method(self, arg)
另外,也可以使用super()函数,下面的代码和上面的等价:
1
2
3
4
5
6
class C(B):
def __init__(self, arg):
super().__init__(arg)
def method(self, arg):
super().method(arg)
对于单继承,可以简单地将无参数的super()函数理解为超类对象,但对于多继承则不能这样理解。
实际上super()函数有两个参数的形式:super(cls, obj),其中obj必须是cls的子类或其子类的对象,返回值是在obj.mro()中cls的下一个类,相当于obj.mro[obj.mro.index(cls) + 1]。以上一节中的类层次结构为例,D.mro()是[D, B, C, A, object],因此super(B, d)将返回C类,其中d是一个D类的对象。
对于无参数的形式,编译器会将两个参数分别推断为“当前类”和“当前对象”,因此上面例子中的super()等价于super(C, self)。
官方文档对该函数的说明:super()
考虑下面的例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
class A:
def __init__(self, a):
self.a = a
print(f'A.__init__({a})')
class B(A):
def __init__(self, a, b):
super().__init__(a)
self.b = b
print(f'B.__init__({a}, {b})')
def __str__(self):
return f'B(a={self.a}, b={self.b})'
class C(A):
def __init__(self, a, c):
super().__init__(a)
self.c = c
print(f'C.__init__({a}, {c})')
class D(B, C):
def __init__(self, a, b, c):
B.__init__(self, a, b)
C.__init__(self, a, c)
def __str__(self):
return f'D(a={self.a}, b={self.b}, c={self.c})'
if __name__ == '__main__':
print(B.mro())
b = B(1, 2)
print(b)
print(D.mro())
d = D(1, 2, 3)
print(d)
期望程序会输出B(a=1, b=2) D(a=1, b=2, c=3),但实际运行结果如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
[<class '__main__.B'>, <class '__main__.A'>, <class 'object'>]
A.__init__(1)
B.__init__(1, 2)
B(a=1, b=2)
[<class '__main__.D'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.A'>, <class 'object'>]
Traceback (most recent call last):
File "init_demo.py", line 45, in <module>
d = D(1, 2, 3)
File "init_demo.py", line 32, in __init__
B.__init__(self, a, b)
File "init_demo.py", line 11, in __init__
super().__init__(a)
TypeError: __init__() missing 1 required positional argument: 'c'
可以看到对象b按照预期的方式被构造了;但构造对象d的过程中报错:执行到B类构造函数的第一行super().__init__(a)时报错缺少参数c,而参数c是来自C类的构造函数。为什么B类的构造函数会调用看似不相关的C类的构造函数?问题就出在这个无参数的super()函数。
由于无参数的super()函数等价于super(当前类,当前对象),在构造对象d的过程中,当代码执行到B类构造函数的第一行时,“当前类”是B,“当前对象”是d,因此这一行的super() == super(B, d) == C,所以super().__init__(a)调用的是C类的构造函数,而不是我们期望的A类的构造函数;而在构造对象b的过程中,这一行的super() == super(B, b) == A,因此调用的是A类的构造函数。
也就是说,在多继承的情况下,对象的实际类型不同,无参数的super()函数的返回值也不同!
一种解决方法是在多继承的情况下不使用super()函数,而是明确指定要调用方法的超类。将B类和C类构造函数的第一行都替换为A.__init__(self, a),上面的程序即可按预期的方式输出:
1
2
3
4
5
6
7
8
9
10
[<class '__main__.B'>, <class '__main__.A'>, <class 'object'>]
A.__init__(1)
B.__init__(1, 2)
B(a=1, b=2)
[<class '__main__.D'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.A'>, <class 'object'>]
A.__init__(1)
B.__init__(1, 2)
A.__init__(1)
C.__init__(1, 3)
D(a=1, b=2, c=3)
但这种方法存在一个问题:A类的构造函数被调用了两次,由B类和C类的构造函数各调用一次。如果在D类的构造函数中传递给B类和C类构造函数的参数a的值不同,则第二次调用A类的构造函数会覆盖第一次的结果。将D类构造函数的第二行改为C.__init__(self, a + 1, c),则输出结果变为
1
2
3
4
5
6
...
A.__init__(1)
B.__init__(1, 2)
A.__init__(2)
C.__init__(2, 3)
D(a=2, b=2, c=3)
另一种解决方法是仍然使用super()函数,但需要修改构造函数的参数。将B类和C类的构造函数除自身使用以外的参数改为*args, **kwargs,调用时也要使用关键字参数的形式:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
class A:
def __init__(self, a):
self.a = a
print(f'A.__init__({a})')
class B(A):
def __init__(self, b, *args, **kwargs):
super().__init__(*args, **kwargs)
self.b = b
print(f'B.__init__({b}, {args}, {kwargs})')
def __str__(self):
return f'B(a={self.a}, b={self.b})'
class C(A):
def __init__(self, c, *args, **kwargs):
super().__init__(*args, **kwargs)
self.c = c
print(f'C.__init__({c}, {args}, {kwargs})')
class D(B, C):
def __init__(self, a, b, c):
super().__init__(a=a, b=b, c=c)
def __str__(self):
return f'D(a={self.a}, b={self.b}, c={self.c})'
if __name__ == '__main__':
print(B.mro())
b = B(a=1, b=2)
print(b)
print(D.mro())
d = D(a=1, b=2, c=3)
print(d)
利用super()函数“返回MRO序列中下一个类”的特性,无论构造B类对象还是D类对象,其基类的构造函数将按照MRO相反的顺序被调用,对于B类就是A<-B,对于D类就是A<-C<-B<-D(其中箭头由调用者指向被调用者),上面程序的输出如下:
1
2
3
4
5
6
7
8
9
[<class '__main__.B'>, <class '__main__.A'>, <class 'object'>]
A.__init__(1)
B.__init__(2, (), {'a': 1})
B(a=1, b=2)
[<class '__main__.D'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.A'>, <class 'object'>]
A.__init__(1)
C.__init__(3, (), {'a': 1})
B.__init__(2, (), {'a': 1, 'c': 3})
D(a=1, b=2, c=3)
这种方法能够保证每个类的构造函数只被调用一次,代价是需要修改所有中间类的参数列表。
参考: