《Python基础教程》笔记 第14章 网络编程
本章将通过示例展示如何使用Python来编写使用网络的程序。Python提供了强大的网络编程支持,有很多库实现了常见的网络协议以及基于这些协议的抽象层,让你能够专注于程序的逻辑,而无需关心通过线路来传输比特的问题。
本章首先概述Python标准库中的一些网络模块。然后讨论socketserver和相关的类,并简要介绍同时处理多个连接的各种方法。最后介绍Twisted,这是一个使用Python编写网络程序的框架,功能丰富而成熟。
14.1 几个网络模块
标准库中有很多网络模块,其他地方还有更多。这里精挑细选了几个模块进行介绍。
14.1.1 socket模块
网络编程中的一个基本组件是套接字(socket)。套接字基本上是一个“信息通道”,两端各有一个程序。这些程序可能位于(通过网络相连的)不同的计算机上,通过套接字向对方发送信息。
套接字有两种:服务器套接字和客户端套接字。创建服务器套接字后,让它等待连接。这样,它将在某个网络地址(由IP地址和端口号组成)处监听,直到客户端套接字建立连接。然后客户端和服务器就能通信了。客户端套接字处理起来通常更容易些,只需连接,完成任务,断开连接。
套接字是socket模块中socket类的实例。创建普通套接字时,不用提供任何参数。
服务器套接字先调用bind()方法,再调用listen()方法来监听给定的地址。然后,客户端套接字可以使用与bind()相同的地址调用connect()方法连接到服务器(在服务器端,可以使用函数socket.gethostname()获取当前及其的主机名)。这里的地址是一个格式为(host, port)的元组,其中host是主机名(例如www.example.com或IP地址),port是端口号(一个整数)。listen()方法接受一个可选参数——允许排队等待的最大连接数。
服务器套接字开始监听后,就可以使用accept()方法接受客户端连接了。这个方法将阻塞(等待)直到有客户端连接,然后返回一个格式为(client, address)的元组,其中client是客户端套接字,address是客户端地址。服务器处理客户端连接,然后再次调用accept()等待新连接。这通常是在一个无限循环中完成的。
注意:这里讨论的服务器编程形式称为阻塞(blocking)或同步(synchronous)网络编程。在14.3节,将看到非阻塞或异步网络编程示例,以及如何使用线程来同时处理多个客户端。
为了传输数据,套接字提供了两个方法:send()和recv()(表示 “receive” )。要发送数据,可以调用send()并提供一个bytes参数;要接收数据,可以调用recv()并指定最多接收多少个字节的数据。如果不确定,1024是个不错的选择。
注:客户端和服务器通过套接字通信的流程如下图所示。
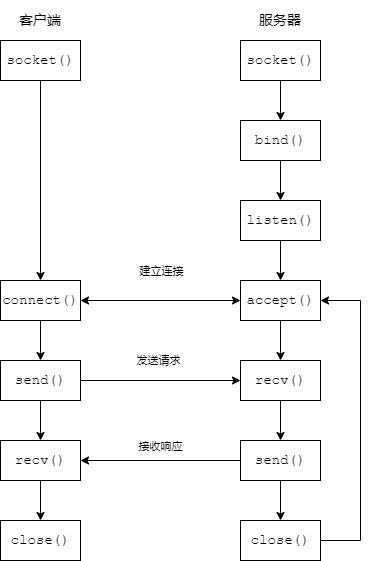
注意:服务器套接字只用于监听和接受连接,服务器使用accept()返回的新套接字(而不是服务器套接字本身)与客户端进行通信。
代码清单14-1和14-2展示了最简单的服务器和客户端示例。如果在同一台机器上运行它们(先运行服务器),服务器将打印一条收到连接请求的消息,然后客户端将打印它从服务器收到的消息。在服务器运行时,可以运行多个客户端。通过将客户端中的gethostname()调用替换为服务器所在机器的主机名,可以让这两个程序在不同的机器上通过网络连接起来。
注意:
- 在UNIX系统中,使用Ctrl+C停止服务器后,可能需要等待一段时间才能再次使用同一个端口号,否则会报错“地址已被占用”(OSError: [Errno 98] Address already in use)。为了避免这一问题,可以设置套接字标志
s.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1),或者将socketserver服务器的allow_reuse_address属性设置为True。 - 在macOS系统中,使用
socket.gethostname()作为服务器绑定的主机名可能会报错 “socket.gaierror: [Errno 8] nodename nor servname provided, or not known” ,因为/etc/hosts文件中没有将主机名映射到IP地址127.0.0.1。应使用''、'localhost'或'127.0.0.1'。
更详细的信息参考官方文档socket模块和Socket Programming HOWTO。
14.1.2 urllib包
在可用的网络库中,功能最强大的可能是urllib。它让你能够通过网络访问文件,就像这些文件位于你的计算机中一样。想像将这种功能与re模块结合使用的效果:你可以下载网页、从中提取信息并自动生成报告(网络爬虫)。
注:除了标准库,还有很多强大的第三方网络库。例如,Requests是一个高级HTTP库,Scrapy是一个网络爬虫框架,以及14.4节介绍的Twisted框架。
打开远程文件
使用urllib.request模块中的urlopen()函数可以几乎像本地文件一样打开远程文件,区别是只能使用读模式。
1
2
>>> from urllib.request import urlopen
>>> webpage = urlopen('https://www.python.org')
变量webpage是一个类似于文件的对象,包含Python网页内容。
注:网页内容是HTML文本,可以使用Chrome浏览器访问 “view-source:https://www.python.org/” 查看。
注意,可以使用以file:开头的URL访问本地文件,例如file:C:\text\somefile.txt。
urlopen()返回的类似于文件的对象支持close()、read()、readline()和readlines()方法,也支持迭代(注意:返回bytes而不是字符串)。
假设要提取刚才打开的Python网页中 “About” 链接的(相对)URL,可以使用正则表达式。
1
<a href="/about/" title="" class="">About</a>
1
2
3
4
5
>>> import re
>>> text = webpage.read().decode()
>>> m = re.search('<a href="([^"]+)" .*?>About</a>', text, re.IGNORECASE)
>>> m.group(1)
'/about/'
获取远程文件
可以使用urlretrieve()函数下载文件,并将其副本存储在一个本地文件中。
1
2
>>> from urllib.request import urlretrieve
>>> urlretrieve('https://www.python.org', 'D:\\python_webpage.html')
这将获取Python官网的主页,并将其存储到文件D:\python_webpage.html中。
一些实用函数
除了通过URL读取和下载文件外,urllib.parse模块还提供了一些用于操作URL的函数。
urlparse(url):将URL解析为6元组,scheme://netloc/path;params?query#fragment→(scheme, netloc, path, params, query, fragment)urlunparse(tuple):从6元组构造URLparse_qs(qs):将查询字符串(query string)解析为字典,key1=value1&key2=value2→{'key1': ['value1'], 'key2': ['value2']}urlencode(query):将映射转换为URL编码的查询字符串quote(string):将字符串中的特殊字符使用%xx转义unquote(string):将%xx转义替换为对应的字符
1
2
3
4
5
6
7
8
9
10
11
>>> from urllib.parse import *
>>> urlparse('https://docs.python.org/3/library/urllib.parse.html?highlight=params#url-parsing')
ParseResult(scheme='https', netloc='docs.python.org', path='/3/library/urllib.parse.html', params='', query='highlight=params', fragment='url-parsing')
>>> parse_qs('q=apple&category=fruits&page=1')
{'q': ['apple'], 'category': ['fruits'], 'page': ['1']}
>>> urlencode({'spam': 1, 'eggs': 2, 'bacon': 0})
'spam=1&eggs=2&bacon=0'
>>> quote('hello, world!')
'hello%2C%20world%21'
>>> unquote('%E4%BD%A0%E5%A5%BD')
'你好'
14.1.3 其他模块
下表列出了Python标准库中的一些与网络相关的模块。
| 模块 | 描述 |
|---|---|
asyncore, asynchat | 异步套接字处理程序(参见第24章) |
cgi | 基本的CGI支持(参见第15章) |
email | 电子邮件消息(包括MIME)支持 |
ftplib | FTP客户端模块 |
http.client | HTTP客户端模块 |
http.server | HTTP服务器模块 |
http.cookies | cookie对象操作,主要用于服务器 |
http.cookiejar | 客户端cookie支持 |
imaplib | IMAP4客户端模块 |
mailbox | 读取多种邮箱格式 |
mailcap | 通过mailcap文件访问MIME配置 |
nntplib | NNTP客户端模块(参见第23章) |
poplib | POP3客户端模块 |
smtpd | SMTP服务器模块 |
smtplib | SMTP客户端模块 |
telnetlib | Telnet客户端模块 |
urllib.parse | 操作URL |
urllib.robotparser | 解析Web服务器robot文件 |
xmlrpc.client | XML-RPC客户端模块(参见第27章) |
xmlrpc.server | 简单XML-RPC服务器(参见第27章) |
14.2 socketserver和相关的类
正如在上一节看到的,编写简单的套接字服务器并不难。然而,如果想超出基础功能,最好还是寻求些帮助。socketserver模块是标准库提供的服务器框架的基石,这个框架包括http.server、xmlrpc.server等,它们在基本服务器的基础上添加了各种功能。
socketserver包含2个基本的类:TCPServer(使用TCP流式套接字,继承自BaseServer)和UDPServer(使用UDP数据报套接字,继承自TCPServer)。
使用socketserver编写服务器时,大部分代码都位于请求处理器(request handler)中。每当服务器收到一个请求(来自客户端的连接)时,都将实例化一个请求处理器,并调用其处理方法来处理请求。请求处理器基类BaseRequestHandler将所有操作都放在handle()方法中,由服务器调用。该方法默认什么都不做,可以在子类中覆盖该方法来实现处理逻辑。这个方法可以通过self.request属性访问客户端套接字。如果处理流式套接字(使用TCPServer),可以使用StreamRequestHandler类,它包含另外两个属性:self.rfile(用于读)和self.wfile(用于写)。可以使用这两个类似于文件的对象来与客户端通信。
代码清单14-3是代码清单14-1所示的小型服务器的socketserver版本,可与代码清单14-2所示的客户端协同工作。注意,StreamRequestHandler在处理完成后会负责关闭连接。另外,主机名''表示运行服务器的机器。
有关socketserver模块的详细信息见官方文档socketserver。
注:
- 可以调用
BaseServer的handle_request()方法处理单个请求;也可以调用serve_forever()方法循环处理请求,直到调用shutdown()。 - 通过阅读源代码socketserver.py可知,服务器和请求处理器的主要方法调用关系如下:
1
2
3
4
5
6
7
8
9
BaseServer.serve_forever()
while True:
get_request()
process_request()
finish_request()
RequestHandler.__init__()
handle()
shutdown_request()
close_request()
TCPServer封装了14.1.1节所述的套接字通信流程:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
class TCPServer(BaseServer):
def __init__(self, ...):
super().__init__(...)
self.socket = socket.socket(...)
self.server_bind()
self.server_activate()
...
def server_bind(self):
self.socket.bind(self.server_address)
...
def server_activate(self):
self.socket.listen(self.request_queue_size)
def get_request(self):
return self.socket.accept()
def server_close(self):
self.socket.close()
14.3 多个连接
前面讨论的服务器解决方案都是同步(synchronous)的:一次只能处理一个客户端的连接请求。如果每个请求需要花费较长时间(比如完整的聊天会话),那么能够同时处理多个连接就很重要。
处理多个连接的主要方式有3种:分叉(forking)、线程化(threading)和异步I/O。通过结合使用socketserver中的混入类(mix-in class)和服务器类,很容易实现分叉和线程化。然而,它们确实存在缺点:分叉占用的资源较多,并且在客户端很多时可伸缩性不佳;线程化可能导致同步问题。这里不深入讨论这些问题,只演示如何使用这些方式。
分叉和线程是什么
分叉是一个UNIX术语。对进程(运行的程序)进行分叉,基本上是复制它,得到的两个进程都将从当前位置继续运行,且每个进程都有自己的内存副本(变量等)。原来的进程为父进程,复制的进程为子进程。可以将其视为并行宇宙:分叉操作在时间轴上创建一个分支,最终得到两个独立存在的宇宙。所幸进程能够判断它们是父进程还是子进程(通过查看fork()函数的返回值),因此能够执行不同的操作。
在分叉服务器中,对于每个客户端连接,都通过分叉创建一个子进程。父进程继续监听新连接,而子进程负责处理客户端请求。处理完成后,子进程直接退出。由于分叉出来的进程并行运行,因此客户端无需等待。
由于分叉占用的资源较多,还有另一种解决方案:线程化。线程是轻量级进程。所有的线程都存在于同一个进程中,并共享内存。这减少了资源消耗,但也带来了一个缺点:由于线程共享内存,你必须确保它们不会彼此干扰或同时修改同一项数据,否则将引起混乱。这些问题都属于同步问题。
14.3.1 使用socketserver实现分叉和线程化
使用socketserver创建分叉或线程化服务器非常简单,如代码清单14-4和14-5所示。注意,Windows系统不支持分叉。
注:
socketserver提供了实现分叉和线程化的混入类ForkingMixIn和ThreadingMixIn,只需将其与服务器类一起作为超类(混入类在前)。例如:
1
2
class ForkingTCPServer(ForkingMixIn, TCPServer):
pass
socketserver已经预定义了使用混入类的服务器类,例如ForkingTCPServer、ForkingUDPServer、ThreadingTCPServer和ThreadingUDPServer。
14.3.2 使用select和poll实现异步I/O
当服务器与客户端通信时,来自客户端的数据可能时断时续。如果使用了分叉或线程,这就不是问题,因为一个进程(线程)等待数据时,其他进程(线程)可以继续处理自己的客户端。然而,另一种做法是只处理在给定时刻真正在发送数据的客户端。你甚至不需要等待数据发送完,只需每次读取一点,然后将其放回队列即可。
这就是asyncore/asynchat框架(见第24章)和Twisted(见下一节)采用的方法。这种功能的基础是select()或poll()函数,都来自select模块。其中,poll()的可伸缩性更好,但只在UNIX系统中可用(在Windows中不可用)。
select()函数接受三个必选参数和一个可选参数,其中前三个参数为序列,第四个参数为超时时间(单位为秒)。这些序列包含文件描述符(file descriptor)整数(或包含返回文件描述符的fileno()方法的对象),即正在等待的连接。序列可以包含文件对象(Windows不支持)或套接字。这三个序列分别表示等待输入、输出和异常情况(错误等)。如果没有指定超时时间,select()将阻塞(等待)直到有文件描述符准备就绪;如果指定了超时时间,select()将最多阻塞指定的秒数;如果超时时间为0则直接轮询(即不阻塞)。select()返回三个序列,其中每个序列都包含相应参数中处于活动状态的文件描述符子集。例如,返回的第一个序列包含有数据可读取的输入文件描述符。
注:select()函数类似于Go语言的select语句。
代码清单14-6所示的服务器使用select()来为多个连接提供服务(注意,将服务器套接字传递给select(),使其能够在有新连接到来时发出信号)。这个服务器简单地将来自客户端的数据都打印出来。要进行测试,可以使用Telnet连接到它,或编写一个基于套接字的简单客户端来向它发送数据。
poll()函数使用起来比select()容易。调用poll()时,将返回一个轮询(poll)对象。可以使用register()方法向这个对象注册文件描述符(或包含fileno()方法的对象)。注册后可以使用unregister()方法将其删除。之后可以调用poll()方法(接受可选的超时时间参数)。这将返回一个(fd, event)对的列表(可能为空),其中fd是文件描述符,event是发生的事件。这是一个位掩码(bitmask)——一个整数,各个位(bit)对应不同的事件。各种事件用select模块中的常量表示,如下表所示。要检查指定的位是否为1(即是否发生了指定的事件),可以使用按位与运算符(&):
1
if event & select.POLLIN: ...
| 事件名 | 描述 |
|---|---|
POLLIN | 有可读取的数据 |
POLLPRI | 有需要读取的紧急数据 |
POLLOUT | 已准备好输出,写入不会阻塞 |
POLLERR | 出现了某种错误条件 |
POLLHUP | 挂起,连接已断开 |
POLLNVAL | 无效请求,连接未打开 |
代码清单14-7使用poll()重写了代码清单14-6所示的服务器。
14.4 Twisted
Twisted (https://twisted.org/) 是一个事件驱动的Python网络框架。本节介绍一些基本概念,并演示如何使用Twisted完成一些简单的网络编程。掌握这些基本概念后,就可以参考Twisted文档来完成更复杂的网络编程。Twisted是一个功能极其丰富的框架,支持Web服务器和客户端、SSH2、SMTP、POP3、IMAP4、AIM、ICQ、IRC、MSN、Jabber、NNTP、DNS,等等。
14.4.1 下载和安装Twisted
可以使用Python自带的包管理工具pip安装Twisted:
1
$ pip install twisted
这样应该就能够使用twisted模块了。
注:pip默认将依赖安装在全局环境中,可以使用venv模块或Conda创建独立的“虚拟环境”,从而更好地管理依赖。
14.4.2 编写Twisted服务器
本章前面编写的简单套接字服务器是非常显式的:包含显式的事件循环,用于查找新连接和新数据。基于socketserver的服务器有一个隐式的循环,用于查找连接并为每个连接创建处理器,但处理器仍然必须显式地读取数据。Twisted采用的是基于事件的方法。要编写简单的服务器,只需实现特定情况的事件处理器(event handler),例如新客户端连接、新数据到达、客户端断开连接等等。
事件处理器是在协议(protocol)中定义的。你还需要一个工厂(factory),能够在新连接到来时创建协议对象,可以使用Twisted自带的工厂:twisted.internet.protocol模块中的Factory类。编写自定义协议时,将该模块中的Protocol作为超类。有新连接到来时,将调用事件处理器connectionMade();失去连接时,将调用connectionLost();来自客户端的数据是通过dataReceived()接收的。当然,不能使用事件处理策略来向客户端发送数据,需要使用self.transport对象,它包含write()方法。这个对象还有一个client属性,包含客户端地址(主机名和端口)。
代码清单14-8是代码清单14-6和14-7所示服务器的Twisted版本。
如果使用Telnet连接到这个服务器来测试它,每行输出可能只有一个字符,取决于缓冲等因素。在很多情况下,你可能希望每次得到一行,而不是任意的数据。实际上已经有一个现成的类:twisted.protocols.basic模块包含一些有用的预定义协议,其中的LineReceiver。它实现了dataReceived(),并在每次收到一整行后调用lineReceived()。
切换协议只需要很少的工作,如代码清单14-9所示。
代码清单14-9 使用LineReceiver改进的日志服务器
Twisted框架的功能比这里介绍的要多得多。如果要想更深入地了解,可参阅Twisted网站的在线文档(https://docs.twisted.org/en/stable/)。