《Python基础教程》笔记 第20章 项目1:即时标记
本章介绍如何使用Python杰出的文本处理功能将纯文本文件转换为用HTML或XML等语言标记(mark up)的文件。如果需要HTML简介,网上的相关教程数不胜数,例如Getting started with HTML。
20.1 问题描述
你希望给纯文本文件添加格式。假设你要将一个文件用作网页,而给你文件的人嫌麻烦,没有以HTML格式编写它。你不想手动添加需要的所有标签,而是想编写一个程序来自动完成。
基本上,你的任务是对各种文本元素(例如标题、强调等)进行分类,再清晰地标记它们。就这里的问题而言,你将给文本添加HTML标签,得到可以作为网页在浏览器中显示的文档(例如*World Wide Spam*转换为<em>World Wide Spam</em>)。创建了基本引擎后,完全可以添加其他类型的标记(例如各种形式的XML或LATEX代码)。对文本文件进分析后,你甚至可以执行其他任务,例如提取所有的标题以制作目录。
开始编写原型之前,先来定义一些目标。
- 不应该要求输入包含人工编码或标签。
- 应该能够处理不同的文本块(例如标题、段落和列表项)以及内嵌文本(例如强调和超链接)。
- 虽然这个实现使用的是HTML,但应该很容易扩展到其他标记语言。
20.2 有用的工具
编写这个程序可能需要的工具:
- 肯定需要读写文件(见第11章),至少要读取标准输入(
sys.stdin)、使用print()输出。 - 可能需要迭代输入行(见第11章)。
- 需要使用字符串方法(见第3章)。
- 可能需要使用生成器(见第9章)。
- 可能需要
re模块(见第10章)。
20.3 准备工作
开始编码前,还需要有评估进展的方法,因此需要一个测试套件。就这个项目而言,一个测试就足够了:一个测试文档。代码清单20-1是要标记的纯文本文件。
要对实现进行测试,只需将这个文档作为输入,并在Web浏览器中查看结果(或直接检查添加的标签)即可。
20.4 初次实现
首先要做的事情之一是将文本分成段落。从代码清单20-1可知,段落之间由一个或多个空行分隔。比段落(paragraph)更准确的说法是块(block),因为块也可以指标题和列表项。
20.4.1 找出文本块
找出这些块的一种简单的方法是,收集遇到的所有行,直到遇到空行,然后返回收集的行,这就是一个块。然后重复这样的操作。不需要收集空行,因此不会返回空的块(在遇到多个空行时)。另外,必须确保文件的最后一行是空行,否则无法确定最后一个块到哪里结束。
代码清单20-2展示了这个方法的一种实现。
生成器lines()在文件末尾添加一个空行,生成器blocks()实现了前面描述的方法。
20.4.2 添加标记
下面创建简单的标记脚本。程序的基本步骤如下:
- 打印一些开始标记(例如
<html>)。 - 对于每个块,在段落标签(
<p>)内打印它。 - 打印一些结束标记(例如
</html>)。
这里将第一个块放在一级标题标签<h1>而不是段落标签内。另外,将用星号括起来的文本替换为强调文本(使用<em>标签)。有了blocks()函数并使用re.sub(),代码会非常简单,如代码清单20-3所示。
可以像这样使用示例输入文件执行这个程序:
1
$ python simple_markup.py < test_input.txt > test_output.html
之后,文件test_output.html将包含生成的HTML代码,下图是在Web浏览器中的效果。
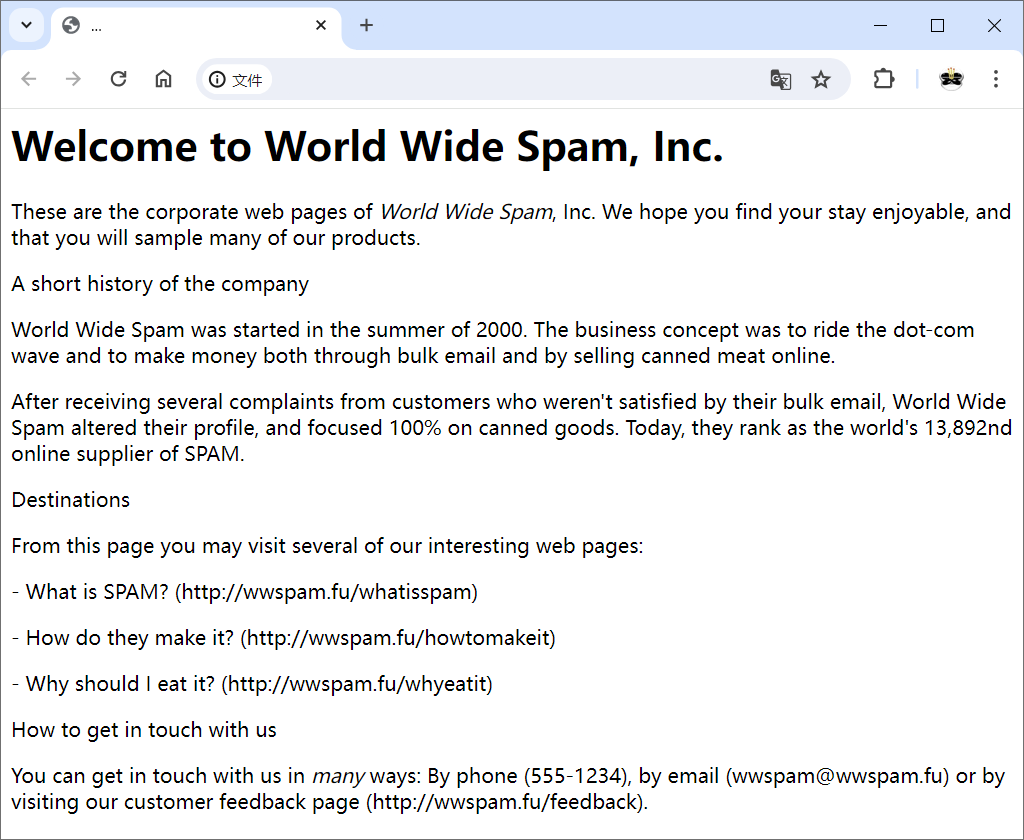
这个原型虽然不是很出色,但确实完成了一些重要的任务:将文本分成可独立处理的块,并依次对每个块应用一个过滤器(re.sub())。这看起来是一个好方法,能用在最终的程序中。
要扩展这个原型,可能要在for循环中添加检查,以确定当前块是否是标题、列表项或其他,为此需要添加更多的正则表达式。代码可能很快就会变得很乱。更重要的是,让程序输出除HTML以外的格式将会很难,而这个项目的目标之一就是能够容易地添加其他输出格式。这里假设你要重构这个程序,采用稍微不同的结构。
20.5 再次实现
从初次实现中学习到:为了提高可扩展性,需要提高程序的模块化程度(将功能分解为独立的组件)。实现模块化的方法之一是采用面向对象设计(见第7章)。你需要找出一些抽象,让程序在变得复杂的同时也易于管理。首先列出一些可能的组件。
- 解析器(parser):读取文本并管理其他类的对象。
- 规则(rule):为每种类型的块制定一条规则。规则能够检测适用的块类型,并进行相应的格式化。
- 过滤器(filter):使用过滤器来包装处理内嵌元素的正则表达式。
- 处理器(handler):供解析器用来生成输出。每个处理器生成一种不同类型的标记。
20.5.1 处理器
处理器负责生成最终的标记文本,并接受来自解析器的具体指令。假设它对于每种类型的块都提供两个方法:一个用于开始块,一个用于结束块。例如,方法start_paragraph()和end_paragraph()用于处理段落。对于HTML,可以像下面这样实现:
1
2
3
4
5
class HTMLRenderer:
def start_paragraph(self):
print('<p>')
def end_paragraph(self):
print('</p>')
当然,对于其他类型的块需要提供类似的方法。这看起来足够灵活了:如果要使用其他类型的标记,只需再创建一个处理器(或渲染器)并实现开始和结束方法。
如何处理正则表达式呢?re.sub()函数的第二个参数可以接受一个函数(替换函数)(见10.3.8节“替换中的组号和函数”)。这个函数使用Match对象调用,其返回值被插入到文本中。这与前面讨论的处理器理念很匹配——只需让处理器实现替换函数。例如,可以像这样处理强调文本:
1
2
def sub_emphasis(self, match):
return '<em>{}</em>'.format(match.group(1))
除了start、end和sub方法外,还有一个feed()方法,用于向处理器提供实际文本。在简单的HTML渲染器中,只需像这样实现这个方法:
1
2
def feed(self, data):
print(data)
20.5.2 处理器超类
为了提高灵活性,添加一个Handler类,它将是所有处理器的超类,负责处理一些管理性细节。有些情况下,不通过全名(例如start_paragraph)调用方法,而是使字符串(例如'paragraph')表示块类型,并将其提供给处理器会很有用。为此,可以添加一些通用方法,例如start(type)、end(type)和sub(type)。另外,还可以让这些方法检查是否真正实现了相应的方法(例如,start('paragraph')对应start_paragraph()),如果没有实现就什么都不做。Handler类的实现如下(handlers模块的实现如代码清单20-4所示)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
class Handler:
def callback(self, prefix, name, *args):
method = getattr(self, prefix + name, None)
if callable(method): return method(*args)
def start(self, name):
self.callback('start_', name)
def end(self, name):
self.callback('end_', name)
def sub(self, name):
def substitution(match):
result = self.callback('sub_', name, match)
if result is None: match.group(0)
return result
return substitution
这段代码中有几点需要解释一下:
callback()方法负责根据指定的前缀(例如'start_')和名称(例如'paragraph')找到正确的方法(例如start_paragraph())。这是通过使用getattr()实现的,如果返回的对象是可调用的(即找到了对应的方法),就使用额外提供的参数调用它。例如,handler.callback('start_', 'paragraph')将无参数调用handler.start_paragraph()。start()和end()只是分别使用前缀'start_'和'end_'调用callback()的辅助方法。sub()方法稍有不同。它不直接调用callback(),而是返回一个新的函数,这个函数将用作re.sub()的替换函数(因此它接受一个Match对象作为参数)。
下面来看一个示例。假设变量handler中有一个HTMLRenderer实例。
1
2
>>> from handlers import HTMLRenderer
>>> handler = HTMLRenderer()
调用handler.sub('emphasis')
1
2
>>> handler.sub('emphasis')
<function Handler.sub.<locals>.substitution at 0x000001B9EDD17740>
将返回一个函数substitution()。如果调用这个函数,它将调用handler.sub_emphasis()方法。
注:每次调用handler.sub()都会返回一个新的函数,即使使用相同的参数调用。
1
2
3
4
5
6
7
>>> import re
>>> substitution = handler.sub('emphasis')
>>> match = re.search(r'\*(.+?)\*', 'This *is* a test')
>>> substitution(match)
'<em>is</em>'
>>> handler.sub_emphasis(match)
'<em>is</em>'
这意味着可以在re.sub()中使用这个函数。
1
2
>>> re.sub(r'\*(.+?)\*', handler.sub('emphasis'), 'This *is* a test')
'This <em>is</em> a test'
为何不像初次实现中那样直接使用r'<em>\1</em>'呢?因为这样就只能添加em标签,而你希望处理器能够决定使用哪种标记语言。假设处理器为LaTeXRenderer,可能生成完全不同的结果。
1
2
>>> re.sub(r'\*(.+?)\*', handler.sub('emphasis'), 'This *is* a test')
'This \\emph{is} a test'
如果没有找到替换函数,就原样返回匹配的文本(match.group(0))。
1
2
>>> re.sub(r'\*\*(.+?)\*\*', handler.sub('bold'), 'This **is** a test')
'This **is** a test'
20.5.3 规则
处理器已经有了很好的可扩展性和灵活性,下面将注意力转向解析(parsing)(对原始文本进行解读)。这里将规则定义为独立的对象,而不是像初次实现中那样使用一个包含各种条件和操作的大型if语句。
规则在主程序(分析器)中使用,必须具备如下功能:
- 识别自己适用于哪种块(条件)
- 对块进行转换(操作)
因此每个规则对象必须包含两个方法:condition()和action()。
condition()方法只需要一个参数:待处理的块。它返回一个布尔值,表示当前规则是否适用于指定的块。
提示:对于复杂规则的解析,可能需要让规则对象访问一些状态变量(例如,标题规则需要知道当前是否是第一个块)。
action()方法也将块作为参数,但为了影响输出,还必须能够访问处理器对象。
在很多情况下,只有一条规则适用(例如,如果使用了标题规则,就不应再尝试使用段落规则)。但有时一条规则可能不会阻止其他规则的执行(例如列表规则)。因此,需要给action()方法添加一项功能:返回一个布尔值,表示是否停止对当前块的处理(这意味着规则的顺序很重要)。
标题规则的为代码如下:
1
2
3
4
5
6
7
8
9
class HeadlineRule:
def condition(self, block):
if the block fits the definition of a headline, return True;
otherwise, return False.
def action(self, block, handler):
call methods such as handler.start('headline'), handler.feed(block) and
handler.end('headline').
because we don't want to attempt to use any other rules,
return True, which will end the rule processing for this block.
20.5.4 规则超类
虽然并非一定需要规则超类,但有些规则可能执行相同的操作:用合适的类型字符串调用处理器的start()、feed()和end()方法,并返回True(停止处理)。假设所有子类都有一个type属性,包含类型名称字符串,可以像下面这样实现规则超类。
1
2
3
4
5
6
class Rule:
def action(self, block, handler):
handler.start(self.type)
handler.feed(block)
handler.end(self.type)
return True
condition()方法由各个子类负责实现。rules模块的完整代码见代码清单20-5。
20.5.5 过滤器
无需为过滤器实现一个单独的类。有了Handler类的sub()方法,每个过滤器都可以用一个正则表达式和一个名称来表示。见下一节。
20.5.6 解析器
现在来到应用的核心部分:Parser类。它使用一个处理器以及一系列规则和过滤器将纯文本文件转换为标记文件(这里是HTML文件)。这个类需要哪些方法?完成准备工作的构造函数、添加规则的方法、添加过滤器的方法以及对文件进行解析的方法。
Parser类的代码如代码清单20-6所示。
构造函数将提供的处理器赋给一个属性,并初始化两个列表:一个规则列表和一个过滤器列表。add_rule()和add_filter()方法分别添加一条规则和一个过滤器。
注:add_filter()也使用了嵌套函数定义,类似于Handler.sub()。
20.5.7 创建规则和过滤器
至此已经有了所有需要的工具,但还没有创建具体的规则和过滤器。
注:“规则”用于处理各种类型的块(例如标题、列表项和段落),“过滤器”用于处理正文中的元素(例如强调、链接和邮箱),二者是相互独立的。例如,标题中可能有强调,列表项中可能有链接。
为了保持简单,我们只创建用于题目、其他标题、列表、列表项和段落的规则。下面用非正式的术语定义了这些规则:
- 标题(heading)是只包含一行、长度不超过70个字符且不以冒号结尾的块。
- 题目(title)是文档中的第一个块,前提是它是标题。
- 列表项是以连字符(-)开头的块。
- 列表从不是列表项的块和后面的列表项之间开始,在列表项和后面的不是列表项的块之间结束(即:从第一个列表项之前到最后一个列表项之后)。
这些规则是根据我对文本文档的直觉构造的,你完全可以改进这些规则。这些规则的完整源代码见代码清单20-5。
注意,列表规则的action()方法返回False,因为第一个列表项既满足列表规则,又满足列表项规则。它不对块本身进行标记,而只是标记列表的开始和结束位置(<ul>和</ul>)。
过滤器就是正则表达式。我们添加三个过滤器:强调、URL和电子邮件地址(同样,可以随意改进)。
1
2
3
\*(.+?)\*
(http://[\.a-zA-Z/]+)
([\.a-zA-Z]+@[\.a-zA-Z]+[a-zA-Z]+)
20.5.8 整合起来
现在,只需创建一个Parser对象,并添加相关的规则和过滤器。为此,创建一个Parser的子类,在构造函数中完成初始化,再使用它来解析sys.stdin。
最终的程序如代码清单20-4~20-6所示。最终程序可以像原型那样运行:
1
$ python markup.py < test_input.txt > test_output.html
使用示例文本运行这个程序的结果如下图所示。
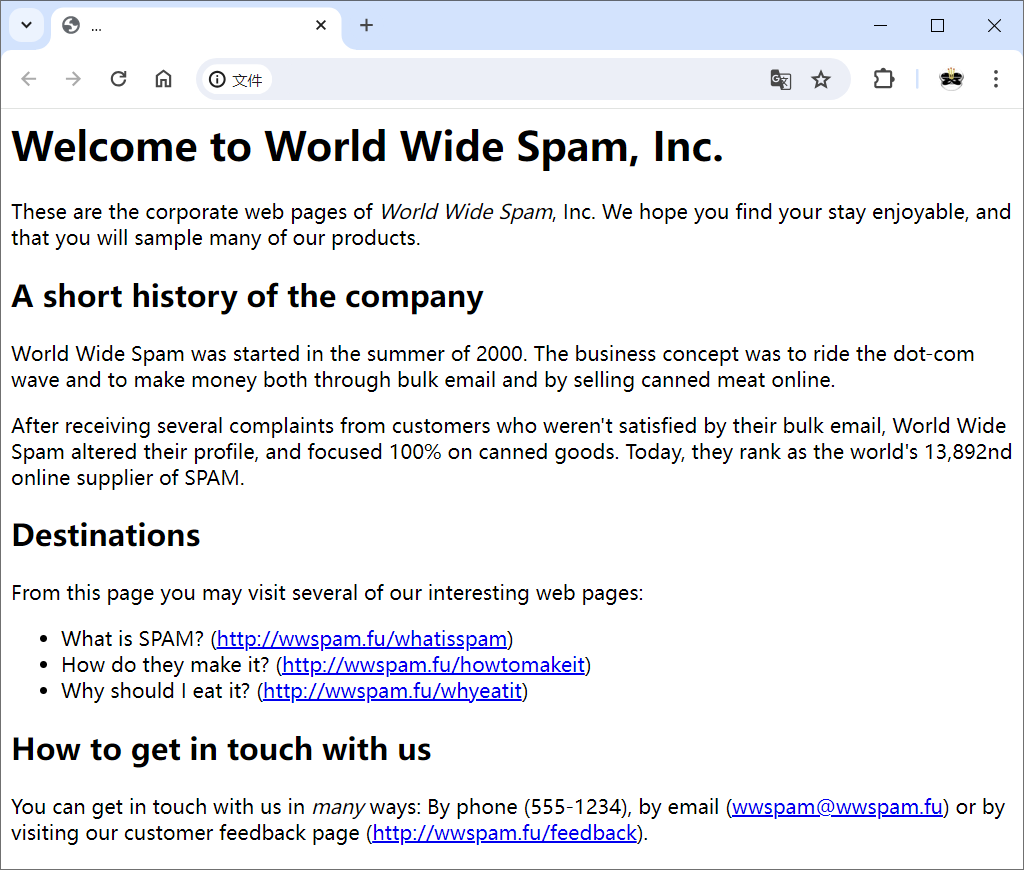
第二次实现显然比初次实现更复杂、涉及范围更广。增加的复杂性所花费的精力是值得的,因为最终的程序更灵活、可扩展性更强。要使其适配新的输入和输出格式,只需创建子类并初始化已有的类,而不是像原型那样推倒重来。
20.6 进一步探索
下面是这个程序可能的扩展:
- 增加对表格的支持。需要找出所有左对齐的单词边界并将块分割成列。
- 将全部大写的单词解释为强调。为此,需要考虑缩略语、标点、姓名和其他首字母大写的单词。
- 增加对LATEX输出格式的支持。
- 编写一个执行除标记外其他处理的处理器,例如以某种方式对文档进行分析。
- 创建一个脚本,自动将一个目录中的所有文本文件转换为HTML文件。
- 了解其他纯文本格式,例如Markdown、reStructuredText或维基百科使用的格式。