《Python基础教程》笔记 第9章 魔法方法、特性和迭代器
在Python中,有些名称很特殊,开头和结尾都是两个下划线(如__future__)。这样的拼写表示名称有特殊意义,因此绝对不要在自己的程序中创建这样的名称。这样的名称大部分都是魔法(特殊)方法的名称。如果你的对象实现了这些方法,它们将在特定情况下被Python调用,而几乎不需要直接调用。
本章讨论几个重要的魔法方法,其中最重要的是__init__()以及一些处理元素访问的方法。本章还将讨论两个相关的主题:特性(property)和迭代器(iterator)。在本章最后,将通过一个内容丰富的示例演示如何使用已有知识来解决非常棘手的问题。
9.1 如果你使用的不是Python 3
在Python 2.2中,对象的工作方式有了很大的变化。有些功能(例如特性和super()函数)不适用于旧式类。要让类是新式的,要么将赋值语句__metaclass__ = type放在模块开头,要么(直接或间接)地继承内置类object或其他新式类。
注意,在Python 3中没有旧式类。所有类都隐式地继承object——如果没有指定超类则直接继承它,否则间接继承它。
注:
- 关于旧式类,另见官方文档Old and New Classes和Unifying types and classes in Python 2.2。
- 在Python 3中,要使用新语法
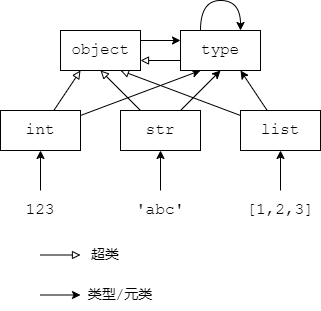
class C(metaclass=M)指定元类。元类(metaclass)即类的类(class of classes),详见官方文档Glossary - metaclass和Data model - Metaclasses。 - 所有类的(顶级)超类都是
object,所有内置类的元类都是type,如下图所示。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
>>> type(123)
<class 'int'>
>>> type('abc')
<class 'str'>
>>> type([1, 2, 3])
<class 'list'>
>>> type(int), type(str), type(list)
(<class 'type'>, <class 'type'>, <class 'type'>)
>>> int.__bases__, str.__bases__, list.__bases__
((<class 'object'>,), (<class 'object'>,), (<class 'object'>,))
>>> type.__bases__
(<class 'object'>,)
>>> type(object)
<class 'type'>
>>> type(type)
<class 'type'>
- 抽象基类(例如7.2.10节中的
Talker)的超类是ABC,元类是ABCMeta。
1
2
3
4
>>> Talker.__bases__
(<class 'abc.ABC'>,)
>>> type(Talker)
<class 'abc.ABCMeta'>
9.2 构造函数
要介绍的第一个魔法方法是构造函数(constructor),名为__init__。构造函数与普通方法的区别在于,构造函数在对象创建后将被自动调用。
1
2
3
class FooBar:
def __init__(self, value=42):
self.somevar = value
1
2
3
4
5
6
>>> f = FooBar()
>>> f.somevar
42
>>> f = FooBar('This is a constructor argument')
>>> f.somevar
'This is a constructor argument'
注意:Python有一个叫做__del__的魔法方法,也叫析构函数(destructor)。该方法在对象被销毁(垃圾收集)前被调用,但由于无法知道准确的调用时间,建议尽可能避免使用__del__。
9.2.1 覆盖普通方法和构造函数
第7章介绍了继承。对子类实例调用方法(或访问属性)时,如果找不到,将在其超类中查找。例如:
1
2
3
4
5
6
class A:
def hello(self):
print("Hello, I'm A.")
class B(A):
pass
1
2
3
4
5
6
>>> a = A()
>>> b = B()
>>> a.hello()
Hello, I'm A.
>>> b.hello()
Hello, I'm A.
要在子类中增加功能,一种基本方式是添加方法。然而,可能需要覆盖(override)超类的某些方法,以自定义继承而来的行为。例如:
1
2
3
class B(A):
def hello(self):
print("Hello, I'm B.")
1
2
3
>>> b = B()
>>> b.hello()
Hello, I'm B.
覆盖是继承机制的一个重要方面,对构造函数来说尤其重要。构造函数用于初始化新建对象的状态,而对于大多数子类来说,除超类的初始化代码外,还需要有自己的初始化代码。因此覆盖构造函数时很可能遇到一个特别的问题:覆盖构造函数时,需要调用超类的构造函数,否则可能无法正确地初始化对象。
考虑下面的Bird类:
1
2
3
4
5
6
7
8
9
class Bird:
def __init__(self):
self.hungry = True
def eat(self):
if self.hungry:
print('Aaaah ...')
self.hungry = False
else:
print('No, thanks!')
这个类定义了所有鸟都具备的一种基本能力:吃。
1
2
3
4
5
>>> b = Bird()
>>> b.eat()
Aaaah ...
>>> b.eat()
No, thanks!
下面考虑子类SongBird,增加了鸣叫功能。
1
2
3
4
5
class SongBird(Bird):
def __init__(self):
self.sound = 'Squawk!'
def sing(self):
print(self.sound)
1
2
3
>>> sb = SongBird()
>>> sb.sing()
Squawk!
但是如果调用继承的eat()方法,会发现一个问题:
1
2
3
4
5
>>> sb.eat()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<stdin>", line 5, in eat
AttributeError: 'SongBird' object has no attribute 'hungry'
异常清楚地指出了问题所在:SongBird没有hungry属性。因为SongBird覆盖了构造函数,但新的构造函数没有包含任何初始化hungry属性的代码。要消除这种错误,SongBird的构造函数必须调用其超类Bird的构造函数。为此,有两种方法:调用未绑定的超类构造函数,或者使用super()函数。
9.2.2 调用未绑定的超类构造函数
本节介绍的方法主要是历史遗留问题。在新版本的Python中,应使用super()函数。然而,很多已有代码使用的都是本节介绍的方法,这也是一个了解绑定和未绑定方法之间区别的好例子。
只需在SongBird类中添加一行代码Bird.__init__(self):
1
2
3
4
5
6
class SongBird(Bird):
def __init__(self):
Bird.__init__(self)
self.sound = 'Squawk!'
def sing(self):
print(self.sound)
对实例调用方法时,方法的self参数将自动绑定到实例,称为绑定方法(bound method)。然而,如果通过类调用方法(如Bird.__init__()),就没有绑定实例,因此可以随意提供self参数,这样的方法称为未绑定(unbound)方法。
假设x是C的实例,则x.f(args...)等价于C.f(x, args...)。详见官方文档Instance methods。
9.2.3 使用super函数
如果使用的不是旧版Python,就应该使用super()函数。这个函数只适用于新式类。调用这个函数时,将当前类和当前实例作为参数。对其返回的对象调用方法时,调用的将是超类(而不是当前类)的方法。在Python 3中调用super()函数时,可以不提供任何参数(通常也应该这样做),此时相当于超类对象的引用。
1
2
3
4
5
6
class SongBird(Bird):
def __init__(self):
super().__init__()
self.sound = 'Squawk!'
def sing(self):
print(self.sound)
1
2
3
4
5
6
7
>>> sb = SongBird()
>>> sb.sing()
Squawk!
>>> sb.eat()
Aaaah ...
>>> sb.eat()
No, thanks!
实际上,super()函数返回的是一个super对象,负责执行方法解析。当访问它的属性时,它将在所有的超类(以及超类的超类,等等)中查找直到找到指定的属性,或引发AttributeError。
注:
- 对于单继承的类,
super()等价于Java中的关键字super。另外,super()也适用于多继承的类,见官方文档super()。 - 另见关于超类构造函数的问题和Python多继承的MRO和构造函数问题。
9.3 元素访问
本节将介绍一组很有用的魔法方法,让你能够创建行为类似于序列或映射的对象。
注意:在Python中,经常使用协议(protocol)一词来描述管理某种形式的行为的规则,有点类似于第7章提到的接口。序列说明了应该实现哪些方法以及这些方法应该做什么。在Python中多态仅基于对象的行为:其他语言可能要求对象属于特定的类或实现特定的接口,而Python通常只要求对象遵循特定的协议(即鸭子类型)。
9.3.1 基本的序列和映射协议
序列和映射是元素(items)的集合。要实现其基本行为(协议),不可变对象需要实现2个魔法方法,而可变对象需要实现4个。
__len__(self):返回元素数量,对应len(x)。如果返回0(且没有实现__bool__()),对象在布尔上下文中将被视为假。__getitem__(self, key):返回与指定的键(或索引)关联的值,对应x[key]。对于序列来说,键应该是整数或切片(slice对象);对于映射来说,键可以是任何类型。__setitem__(self, key, value):存储与键关联的值,对应x[key] = value。只有可变对象需要实现。__delitem__(self, key):删除与键关联的值,对应del x[key]。只有可变对象需要实现。
注意:
- 对于序列,如果索引为负数,应从后往前数。换句话说,
x[-n]等价于x[len(x)-n]。 - 如果键的类型不合适(例如对序列使用字符串键),应引发
TypeError。 - 如果序列索引的类型正确,但超出了允许的范围,应引发
IndexError。 - 如果查询映射的键不存在,应引发
KeyError。
关于更多接口以及合适的抽象基类(Sequence),参考collections.abc模块文档。
下面尝试创建一个无穷序列。
这里实现的是一个等差数列,首项为start,公差为step。允许用户修改某些元素,这是通过将不符合规则的值保存在字典changed中实现的。如果元素未被修改,就使用公式self.start + key * self.step来计算。
下面是使用示例:
1
2
3
4
5
6
7
8
>>> s = ArithmeticSequence(1, 2)
>>> s[4]
9
>>> s[4] = 2
>>> s[4]
2
>>> s[5]
11
注意,希望禁止删除元素,因此没有实现__delitem__():
1
2
3
4
>>> del s[4]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: __delitem__
另外,这个类没有__len__()方法,因为它是无限长的。
如果索引类型非法,将引发TypeError;如果索引的类型正确但是超出了范围(即为负数),将引发IndexError。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
>>> s['four']
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "arithseq.py", line 36, in __getitem__
checkIndex(key)
File "arithseq.py", line 9, in checkIndex
if not isinstance(key, int): raise TypeError
TypeError
>>> s[-42]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "arithseq.py", line 36, in __getitem__
checkIndex(key)
File "arithseq.py", line 10, in checkIndex
if key < 0: raise IndexError
IndexError
9.3.2 继承list、dict和str
基本的序列/映射协议的4个方法能够让你走很远,但序列还有很多其他有用的魔法方法和普通方法。如果只想在一个操作中自定义行为,就没有理由重新实现其他所有方法。这就是程序员的懒惰(也是常识)。
那么应该怎么做呢?咒语就是继承。标准库collections模块提供了抽象和具体基类,但也可以继承内置类型。
下面看一个简单的示例——带访问计数器的列表。
CounterList类在很大程度上依赖于其子类超类(list)的行为,没有覆盖的方法都可以直接使用。
下面是使用示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
>>> cl = CounterList(range(10))
>>> cl
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> cl.reverse()
>>> cl
[9, 8, 7, 6, 5, 4, 3, 2, 1, 0]
>>> del cl[3:6]
>>> cl
[9, 8, 7, 3, 2, 1, 0]
>>> cl.counter
0
>>> cl[4] + cl[2]
9
>>> cl.counter
2
9.4 更多魔法方法
特殊(魔法)名称的用途很多,前面展示的只是冰山一角。大部分魔法方法是为非常高级的用途准备的,例如模拟数字、调用、比较等。详见官方文档Special method names。
注:其他常用的魔法方法
- 转换为字符串:
__str__()和__repr__() - 实现运算符:
__eq__()、__add__()等 - 函数调用:
__call__()
9.5 特性
第7章提到了访问器方法。访问器是用于获取或设置属性的简单方法。例如,考虑下面的Rectangle类:
1
2
3
4
5
6
7
8
class Rectangle:
def __init__(self):
self.width = 0
self.height = 0
def set_size(self, size):
self.width, self.height = size
def get_size(self):
return self.width, self.height
1
2
3
4
5
6
7
8
>>> r = Rectangle()
>>> r.width = 10
>>> r.height = 5
>>> r.get_size()
(10, 5)
>>> r.set_size((150, 100))
>>> r.width
150
get_size()和set_size()方法是假想属性size的访问器,这个属性是由width和height构成的元组。这些代码没有错,但存在缺陷。使用这个类的程序员应该无需关心它是如何实现的(封装)。客户端代码应该能够以同样的方式对待所有属性(即直接访问r.size)。
Python能够替你隐藏访问器方法,让所有的属性看起来都一样。通过访问器定义的属性通常称为特性(property)。
9.5.1 property函数
property()函数使用起来很简单。对于前面的Rectangle类,只需再添加一行代码。
1
2
3
4
5
6
7
8
9
class Rectangle:
def __init__(self):
self.width = 0
self.height = 0
def set_size(self, size):
self.width, self.height = size
def get_size(self):
return self.width, self.height
size = property(get_size, set_size)
在这个新版的Rectangle中,通过调用property()函数并将访问器方法作为参数,创建了一个名为size的特性。这样就能以同样的方式对待width、height和size,而无需关心是如何实现的。
1
2
3
4
5
6
7
8
>>> r = Rectangle()
>>> r.width = 10
>>> r.height = 5
>>> r.size
(10, 5)
>>> r.size = 150, 100
>>> r.width
150
实际上,property()函数有四个参数fget、fset、fdel和doc,分别是getter方法、setter方法、删除方法和文档字符串。这四个参数都是可选的。例如,如果仅指定一个参数,则特性是只读的。
详见property()函数。
对于新式类,应使用property而不是访问器。
工作原理
其实property并不是真正的函数,而是一个类。其实例包含一些魔法方法来完成所有工作:__get__、__set__和__delete__。这三个方法定义了所谓的描述符协议(descriptor protocol),实现了其中任何一个方法的对象就是描述符(descriptor)。例如,读取属性(具体来说,是在实例中访问类中定义的属性)时,如果它绑定到一个实现了__get__()的对象,将不会返回这个对象,而是调用__get__()方法并将其结果返回。实际上,这是特性、绑定方法、静态方法和类方法以及super的底层机制。详见Descriptor Guide。
注:特性也可以使用装饰器语法:
装饰器(decorator)即接受一个函数作为参数、返回另一个函数的函数。
1
2
3
@decorator
def f(arg):
...
等价于
1
2
3
def f(arg):
...
f = decorator(f)
如果指定了多个装饰器,应用顺序与列出顺序相反。详见官方文档Glossary - decorator。例如:
1
2
3
4
5
6
7
8
def add_one(f):
def _f(x):
return f(x) + 1
return _f
@add_one
def f(x):
return x * 2
1
2
>>> f(8)
17
上面的Rectangle类定义等价于:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
class Rectangle:
def __init__(self):
self.width = 0
self.height = 0
def get_size(self):
return self.width, self.height
size = property(get_size) # (1)
def set_size(self, s):
self.width, self.height = s
size = size.setter(set_size) # (2)
其中,(1)处的特性size仅包含访问器get_size(),而(2)处的特性size在(1)的基础上增加了访问器set_size()。setter()是property类的方法,等价于property(self.fget, fset, self.fdel, self.doc)。
property的实现原理: https://docs.python.org/3/howto/descriptor.html#properties 。
9.5.2 静态方法和类方法
静态方法和类方法是分别使用staticmethod和classmethod包装的方法。静态方法(static method)的定义中没有self参数,可以直接通过类来调用。类方法(class method)的定义中包含类似于self的参数,通常命名为cls。类方法也可以直接通过类调用,但cls参数将自动绑定到类。
注:静态方法和类方法可以对类调用(例如C.f()),也可以对实例调用(例如c.f(),等价于type(c).f())。
例如:
1
2
3
4
5
6
7
8
9
class MyClass:
@staticmethod
def smeth():
print('This is a static method')
@classmethod
def cmeth(cls):
print('This is a class method of', cls)
1
2
3
4
>>> MyClass.smeth()
This is a static method
>>> MyClass.cmeth()
This is a class method of <class '__main__.MyClass'>
9.5.3 __getattr__、__setattr__等方法
可以拦截对象的所有属性访问。其用途之一是在旧式类中实现特性。下面的四个魔法方法提供了需要的所有功能(在旧式类中只需要后三个)。
__getattribute__(self, name):访问属性name时自动调用。__getattr__(self, name):访问属性name而对象没有该属性时自动调用。__setattr__(self, name, value):给属性name赋值时自动调用。__delattr__(self, name):删除属性name时自动调用。
下面还是Rectangle的例子,但这次使用的是魔法方法:
注意,__setattr__()使用魔法属性__dict__(包含所有实例属性的字典)而不是常规属性赋值,是为了避免导致无限循环。类似地,在__getattribute__()中访问当前实例的属性时,唯一安全的方式是使用超类的__getattribute__()方法。
9.6 迭代器
9.6.1 迭代器协议
迭代意味着重复多次,就像循环那样。
实现了__iter__()方法的对象是可迭代的(iterable)。__iter__()方法返回一个迭代器(iterator),迭代器是包含__next__()方法的对象。当调用__next__()方法时,迭代器应返回其下一个值;如果没有可返回的值(到达结尾),应引发StopIteration异常。
内置函数iter(x)等价于x.__iter__(),next(it)等价于it.__next__()。
为什么不直接使用列表呢?因为迭代器可以逐个地获取值,而列表可能占用太多的内存。另外,使用迭代器更通用、更简单、更优雅。
下面看一个不能使用列表的例子,斐波那契数列的迭代器:
注意,迭代器通常也实现__iter__()方法,返回迭代器本身,从而迭代器也是可迭代的(可用于for循环)。
可以在for循环中使用Fibs对象。例如,找出第一个大于1000的斐波那契数。
1
2
3
4
5
fibs = Fibs()
for f in fibs:
if f > 1000:
print(f)
break
注:Python的for语句底层使用了迭代器:
1
2
for x in s:
f(x)
等价于
1
2
3
4
5
6
7
it = iter(s)
while True:
try:
x = next(it)
f(x)
except StopIteration:
break
9.6.2 从迭代器创建序列
除了对迭代器和可迭代对象进行迭代(通常这样做)之外,还可以将其转换为序列。在大部分可以使用序列的地方(索引和切片等操作除外),也可以使用迭代器或可迭代对象。下面的例子使用list构造函数将迭代器转换为列表。
1
2
3
>>> ti = TestIterator()
>>> list(ti)
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
注:这是因为list构造函数要求参数是可迭代对象。
9.7 生成器
生成器是一种使用普通函数语法定义的迭代器。下面先看看如何创建和使用生成器,然后看看其背后的原理。
9.7.1 创建生成器
下面创建一个将嵌套列表展开的函数。
1
2
3
4
def flatten(nested):
for sublist in nested:
for element in sublist:
yield element
包含yield语句的函数叫做生成器(generator)。生成器的行为与普通函数截然不同。生成器不是使用return返回一个值,而是可以产生多个值,每次一个。每次使用yield产生一个值后,函数将冻结,即在此停止执行,等待被重新唤醒。被重新唤醒后,函数将从停止的地方开始继续执行。
可以对生成器进行迭代来使用所有的值。
1
2
3
4
5
6
7
8
9
10
11
>>> nested = [[1, 2], [3, 4], [5]]
>>> for num in flatten(nested):
... print(num)
...
1
2
3
4
5
>>> list(flatten(nested))
[1, 2, 3, 4, 5]
生成器表达式
Python 2.4引入了生成器表达式(generator expression)。其工作原理与列表推导式类似,但不是创建一个列表(即不立即执行循环),而是返回一个生成器,能够逐步执行计算。
1
2
3
>>> g = ((i + 2) ** 2 for i in range(2, 27))
>>> next(g)
16
和列表推导式的区别是两边是圆括号。
可以直接在一对已有的圆括号内(例如函数调用中)使用生成器表达式,无需再添加一对圆括号。换句话说,可以编写像这样的漂亮代码:
1
sum(i ** 2 for i in range(10))
9.7.2 递归生成器
上一节设计的生成器只能处理两层的嵌套列表。如果要处理任意层嵌套的列表,就该求助于递归了。
1
2
3
4
5
6
def flatten(nested):
try:
for sublist in nested:
yield from flatten(sublist)
except TypeError:
yield nested
注:yield from直接产生一个可迭代对象的所有值,即yield from s等价于for x in s: yield x。
- 基本情况:
nested是单个元素(例如一个数字),这种情况下,for循环将引发TypeError(因为数字不是可迭代的),从而生成器直接产生该元素。 - 递归情况:
nested是一个列表(或任何可迭代对象),遍历所有子列表并对其调用flatten()。
1
2
>>> list(flatten([[[1], 2], 3, 4, [5, [6, 7]], 8]))
[1, 2, 3, 4, 5, 6, 7, 8]
然而,这个函数存在一个问题:如果nested是字符串,它是一个序列(见2.2.1节),不会引发TypeError,但并不想对其进行迭代。
注意:flatten()函数不应该对字符串进行迭代,主要原因有两个。首先,希望将字符串视为原子值,而不是应该展开的序列。其次,这会导致无穷递归,因为字符串的第一个元素是另一个长度为1的字符串,而长度为1的字符串的第一个元素就是它本身!
要处理这一问题,必须在生成器开头进行检查。要检查对象是否类似于字符串(string-like),最简单、最快捷的方式是尝试将对象与一个字符串拼接,看是否会引发TypeError。
注意这里没有执行类型检查:没有检查nested是否是字符串,而只是检查其行为是否类似于字符串,即能否与字符串拼接。
9.7.3 生成器概述
生成器是包含关键字yield的函数。当它被调用时,不会执行函数体中的代码,而是返回一个迭代器。每次请求一个值,都将执行生成器的代码,直到遇到yield或return。yield意味着产生一个值,而return意味着停止执行。
换句话说,生成器由两部分组成:生成器函数和生成器迭代器。生成器函数是def语句定义的,生成器迭代器是这个函数返回的。用不太准确的话说,这两个实体通常被视为一个,统称为生成器。
1
2
3
4
5
6
7
>>> def simple_generator():
... yield 1
...
>>> simple_generator
<function simple_generator at 0x0000021F44E47600>
>>> simple_generator()
<generator object simple_generator at 0x0000021F44DF4A90>
9.7.4 生成器方法
生成器具有以下方法:
__next__():开始或继续执行生成器函数,将当前yield表达式求值为None,并返回下一个yield产生的值或引发StopIteration。send(value):开始或继续执行生成器函数,并向其“发送”一个值,将value作为当前yield表达式的值,并返回下一个yield产生的值或引发StopIteration。调用send(None)等价于__next__()。throw(exc):在暂停点引发指定的异常,并返回下一个yield产生的值或引发StopIteration。如果生成器函数没有捕获传入的异常,则传播给调用者。close():在暂停点引发GeneratorExit,用于停止生成器。如果要在生成器中执行清理代码,可以将yield放在try/finally语句中。
注:实际上,只需要__next__()方法和yield语句就足以实现生成器的功能(见最初版本的生成器PEP 255)。另外三个方法是为了实现协程在PEP 342中添加的。详见《基于协程和asyncio的并发编程》。
yield语句两边加上圆括号就是yield表达式:(yield <expr>)。
具体来说,生成器函数的执行过程如下:
- 开始执行,直到遇到
yield,将其参数返回给调用者,挂起。 - 求值上次挂起的
yield表达式,继续执行,直到遇到yield并产生一个值,挂起。 - ……
- 求值上次挂起的
yield表达式,继续执行,直到遇到函数结尾或return,引发StopIteration,结束。
yield表达式的值取决于触发继续执行的方法:
- 如果是
__next__()(例如通过for或next()),则结果为None。 - 如果是
send(value),则结果为value。
注意:这里说的是yield表达式本身的值,而不是通过yield产生的值。
详见官方文档Yield expressions和Generator-iterator methods。
下面的例子演示了生成器各个方法的功能:
1
2
3
4
5
6
def repeater(value):
while True:
try:
print((yield value))
except Exception as e:
print(e)
1
2
3
4
5
6
7
8
9
10
11
12
13
>>> g = repeater(42)
>>> next(g)
42
>>> next(g)
None
42
>>> g.send('Hello')
Hello
42
>>> g.throw(TypeError('spam'))
spam
42
>>> g.close()
执行过程如下:
- 第一次调用
next(g):生成器开始执行,进入第一次循环,遇到yield,产生值42,挂起。 - 第二次调用
next(g):求值上次挂起的yield表达式,结果为None(因为是通过next()继续执行)并打印;继续执行,进入第二次循环,遇到yield,产生值42,挂起。 - 调用
g.send('Hello'):求值上次挂起的yield表达式,结果为'Hello'(因为是通过send()继续执行)并打印;继续执行,进入第三次循环,遇到yield,产生值42,挂起。 - 调用
g.throw(TypeError('spam')):求值上次挂起的yield表达式,引发指定的异常,进入except子句打印异常信息;继续执行,进入第四次循环,遇到yield,产生值42,挂起。 - 调用
g.close():停止生成器。
9.7.5 模拟生成器
旧版本的Python无法使用生成器。但可以使用普通函数模拟生成器:使用列表保存结果,使用append()代替yield(这种方法无法模拟无穷生成器)。
下面使用普通函数重写了生成器flatten():
9.8 八皇后问题
本节将介绍如何使用生成器来解决一个经典的编程问题。
9.8.1 生成器和回溯
生成器非常适合逐步得到结果的复杂递归算法。如果没有生成器,通常必须通过额外的参数来传递部分结果。而使用生成器,递归调用只需用yield生成自己部分的结果。
然而,在有些应用中,不能马上得到答案,必须尝试多次,并且在每个递归层级中都如此。
回溯(backtracking)策略对于解决需要尝试所有组合直到找到解的问题很有帮助。其伪代码如下:
1
2
3
4
5
for each possibility at level 1:
for each possibility at level 2:
...
for each possibility at level n:
is it viable?
要直接使用for循环来实现,必须知道有多少层。如果无法知道,则使用递归。
9.8.2 问题
这是一个深受喜爱的计算机科学谜题:将8个皇后放在一个棋盘上,要求任何两个皇后都不能吃掉对方(即不能位于同一行、同一列或同一条对角线上)。
这是一个典型的回溯问题:在第一行尝试第一个皇后的位置,然后尝试第二个,以此类推。如果发现无法放置下一个皇后,就回溯到上一步,并尝试另一个位置。最后,要么尝试完所有的可能性,要么找到一个解。
在前面描述的问题中,只有8个皇后,但这里假设可以有任意数量的皇后(这更像现实世界的回溯问题)。
9.8.3 状态表示
注:首先可以确定,每个皇后必须放置在不同行,因此可以用每行放置皇后的列来表示一个解。
可以使用元组来表示可能的解,其中每个元素表示相应行中皇后所在的位置(列)。在特定的递归层级(特定的行),只知道“上面”各行皇后的位置,因此状态元组的长度小于皇后的数量。
9.8.4 检测冲突
要找出没有冲突(即没有皇后能吃掉其他皇后)的位置组合,首先必须定义冲突是什么。
函数conflict()对于已知皇后的位置(用状态元组表示),确定下一个皇后的位置是否会导致冲突。
1
2
3
4
5
6
def conflict(state, nextX):
nextY = len(state)
for i in range(nextY):
if abs(state[i] - nextX) in (0, nextY - i):
return True
return False
nextX是下一个皇后的x坐标(列),nextY是y坐标(行)。该函数对前面的每个皇后做检查:如果下一个皇后与当前皇后的x坐标相同或在同一条对角线上,则发生冲突,返回True;否则返回False。
9.8.5 基本情况
基本情况:最后一个皇后。
1
2
3
4
5
6
def queens(num, state):
if len(state) == num - 1:
for pos in range(num):
if not conflict(state, pos):
yield (pos,)
...
即:“如果只剩最后一个皇后没有放置,则遍历所有可能的位置,并返回那些不会引发冲突的位置。”
例如,假设有4个皇后,前三个皇后的位置分别为1、3和0,则第4个皇后只有一个位置符合条件,如下图所示。

1
2
>>> list(queens(4, (1, 3, 0)))
[(2,)]
9.8.6 递归情况
对于递归调用,向它提供的是上面皇后的位置元组。对于当前皇后的每个合法位置,递归调用返回的是下面皇后的位置元组。为了让这个过程进行下去,只需将当前皇后的位置插入结果的开头,如下所示:
1
2
3
4
5
else:
for pos in range(num):
if not conflict(state, pos):
for result in queens(num, state + (pos,)):
yield (pos,) + result
这里的for pos和if not conflict部分与前面相同,因此可以简化一下代码。另外,添加参数默认值。
1
2
3
4
5
6
7
8
def queens(num=8, state=()):
for pos in range(num):
if not conflict(state, pos):
if len(state) == num - 1:
yield (pos,)
else:
for result in queens(num, state + (pos,)):
yield (pos,) + result
生成器queens()能给出所有的解。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
>>> list(queens(3))
[]
>>> list(queens(4))
[(1, 3, 0, 2), (2, 0, 3, 1)]
>>> for solution in queens(8):
... print(solution)
...
(0, 4, 7, 5, 2, 6, 1, 3)
(0, 5, 7, 2, 6, 3, 1, 4)
...
(7, 2, 0, 5, 1, 4, 6, 3)
(7, 3, 0, 2, 5, 1, 6, 4)
>>> len(list(queens(8)))
92
9.8.7 包装
在结束之前,可以让输出更容易理解一些。
1
2
3
4
5
def prettyprint(solution):
def line(pos, length=len(solution)):
return '. ' * pos + 'X ' + '. ' * (length - pos - 1)
for pos in solution:
print(line(pos))
下面随机选择一个解,并将其打印出来,以确定它是正确的。
1
2
3
4
5
6
7
8
9
10
>>> import random
>>> prettyprint(random.choice(list(queens(8))))
. . . . . X . .
. X . . . . . .
. . . . . . X .
X . . . . . . .
. . . X . . . .
. . . . . . . X
. . . . X . . .
. . X . . . . .
