《Python基础教程》笔记 第15章 Python和Web
本章讨论Python Web编程的一些方面。Web编程涉及的范围极广,这里挑选了两个重要的主题:屏幕抓取和CGI。
15.1 屏幕抓取
屏幕抓取(screen scraping)是通过程序下载网页并从中提取信息的过程(即网络爬虫)。这种技术很有用,在网页中有你要在程序中使用的信息时,就可以使用它。当然,如果网页是动态的,即随时间变化的,这就更有用了。否则,只需下载一次并手工提取信息。(理想情况是,可以通过Web服务来获取这些信息,这将在15.4节讨论。)
从概念上说,这种技术非常简单:下载数据并对其进行分析。例如,可以使用urllib来获取网页的HTML源代码,并使用正则表达式来提取信息。例如,假设你要从Python Job Board (https://www.python.org/jobs/)提取招聘单位的名称和网站。通过查看网页源代码,发现可以在类似于下面的链接中找到名称和URL:
1
<a href="/jobs/1970/">Python Engineer</a>
注:使用Chrome浏览器可以在网页上点击右键,选择“查看网页源代码”。
代码清单15-1所示的示例程序使用urllib和re来提取所需的信息。
注:使用urlopen()获取的网页内容可能是经过压缩的,因此不能直接调用decode(),必须先根据响应头Content-Encoding指定的压缩方式进行解压缩。例如,上述URL返回的内容是使用gzip压缩的:
1
2
3
4
5
6
>>> from urllib.request import urlopen
>>> f = urlopen('https://www.python.org/jobs/')
>>> f.getheader('Content-Encoding')
'gzip'
>>> f.peek()
b'\x1f\x8b\x08\x00\x00\x00\x00\x00\x00\x03\xed}\xebr\x1bG\x96\xe6\xef...'
需要使用gzip或zlib模块解压缩:
1
2
3
>>> import gzip
>>> gzip.GzipFile(fileobj=f).read()[:50]
b'\n\n<!doctype html>\n<!--[if lt IE 7]> <html class='
1
2
3
>>> import zlib
>>> zlib.decompress(f.read(), 16 + zlib.MAX_WBITS)[:50]
b'\n\n<!doctype html>\n<!--[if lt IE 7]> <html class='
另一种方法是使用Requests库,它提供了非常方便的HTTP请求API,并且能自动解压缩响应内容。
1
$ pip install requests
1
2
3
4
>>> import requests
>>> r = requests.get('https://www.python.org/jobs/')
>>> r.text[:50]
'\n\n<!doctype html>\n<!--[if lt IE 7]> <html class='
(回到正文)这段代码已经做得非常好了。然而,这种方法至少存在3个缺点:
- 正则表达式可读性差。
- 无法处理像CDATA部分和字符实体(例如
&)之类的HTML特性。 - 正则表达式依赖于HTML代码的细节,而不是更抽象的结构。这意味着网页结构的细微就会使程序失效。
针对基于正则表达式的方法存在的问题,接下来讨论两种可能的解决方案。一是结合使用Tidy程序(一个Python库)和XHTML解析;二是使用专门为屏幕抓取而设计的Beautiful Soup库。
注意:还有其他的Python屏幕抓取工具,例如scrape.py和Scrapy。
15.1.1 Tidy和XHTML解析
Python标准库为解析HTML和XML等结构化格式提供了强大的支持(参见官方文档Structured Markup Processing Tools)。本节只介绍处理XHTML所需的工具。XHTML即“使用XML语法的HTML”,与HTML相比语法要求更加严格。
标准库提供的HTML解析方法是基于事件的:编写事件处理器,供解析器处理数据时调用。标准库模块html.parser让你能够以这种方式解析非常凌乱的HTML,但如果要基于文档结构来提取数据(例如第二个二级标题后面的第一项),在标签缺失的情况下恐怕就只能靠猜了。不过还有另一种方式:Tidy。
Tidy是什么
Tidy是用于对格式不正确且不严谨的HTML进行修复的工具。
下面是一个错误百出的HTML文件,有些是过时的HTML,有些则是明显的错误:
下面是Tidy修复后的版本:
当然,Tidy并不能修复HTML文件的所有问题,但能够确保文件是格式良好的(即所有元素都正确嵌套),这让解析工作容易得多。
获取Tidy
不管使用的是哪种操作系统,都可以从Tidy网站(https://www.html-tidy.org/)获取可执行的二进制版本。
- 对于Windows系统,从下载页面下载tidy-5.8.0-win64.zip,解压后使用bin\tidy.exe。
- 对于Linux或macOS系统,可以通过系统自带的包管理器安装,见网站主页Get Tidy一节。
之后可以在命令行中使用以下命令修复messy.html,并输出到tidy.html:
1
$ tidy -o tidy.html messy.html
注:大多数Web浏览器都非常宽容,即使是最混乱、最无意义的HTML,也会尽最大努力将其渲染出来。因此直接使用浏览器打开这两个HTML文件,会发现“看起来”并没有太大差别。
为什么使用XHTML
XHTML和旧式HTML的主要区别在于,XHTML语法非常严格,要求显式结束所有的元素。例如,在HTML中,可以通过(使用标签<p>)开始另一个段落来结束当前段落;但在XHTML中,必须先(使用标签</p>)显式地结束当前段落。这让XHTML解析起来容易得多,因为你能清楚地知道何时进入或离开各种元素。XHTML的另一个优点是,它是一种XML方言,因此可以使用各种精巧的XML工具来处理,例如XPath(详见【Scrapy】选择器)。
要解析XHTML,一种非常简单的方式是使用标准库模块html.parser中的HTMLParser类。
使用HTMLParser
要使用HTMLParser,只需继承它并覆盖各种事件处理方法。下表总结了相关方法以及何时被解析器自动调用。
| 回调方法 | 何时被调用 |
|---|---|
handle_starttag(tag, attrs) | 遇到开始标签(例如<div>)时调用,attrs是属性((name, value)对的序列) |
handle_endtag(tag) | 遇到结束标签(例如</div>)时调用 |
handle_startendtag(tag, attrs) | 遇到空标签(例如<img ... />)时调用,默认分别处理开始和结束标签 |
handle_data(data) | 遇到文本数据时调用 |
handle_entityref(name) | 遇到形如&name;的实体引用(例如>)时调用 |
handle_charref(ref) | 遇到形如&#ref;的字符引用(例如>)时调用 |
handle_comment(data) | 遇到注释时(例如<!--comment-->)调用 |
handle_decl(decl) | 遇到形如<!...>的声明(例如<!DOCTYPE html>)时调用 |
handle_pi(data) | 遇到处理指令(例如<?proc color='red'>)时调用 |
unknown_decl(data) | 遇到未知声明时调用 |
就屏幕抓取而言,通常无需实现所有的回调方法(事件处理器),只要记录下找到目标内容所需的信息就可以了。代码清单15-2所示程序解决的问题与代码清单15-1相同,但使用了HTMLParser。
有几点需要注意,首先,这里没有使用Tidy,因为这个网页的HTML格式足够良好。另外,使用了一个布尔状态变量(in_link属性)来跟踪是否位于相关的链接中(<a>标签且href属性是job URL),在事件处理器中检查并更新这个属性。其次,handle_starttag()的attrs参数是一个(key, value)元组的列表,使用dict()将其转换为字典,以便管理。
handle_data()方法(和chunks属性)使用的技术在基于事件的结构化标记(例如HTML和XML)解析中很常见:不是假定一次调用就能获得所有文本,而是假定这些文本分成多个块(chunk),需要多次调用才能获得。导致这种情况的原因有多种——缓冲、字符实体、忽略的标记等。为了确保获取到所有的文本,在handle_endtag()方法中将所有的文本块合并在一起。要运行这个解析器,调用feed()方法提供HTML内容,然后调用close()方法。
注:例如,当处理下面的HTML代码时
1
<a href="/jobs/7544/"><b>Senior</b> Software Engineer</a>
解析器将会依次调用以下回调方法:
1
2
3
4
5
6
handle_starttag('a', [('href', '/jobs/7544/')])
handle_starttag('b', [])
handle_data('Senior')
handle_endtag('b')
handle_data(' Software Engineer')
handle_endtag('a')
输出结果为 “Senior Software Engineer (/jobs/7544/)” 。
15.1.2 Beautiful Soup
Beautiful Soup (https://www.crummy.com/software/BeautifulSoup/)是一个小巧而出色的模块,用于解析在Web上可能遇到的不严谨且格式糟糕的HTML。
安装Beautiful Soup易如反掌,可以使用pip:
1
$ pip install beautifulsoup4
使用Beautiful Soup提取Python职位信息的例子非常简单,也非常易读,如代码清单15-3所示。
代码清单15-3 使用Beautiful Soup的屏幕抓取程序
这个程序不是搜索URL的内容,而是导航HTML文档结构。例如,使用soup.body来获取文档体<body>,再访问其中的第一个<section>。使用参数'h2'调用该对象,返回其中的所有<h2>元素。每个<h2>元素都表示一个职位,而感兴趣的是它包含的第一个链接job.a。a.string是其文本内容,a['href']是href属性的值。(注:这一段要对照网页的HTML源代码才能理解)
15.2 使用CGI创建动态网页
本节讨论基本的Web编程技术:通用网关接口(Common Gateway Interface, GCI)。CGI是一种标准机制,Web服务器可以通过它将(通常是通过Web表单提供的)查询交给专门的程序(例如你的Python程序),并以网页的形式展示结果。这是一种创建Web应用的简单方式,无需专用的应用服务器。有关Python CGI编程的详细信息参见CGI Scripts。
Python CGI编程的关键工具是cgi模块。另一个对开发CGI脚本很有帮助的模块是cgitb,将在15.2.6节详细介绍。
要让CGI脚本能够通过Web访问和运行,必须将其放在Web浏览器能够访问的地方、添加#!行并设置合适的文件权限。接下来依次介绍这三个步骤。
15.2.1 第1步:准备Web服务器
如果只是想试验一下,可以直接使用http.server模块运行一个临时Web服务器。可以使用python命令的-m选项运行这个模块。如果指定了--cgi选项,启动的服务器将支持CGI。这个服务器将提供运行它时所在目录的文件。
1
2
$ python -m http.server --cgi
Serving HTTP on :: port 8000 (http://[::]:8000/) ...
使用浏览器访问 http://127.0.0.1:8000 或 http://localhost:8000 ,将看到运行这个服务器所在目录的内容。
CGI程序也必须放在可通过Web访问的目录中。另外,必须将其标识为CGI脚本,以免Web服务器直接以网页的形式展示其源代码。为此,有两种常见的方式:
- 将脚本放在cgi-bin子目录中。
- 将脚本文件扩展名改为.cgi。
如果使用的是http.server模块中的服务器,应使用cgi-bin子目录。
15.2.2 第2步:添加#!行
接下来,必须在脚本开头添加#! (pound bang)行。第1章说过,这样无需显式地执行Python解释器就能执行脚本。通常,这只是为了方便,但对于CGI脚本来说却至关重要——没有它,Web服务器就不知道如何执行脚本。一般来说,只需在脚本开头添加下面一行即可:
1
#!/usr/bin/env python
注意,它必须是第一行。如果这样不管用,就需要指定Python解释器的完整路径(可使用which python命令查看):
1
#!/usr/bin/python
如果同时安装了Python 2和3,可能需要将python替换为python3。如果仍然不管用,可能存在你看不到的错误,即这一行以\r\n而不是\n结尾。确保将脚本保存为UNIX风格的文本文件。
在Windows中,使用Python解释器的完整路径:
1
#!C:\Python311\python.exe
15.2.3 第3步:设置文件权限
(如果Web服务器运行在UNIX或Linux机器上)需要做的最后一件事情是设置合适的文件权限。必须确保脚本文件对所有人都是可读和可执行的,同时确保只有你才能写入。
在UNIX中,修改文件权限(或文件模式)的命令为chmod。例如:
1
chmod 755 somescript.cgi
注:
- 在上面的命令中,755的意思是“自己可读、可写、可执行,其他人可读、可执行、不可写”。
- cgi-bin目录必须是运行服务器所在目录的直接子目录。
- 在Linux和macOS系统上,脚本扩展名可以是.py或.cgi,必须添加#!行,必须给脚本文件添加可执行权限。
- 在Windows系统上,脚本扩展名必须是.py(如果是.cgi会报错“不是有效的 Win32 应用程序”),如果使用
http.server则不需要#!行(自动使用运行服务器的Python可执行程序运行脚本),不存在文件权限问题。
15.2.4 CGI安全风险
使用CGI程序存在一些安全风险。如果你允许CGI脚本对服务器中的文件执行写入操作,那么这可能被人利用来破坏数据,除非编写程序时非常小心。同样,如果直接将用户提供的数据作为Python代码(例如使用exec()或eval())或shell命令(例如使用os.system()或subprocess模块)执行,就可能执行恶意命令,面临极大的风险。即便在SQL查询中使用用户提供的字符串也很危险,除非先仔细审查这些字符串,SQL注入是一种常见的系统攻击方式。
15.2.5 简单的CGI脚本
最简单的CGI脚本如代码清单15-4所示。
这个程序输出的(几乎)所有内容都出现在网页中。事实上,这是HTTP消息的格式:
- 首先是HTTP标头(header),包含有关网页的信息。每行一个标头,格式为
Key: Value。Content-Type: text/plain指出这个网页是纯文本的。 - 之后是一个空行。
- 接下来是网页内容,这里是字符串
'Hello, world!'。
将脚本保存为simple1.cgi,假设放在somedir/cgi-bin目录下:
1
2
3
somedir/
cgi-bin/
simple1.cgi
在somedir目录下用15.2.1节的方式启动Web服务器,在浏览器访问 http://localhost:8000/cgi-bin/simple1.cgi (Windows上需要将后缀改为.py),效果如下图所示。
15.2.6 使用cgitb调试
为了帮助调试CGI脚本,标准库提供了一个很有用的模块cgitb(CGI traceback)。通过导入这个模块并调用enable()函数,当程序出错时可以显示一个包含出错信息的网页。代码清单15-5演示了如何使用cgitb模块。
在浏览器中访问这个脚本时,结果如下图所示。
注:如果不使用cgitb,将得到一个空白页面,HTTP状态码仍然是200,服务器程序的控制台会打印栈跟踪。
注意,程序开发完后应关闭cgitb功能。
15.2.7 使用cgi模块
到目前为止,CGI脚本只生成输出,而没有使用任何形式的输入。输入是通过HTML 表单(form)以键值对(字段(field))的形式提供给CGI脚本的。在CGI脚本中,可以使用cgi模块中的FieldStorage类来获取这些字段。当创建FieldStorage实例时(应该只创建一个),它将从请求中获取输入字段,并通过一个类似于字典的接口提供给程序。例如,请求包含一个name字段,可以这样获取它的值:
1
2
form = cgi.FieldStorage()
name = form['name'].value
一种更简单的获取值的方式是使用getvalue()方法,类似于字典的get()方法。如果字段没有值则使用默认值(默认为None)。
1
name = form.getvalue('name', 'Unknown')
代码清单15-6是一个使用cgi.FieldStorage的简单示例。
代码清单15-6 从FieldStorage获取单个值的CGI脚本
不用表单调用CGI脚本
CGI脚本的输入通常来自提交的表单,但也可以在调用CGI脚本时直接指定参数。为此,可在脚本的URL后面加上问号,再添加&分隔的键值对。例如,如果代码清单15-6所示脚本的URL为 http://www.example.com/simple2.cgi ,则可以这样使用参数name=Gumby和age=42来调用这个脚本: http://www.example.com/simple2.cgi?name=Gumby&age=42 。这样CGI脚本将显示消息 “Hello, Gumby!” 而不是 “Hello, world!” (注意,age参数没有使用)。可以使用urllib.parse模块中的urlencode()函数创建这样的URL查询(见14.1.2节):
1
2
>>> urlencode({'name': 'Gumby', 'age': '42'})
'name=Gumby&age=42'
15.2.8 简单的表单
有了处理用户请求的工具,是时候创建用户可以提交的表单了。要深入地了解如何编写HTML表单,可参考在线文档:
代码清单15-7是扩展后的版本。
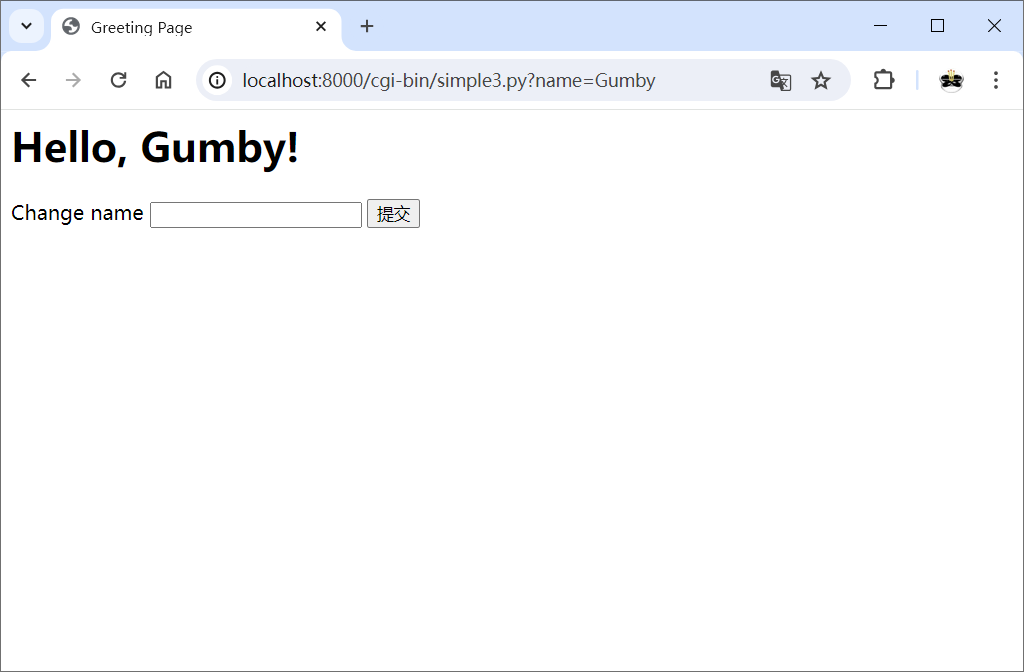
在脚本开头获取参数name,与以前一样,默认为'world'。如果在浏览器中直接打开这个脚本而没有提交任何值,将使用默认值。
接下来,打印了一个简单的HTML页面,其中的标题包含name的值。另外,这个页面还包含一个HTML表单,其action属性被设置为脚本自身的名称(simple3.cgi)(注意,在Windows上需要将后缀改为.py),这意味着提交表单后将再次运行这个脚本。表单中唯一的输入元素是名为name的文本框。因此,如果在文本框中输入新名字并提交表单,标题将发生变化。
运行结果如下图所示。
15.3 使用Web框架
对于重要的Web应用,大多数人都不会直接为其编写CGI脚本,而是使用Web框架,因为它会为你完成很多繁重的工作。本节关注既简单又有用的Flask(https://flask.palletsprojects.com/)。使用pip安装很容易。
1
$ pip install flask
假设你编写了一个计算幂的函数:
1
2
def powers(n):
return ', '.join(str(2**i) for i in range(n))
而且想让全世界都能使用这一杰作!要使用Flask来实现这个目标,首先使用合适的名称实例化Flask类,并告诉它这个函数对应的URL路径。
如果这个脚本名为powers.py,就可以像下面这样让Flask运行它:
1
2
3
4
$ flask --app powers run
* Serving Flask app 'powers'
* Running on http://127.0.0.1:5000
Press CTRL+C to quit
使用route()设置函数的URL路径,这样就可以设置多个函数,每个函数的URL各不相同。
可以向函数提供参数。在URL路径中使用尖括号指定参数,例如route('/powers/<n>')。这样,斜杠后面的内容将作为关键字参数n的值。但这样提供的是一个字符串,而这里需要一个整数。可以使用route('/powers/<int:n>')添加转换。访问URL http://127.0.0.1:5000/powers/3 ,将得到输出 “1, 2, 4” 。
Flask还有很多其他的功能,其文档也很容易阅读。如果要尝试简单的服务器端Web应用开发,建议看看这些文档。
其他Web应用框架
还有很多其他的Web框架,有大有小。下表列出了几个流行的框架,完整列表参见Python文档WebFrameworks。
| 名称 | 网站 |
|---|---|
| Django | https://www.djangoproject.com/ |
| TurboGears | https://turbogears.org/ |
| web2py | http://web2py.com/ |
| Grok | https://pypi.org/project/grok/ |
| Zope | https://zope.readthedocs.io/ |
| Pyramid | https://trypyramid.com/ |
15.4 Web服务:更高级的抓取
Web服务通常在相当高的抽象层次上工作,将HTTP用作底层协议。在这个协议上面,使用更加面向内容的协议(例如XML格式)来对请求和响应进行编码。这意味着Web服务器可以作为Web服务的平台。正如本节的标题指出,它是提高到另一个层次的Web抓取。可以将Web服务看作为计算机(而不是人类)设计的动态网页。
有些Web服务标准非常复杂,但也可以用完全简单的方式完成很多任务。本节只简要地介绍这个主题,并提供所需工具和信息的指南。
15.4.1 RSS和相关内容
RSS指的是富站点摘要(Rich Site Summary)、RDF站点摘要(RDF Site Summary)或简易信息聚合(Really Simple Syndication),具体指哪个取决于版本。在最简单的情况下,RSS是一种以XML形式列出新闻的格式。RSS文档(feed)之所以更像是一种服务而不仅仅是静态文档,是因为它们是定期或不定期更新的。它们甚至可能是动态计算的,例如表示最近的博客更新。另一种相同用途的较新格式是Atom。有关RSS和资源描述框架(RDF)的详细信息,参见 https://www.w3.org/RDF/ 。有关Atom规范,参见 https://datatracker.ietf.org/doc/html/rfc4287 。
15.4.2 使用XML-RPC进行远程过程调用
远程过程调用(remote procedure call, RPC)是对基本网络交互的抽象:客户端程序请求服务器程序执行计算并返回结果,但这个过程被伪装成简单的过程(函数)调用。在客户端代码中,远程过程调用看起来就像普通方法调用,但用来调用方法的对象实际上位于另一台计算机中。XML-RPC可能是最简单的远程过程调用机制,它使用HTTP和XML来实现网络通信。由于这种协议是语言无关的,使用一种语言编写的客户端程序可以很容易地调用使用另一种语言编写的服务器程序中的函数。
Python标准库提供了对客户端和服务器端XML-RPC编程的支持。XML-RPC的使用示例见第27和28章。
RPC和REST
远程过程调用可与表述性状态转移(representational state transfer, REST)网络编程进行比较,尽管两种机制完全不同。基于REST的(RESTful)程序也能让客户端以编程方式访问服务器,但假定服务器程序没有任何隐藏状态。返回的数据完全由给定的URL(在HTTP POST中,是客户端提供的额外数据)决定。
有关REST的详细信息可参阅维基百科(https://en.wikipedia.org/wiki/REST)。在RESTful编程中,经常使用的一种简单而优雅的协议是JSON (https://www.json.org/),让你能够使用纯文本格式来表示复杂的对象。标准库模块json提供了对JSON格式的支持。
15.4.3 SOAP
SOAP也是一种消息交换协议,将XML和HTTP作为底层技术。与XML-RPC一样,SOAP也支持远程过程调用,但SOAP规范比XML-RPC规范复杂得多。SOAP是异步的,支持有关路由的元请求,而且类型系统非常复杂。
目前没有标准的Python SOAP工具包。可以考虑使用Twisted (https://twisted.org/)、ZSI (https://pywebsvcs.sourceforge.net/)或SOAPy (https://soapy.sourceforge.net/)。有关SOAP格式的详细信息,参见 https://www.w3.org/TR/soap/ 。