《Python基础教程》笔记 第17章 扩展Python
Python可以实现任何东西。这门语言功能强大,但有时候速度又太慢。Python的目标是易于使用以及帮助提高开发速度,这种灵活性是以牺牲效率为代价的。对于大多数常见的编程任务来说,Python当然足够快。但如果真的很在意速度,C、C++、Java和Julia等语言通常要快好几个数量级。
17.1 两全其美
虽然只使用C语言能提高程序本身的速度,但肯定会降低编程速度。因此你需要考虑哪一点更重要:是快速编写好程序,还是很久以后终于编写出了一个运行得非常非常快的程序。
本章讨论确实需要进一步提升速度的情况。最佳的解决方案可能不是完全转向C语言(或其他中低级语言),而是推荐下面的方法(已经对许多工业级速度至上的需求有效):
- 使用Python开发原型(prototype)(有关原型设计,参阅第19章)。
- 对程序进行性能分析以找出瓶颈(参阅第16章)。
- 使用C(或C++、C#、Java、Fortran等)扩展重写瓶颈部分。
这样得到的框架——包含一个或多个C语言组件的Python框架——是非常强大的,因为它兼具这两门语言的优点。关键在于为每项任务选择正确的工具。
扩展的另一种常见情形是遗留代码。你可能想使用一些用C语言编写的代码。可以将这些代码“包装”起来(编写一个提供合适接口的小型C语言库),并创建Python扩展库。
接下来的几节将简要地介绍如何扩展Python的经典C语言实现CPython(可以自己编写所有代码,也可以使用SWIG工具),以及如何扩展其他两种实现:Jython和IronPython。另外,还将讨论访问外部代码的其他方式。
17.2 真正简单的方法:Jython和IronPython
如果使用Jython (https://www.jython.org/)或IronPython (https://ironpython.net/),使用原生模块扩展Python是很容易的,因为能够直接访问底层语言中的模块和类(Jython使用Java,IronPython使用C#和其他.NET语言),从而无需遵循特定的API(像扩展CPython那样)。例如,在Jython中可以直接访问Java标准库,而在IronPython中可以直接访问C#标准库。
安装Jython
首先安装JDK 8。之后从Jython网站(https://www.jython.org/download)下载安装程序jython-installer-2.7.3.jar,双击执行JAR文件打开GUI安装界面,或者在命令行中执行以下命令将Jython安装到指定目录中:
1
$ java -jar jython-installer-2.7.3.jar -s -d /path/to/jython
安装完成后,运行bin/jython(类似于Python解释器,但可以访问Java标准库和导入Java类)。
1
2
3
4
5
6
7
$ jython
Jython 2.7.3 (tags/v2.7.3:5f29801fe, Sep 10 2022, 18:52:49)
[Java HotSpot(TM) 64-Bit Server VM (Oracle Corporation)] on java1.8.0_181
Type "help", "copyright", "credits" or "license" for more information.
>>> from java.lang import System
>>> System.out.println('Hello, Jython!')
Hello, Jython!
代码清单17-1展示了一个简单的Java类。
可以使用Java编译器(javac)来编译这个类,得到类文件JythonTest.class。
1
$ javac JythonTest.java
编译这个类后,启动Jython(并将.class文件放到当前目录或Java CLASSPATH包含的目录中)。
1
$ CLASSPATH=JythonTest.class jython
然后就可以直接导入这个类了。
1
2
3
4
>>> import JythonTest
>>> test = JythonTest()
>>> test.greeting()
Hello, world!
安装IronPython
Windows系统通常已经安装了.NET Framework,包含C#编译器(例如C:\Windows\Microsoft.NET\Framework64\v4.0.30319\csc.exe)。从IronPython网站(https://ironpython.net/download/)下载IronPython.3.4.1.zip,解压后运行net462/ipy.exe(类似于Python解释器,但可以访问C#标准库和导入C#类库)。
1
2
3
4
5
6
7
$ ipy
IronPython 3.4.1 (3.4.1.1000)
[.NETFramework,Version=v4.6.2 on .NET Framework 4.8.9232.0 (64-bit)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import System
>>> System.Console.WriteLine('Hello, IronPython!')
Hello, IronPython!
代码清单17-2展示了一个类似(代码清单17-1)的C#类。
使用C#编译器来编译这个类。对于Microsoft .NET,命令如下:
1
csc.exe /t:library IronPythonTest.cs
这将生成动态链接库(DLL) IronPythonTest.dll。将环境变量IRONPYTHONPATH设置为.dll文件所在目录,然后就应该能够像下面这样使用它了(使用IronPython交互式解释器ipy):
1
2
3
4
5
6
>>> import clr
>>> clr.AddReferenceToFile('IronPythonTest.dll')
>>> import FePyTest
>>> f = FePyTest.IronPythonTest()
>>> f.greeting()
Hello, world!
17.3 编写C语言扩展
扩展Python通常意味着扩展CPython——使用C语言实现的标准版Python。使用C语言编写Python扩展时,必须遵循严格的API,这将在17.3.2节讨论。有几个项目力图简化C语言扩展的编写过程,其中比较有名的一个是SWIG,将在下一节讨论。
其他方法
如果你使用CPython,有很多工具可以帮助提高程序的速度,这是通过生成和使用C语言库,或者提高Python代码的速度实现的。下面是一些选择。
- Cython (https://cython.org/)
- PyPy (https://www.pypy.org/)
- SciPy (https://scipy.org/)
- NumPy (https://numpy.org/)
- ctypes (https://docs.python.org/3/library/ctypes.html)
- subprocess (https://docs.python.org/3/library/subprocess.html)
- PyCXX (https://cxx.sourceforge.net/)
- SIP (https://github.com/Python-SIP/sip)
- Boost.Python (https://www.boost.org/doc/libs/release/libs/python/)
17.3.1 SWIG
SWIG (https://www.swig.org/)是简单包装器和接口生成器(Simple Wrapper and Interface Generator)的缩写,是一个适用于多种语言的工具。一方面,它让你能够用C或C++编写扩展代码;另一方面,它自动包装这些代码,让你能够在Tcl、Python、Perl、Ruby和Java等高级语言中使用它们。
安装
很多UNIX/Linux系统都包含SWIG;很多包管理器也能够直接安装。例如:
1
$ sudo apt install swig
对于Windows系统,从网站 https://www.swig.org/download.html 下载swigwin-4.2.1.zip,解压后使用其中的swig.exe。
用法
SWIG使用起来很简单。假设有一些C语言代码:
- 为代码编写一个接口文件(interface file)。这很像C语言头文件(对于简单的情况,可以直接使用头文件)。
- 对接口文件运行SWIG,以自动生成包装代码(wrapper code)。
- 将原来的C语言代码和生成的包装代码一起编译,以生成共享库。
接下来将讨论每个步骤,先从一些C语言代码开始。
回文
回文(palindrome)是忽略空格、标点等后正着读和反着读一样的句子(例如 “I prefer pi”, “detartrated” )。假设要分析的字符串极长,而且需要做大量这样的检查,因此你决定编写一段C语言代码来处理(也可能找到了现成的代码)。代码清单17-3是一种可能的实现。
作为比较,代码清单17-4展示了等价的纯Python函数。
下面介绍如何编译和使用这段C语言代码。
接口文件
假设将代码清单17-3所示的代码存储在文件palindrome.c中,现在应该在文件palindrome.i中添加接口描述。
在接口文件中,只需声明要导出的所有函数(和变量),就像在头文件中一样。另外,在顶部有一个由%{和%}分隔的部分,可以在其中指定要包含的头文件(在这里是string.h)。在这之前,还有一个%module声明,用于指定模块名。关于接口文件的详细信息参见SWIG文档。代码清单17-5展示了接口文件。
运行SWIG
使用接口文件作为参数运行SWIG,选项-python让SWIG包装C语言代码,以便能够在Python中使用。另一个可能有用的开关是-c++,用于包装C++库。
1
$ swig -python palindrome.i
这将生成两个新文件:palindrome_wrap.c和palindrome.py。
编译、链接和使用
编译可能是最棘手的部分(确实!)。要正确地编译,需要知道Python源代码(至少是头文件pyconfig.h和Python.h)的存储位置。还需要根据选择的C语言编译器,使用正确的选项将代码编译成共享库(动态链接库)。
注:扩展CPython需要用到其头文件(例如Python.h)和库文件(例如python3.dll或libpython3.so)。在Windows上,Python标准安装已经包含了这些文件,安装目录结构如下(Conda环境也一样):
1
2
3
4
5
6
7
8
9
10
11
12
D:\Python
Python311\
include\
Python.h # 头文件
Lib\ # Python标准库
fileinput.py
libs\
python3.lib # 静态链接库
python311.lib
python.exe # 交互式解释器
python3.dll # 动态链接库
python311.dll
在Linux上,如果使用系统自带的Python(例如/usr/bin/python3),则头文件应该在/usr/include/python3.6目录中,库文件应该在/usr/lib目录中。如果没有,则需要安装Conda环境,目录结构如下:
1
2
3
4
5
6
7
8
9
10
11
/path/to/conda/envs/myenv
bin/
python # 交互式解释器
include/
python3.11/
Python.h # 头文件
lib/
python3.11/ # Python标准库
fileinput.py
libpython3.so # 动态链接库
libpython3.11.so
(1)Linux
下面是在Linux中使用gcc编译器的示例(假设$PYTHON_HOME指向Python安装目录):
1
2
3
gcc -fPIC -c palindrome.c
gcc -fPIC -c -I$PYTHON_HOME/include/python3.11 palindrome_wrap.c
gcc -shared palindrome.o palindrome_wrap.o -o _palindrome.so
注:关于编译和链接的基本知识以及GCC编译器的基本用法见GCC编译器的使用方法。
念完这些“黑暗魔咒”后,将得到一个很有用的文件_palindrome.so。这就是共享库(shared library),可以直接导入到Python中(前提是将其放到PYTHONPATH包含的目录中,例如当前目录):
1
2
3
4
5
6
7
8
9
>>> import _palindrome
>>> _palindrome
<module '_palindrome' from '.../_palindrome.so'>
>>> dir(_palindrome)
['__doc__', '__file__', '__name__', ..., 'is_palindrome']
>>> _palindrome.is_palindrome('ipreferpi')
1
>>> _palindrome.is_palindrome('notlob')
0
较新版本的SWIG还会生成Python包装代码(palindrome.py),它导入_palindrome模块并执行一些检查工作。使用包装代码的效果与使用共享库相同。
1
2
3
4
5
6
7
>>> import palindrome
>>> palindrome
<module 'palindrome' from '.../palindrome.py'>
>>> if palindrome.is_palindrome('abba'):
... print('Wow -- that never occurred to me ...')
...
Wow -- that never occurred to me ...
(2)macOS
在macOS中,gcc命令实际上是Clang编译器,编译选项有所不同:
1
2
3
gcc -dynamic -c palindrome.c
gcc -dynamic -c -I$PYTHON_HOME/include/python3.11 palindrome_wrap.c
gcc -dynamiclib palindrome.o palindrome_wrap.o -o _palindrome.so -Wl,-undefined,dynamic_lookup
(3)Windows
在Windows中,CPython扩展库的后缀名是.pyd而不是.so,必须使用MSVC编译器构建。为此,需要下载Visual Studio IDE或者Visual Studio生成工具。
安装时,勾选“使用C++的桌面开发”、“MSVC”和“Windows SDK”,如下图所示。
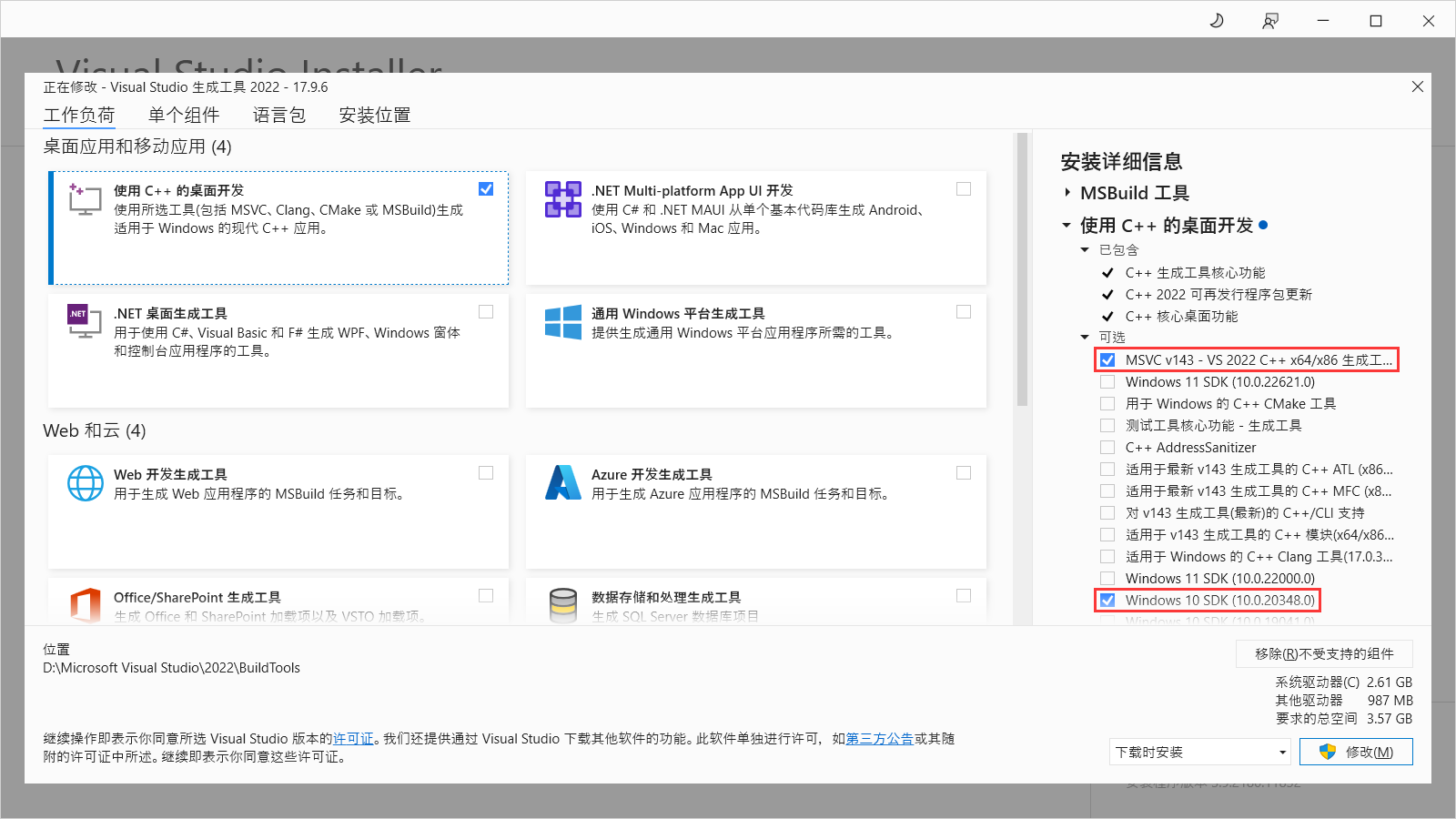
安装完成后,运行开始菜单中的 “x64 Native Tools Command Prompt for VS 2022”,执行以下编译命令(将环境变量%PYTHON_HOME%替换为Python安装目录):
1
2
3
cl /c palindrome.c
cl /c /I%PYTHON_HOME%\include palindrome_wrap.c
cl /LD palindrome.obj palindrome_wrap.obj /link /LIBPATH:%PYTHON_HOME%\libs /OUT:_palindrome.pyd
之后将得到共享库_palindrome.pyd,使用方法与Linux相同。
参考:
- How to Create a pyd File in Python
- Compiling C extension modules on Windows
- Use the Microsoft C++ toolset from the command line
穿越编译器“魔法森林”的捷径
如果你觉得编译过程晦涩难懂,这很正常,很多人都这样认为。如果自动化编译过程(例如使用Makefile),用户就需要进行配置:指定Python安装位置、使用的编译器和选项等。通过使用setuptools可以优雅地避免这一问题。实际上,它直接支持SWIG。你甚至不需要手动运行,只需编写代码和接口文件,再运行安装脚本。详见18.3节。
17.3.2 自行改造
SWIG在幕后做了很多工作,但并非都是绝对必要的。如果愿意,也可以自己编写包装代码,或者在C语言代码中直接使用Python C API。
Python C API有专门的参考手册Python/C API Reference Manual。标准库参考手册Extending and Embedding the Python Interpreter也做了介绍。这里的介绍将更简短。
引用计数
在Python中,内存管理是自动完成的:你只管创建对象,当你不再使用时它们就会消失。在C语言中,情况并非如此。你必须显式地释放(deallocate)不再使用的对象(或内存块),否则程序占用的内存将越来越多,这叫做内存泄漏(memory leak)。
编写Python扩展时,可以使用Python在底层使用的内存管理工具,其中之一就是引用计数(reference counting)。其基本思想是:一个对象只要被某部分代码引用,就不应该将其释放。然而,一旦对象的引用数变为0,数目就不会再增加,因为没有代码能创建该对象的新引用。此时,就可以安全地释放它。引用计数自动完成这个过程。你需要遵守一系列规则,在各种情况下增加或减少对象的引用计数。
可以使用两个宏,Py_INCREF和Py_DECREF,分别来增加和减少对象的引用计数,详见Python文档Reference Counts。这里列出了一些要点:
- 你不能拥有(own)一个对象,但可以拥有指向它的引用。对象的引用计数就是指向它的引用的数量。
- 如果你拥有一个引用,就要负责在不再需要它时调用
Py_DECREF。 - 如果你暂时借用了一个引用,就不应该在使用完后调用
Py_DECREF,这是拥有者的职责。 - 可以通过调用
Py_INCREF将借来的引用变成自己拥有的,这将创建一个新引用。 - 通过参数接收到对象时,要转移引用的所有权(例如将其存储起来)还是仅仅借用完全由你决定,但应该清楚地说明。
再谈垃圾收集
引用计数是垃圾收集(garbage collection)的一种方式,其中术语“垃圾”指的是程序不再使用的对象。Python还使用一种更复杂的算法来检测循环引用(即两个对象相互引用对方,但没有其他对象引用它们)。在Python程序中,可以通过gc模块来访问Python垃圾收集器。
扩展框架
编写Python的C语言扩展时,需要大量的模板代码。在如何组织代码方面有很大的选择空间,这里只介绍一种可行的方式。
首先要牢记的是,头文件Python.h必须先包含,在其他标准头文件之前。这是因为在有些平台上,Python.h可能会做些重新定义,其他头文件需要使用。因此,将以下内容作为第一行代码:
1
#include <Python.h>
你的函数叫什么名字都可以,但应该是静态的,返回一个PyObject指针,并接受两个PyObject指针参数。按照惯例,这两个参数叫做self和args(self是当前对象或NULL,args是参数的元组)。换句话说,函数应该类似于这样:
1
2
3
4
5
6
7
static PyObject *somename(PyObject *self, PyObject *args) {
PyObject *result;
/* Do something here, including allocating result. */
Py_INCREF(result); /* Only if needed! */
return result;
}
参数self仅在绑定方法中使用,在普通函数中为NULL指针。
注意,可能并不需要调用Py_INCREF。如果对象是在函数中创建的(例如使用Py_BuildValue),函数已经拥有了指向它的引用,因此直接返回它即可。然而,如果要从函数返回None,应该使用已存在的对象Py_None。在这种情况下,函数并不拥有指向Py_None的引用,因此应该在返回前调用Py_INCREF(Py_None)。
参数args包含传递给函数的所有参数(除了self)。为了提取对象,使用函数PyArg_ParseTuple(用于位置参数)和PyArg_ParseTupleAndKeywords(用于位置参数和关键字参数)。
函数PyArg_ParseTuple的签名如下:
1
int PyArg_ParseTuple(PyObject *args, char *format, ...);
格式字符串描述了期望的参数,在最后提供要存储参数值的变量的地址。返回值是一个布尔值,如果为真则表示一切顺利,否则表示发生了错误,此时只需返回NULL。因此,如果预期没有任何参数(格式字符串为空),下面是一种很有用的参数处理方式:
1
2
3
if (!PyArg_ParseTuple(args, "")) {
return NULL;
}
格式字符串可以用"s"表示一个字符串,"i"表示一个整数,"o"表示一个Python对象,并且可以组合,例如"iis"表示两个整数和一个字符串。完整参考见Parsing arguments。
回文
言归正传,代码清单17-6是手工编写的Python C API版本的palindrome模块。
大部分内容都是样板代码(boilerplate)。可以将palindrome替换为模块名,将is_palindrome替换为函数名。如果还有其他函数,只需在数组PyMethodDef中列出。需要注意的一点是,初始化函数名必须是PyInit_module,其中module是模块名。
现在来编译吧!可以像17.3.1节那样做:
1
gcc -fPIC -shared -I$PYTHON_HOME/include/python3.11 palindrome2.c -o palindrome.so
在macOS中:
1
gcc -dynamiclib -I$PYTHON_HOME/include/python3.11 palindrome2.c -o palindrome.so -Wl,-undefined,dynamic_lookup
在Windows中:
1
cl /LD /I%PYTHON_HOME%\include palindrome2.c /link /LIBPATH:%PYTHON_HOME%\libs /OUT:palindrome.pyd
这将生成一个名为palindrome.so(或.pyd)的文件。只要将它放在PYTHONPATH包含的目录(例如当前目录)中,就可以开始使用了:
1
2
3
4
5
>>> from palindrome import is_palindrome
>>> is_palindrome('foobar')
0
>>> is_palindrome('deified')
1