《Python基础教程》笔记 第23章 项目4:新闻汇总
互联网上充斥着各种形式的新闻源,包括报纸、视频频道、博客、播客等等。有些新闻源还提供诸如RSS或Atom feed等服务,让你使用相对简单的代码就能获取最新的新闻,而无需对网页进行解析。在这个项目中,我们将探索一种比Web更早面世的机制:网络新闻传输协议(Network News Transfer Protocol, NNTP)。我们将从一个没有任何抽象(没有函数、没有类)的原型到一个添加了重要抽象的通用系统。我们将使用能够让你与NNTP服务器交互的nntplib库,但添加其他的协议和机制应该很简单。
NNTP是一种标准网络协议,用于管理在Usenet讨论组中发布的消息。NNTP服务器组成了一个统一管理这些新闻组(newsgroup)的全球网络,通过NNTP客户端(也称为新闻阅读器(newsreader))可以发布和阅读消息。NNTP服务器组成的主网络称为Usenet。
23.1 问题描述
本项目要编写的程序是一个信息收集代理(agent),能够替你收集信息(新闻)并生成报告。在这个项目中,要做的并非仅仅是“使用urllib下载文件”,你将使用另一个网络库——nntplib,使用起来稍难些。另外,还要重构程序以支持多种新闻源和目的地,将前端和后端分离,主引擎在中间层。
最终程序的主要目标如下:
- 程序应该能够从众多不同的来源收集新闻。
- 应该很容易添加新闻源(甚至不同类型的新闻源)。
- 程序应该能够以多种不同的格式将生成的新闻报告分发到众多不同的目的地。
- 应该很容易添加目的地(甚至不同类型的目的地)。
23.2 有用的工具
在这个项目中,无需单独安装软件,但要用到一些标准库模块,包括以前没有见过的nntplib。
23.3 准备工作
要使用nntplib,你需要能够访问NNTP服务器。本章示例代码使用新闻组comp.lang.python.announce,因此要确保你的NNTP服务器有这个新闻组,或者查找你想用的其他新闻组。
注:目前(2024年6月)可用的NNTP服务器:
- freenews.netfront.net
- news.mixmin.net
- news.eternal-september.org(需要注册)
可以像下面这样测试NNTP服务器:
1
2
3
4
>>> from nntplib import NNTP
>>> server = NNTP('freenews.netfront.net')
>>> server.group('comp.lang.python.announce')[0]
'211 692 1 692 comp.lang.python.announce'
结果字符串以 “211” (意味着服务器有请求的新闻组)或 “411” (意味着服务器没有这个组)开头。
注:完整的响应码列表见RFC 3977附录C。
23.4 初次实现
首先要做的是从NNTP服务器上的新闻组下载最新的消息。为简单起见,使用print()直接将结果打印到标准输出。我们将使用单个NNTP类的对象,实例化这个类时只需指定NNTP服务器的名称。你需要对这个实例调用3个方法:
group():选择指定的新闻组,并返回一些相关信息,包括最后一条消息的编号。over():返回由编号指定的一组消息的摘要。body():返回指定消息的正文。
使用前面的服务器名称,可以像下面这样完成设置工作:
1
2
3
4
servername = 'freenews.netfront.net'
group = 'comp.lang.python.announce'
server = NNTP(servername)
howmany = 10
变量howmany指定要获取多少篇文章。然后选择新闻组:
1
resp, count, first, last, name = server.group(group)
返回值是服务器响应、消息数量、第一条和最后一条消息的编号以及新闻组的名称。我们使用last来创建要获取的文章编号的区间,起点为start = last - howmany + 1。将这两个数字传递给over(),将返回一系列表示消息的(id, overview)对。我们从overview提取主题,并使用id从服务器获取消息正文。
消息正文是以字节返回的。如果使用默认编码UTF-8进行解码,可能遇到非法字节序列(例如用\xc2\xa0表示的特殊空格)。理想的做法是提取编码信息,但为简单起见,我们直接使用Latin-1编码,它适用于ASCII字符,且遇到非ASCII字符时不会报错。打印完所有文章后,调用server.quit()。
这个简单的新闻收集代理的源代码如代码清单23-1所示。
在UNIX shell中,可以像这样运行这个程序:
1
$ python newsagent1.py | less
使用less可以每次阅读一篇文章。
注:正文内容可能不是明文,而是用Base64编码的,因此不能简单地用decode()解码,而要判断消息头Content-Transfer-Encoding指定的编码方式。article()方法返回带标头的消息,格式与HTTP消息相同(标头+空行+正文,见15.2.5节),而head()方法仅返回标头。例如:
1
2
3
4
5
6
7
Content-Type: text/plain; charset=utf-8; format=flowed
Content-Transfer-Encoding: base64
...
V2luZyBQeXRob24gSURFIDEwLjAuNCBpbXByb3ZlcyBwZXJmb3JtYW5jZSBvZiB0aGUgUHl0aG9u
IDMuMTIrIA0KZGVidWdnZXIsIGZpeGVzIGRlYnVnZ2luZyB0aGUgUHl0aG9uIFNoZWxsIHdpdGgg
...
1
2
3
>>> from base64 import b64decode
>>> b64decode(b'V2luZyBQeXRob24gSURFIDEwLjAuNCBpbXByb3ZlcyBwZXJmb3JtYW5jZSBvZiB0aGUgUHl0aG9u')
b'Wing Python IDE 10.0.4 improves performance of the Python'
23.5 再次实现
初次实现的版本能用,但很不灵活,因为只能从Usenet讨论组获取新闻。 在再次实现中,将对代码稍作重构以修复这一问题。你将把各部分代码放在类和方法中,以提高程序的结构化和抽象程度。
那么需要哪些类呢?按照第7章的建议(7.3节),浏览一下问题描述中的重要名词:信息、代理、新闻、报告、网络、新闻源、目的地、前端、后端和主引擎。这表明需要下面这些主要的类:NewsAgent、NewsItem、Source和Destination。
各种新闻源构成了前端,目的地构成了后端,而新闻代理位于中间层。
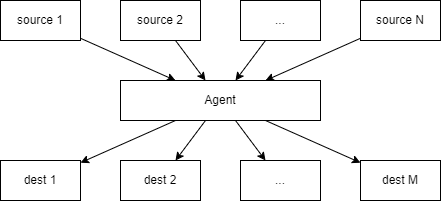
在这些类中,最简单的是NewsItem,它表示一则新闻,由标题和正文组成。
1
2
3
4
5
class NewsItem:
def __init__(self, title, body):
self.title = title
self.body = body
下面从代理本身开始。代理必须维护两个列表:源列表和目的地列表。添加源和目的地分别由add_source()和add_destination()方法完成。
1
2
3
4
5
6
7
8
9
10
11
class NewsAgent:
def __init__(self):
self.sources = []
self.destinations = []
def add_source(self, source):
self.sources.append(source)
def add_destination(self, dest):
self.destinations.append(dest)
现在唯一缺失的是将新闻从源分发到目的地的方法。每个新闻源必须有一个返回其所有新闻的方法,而每个目的地需要一个接收所有新闻的方法,分别将这两个方法命名为get_items()和receive_items()。出于灵活性考虑,只要求get_items()返回一个NewsItems的迭代器(例如生成器)。而为了让目的地更容易实现,假设receive_items()的参数是一个序列(可以多次迭代)。根据这些决策,NewsAgent的distribute()方法如下:
1
2
3
4
5
6
def distribute(self):
items = []
for source in self.sources:
items.extend(source.get_items())
for dest in self.destinations:
dest.receive_items(items)
现在,余下的工作只有创建一些源和目的地。为了进行测试,可以创建一个简单的目的地,像原型那样将新闻打印出来。
1
2
3
4
5
6
7
class PlainDestination:
def receive_items(self, items):
for item in items:
print(item.title)
print('-' * len(item.title))
print(item.body)
代码与前面相同,不同的是将这些代码封装起来了。现在它是几个候选目的地之一,而不是程序中硬编码的部分。代码清单23-2中有一个更复杂的目的地(生成HTML的HTMLDestination)。它在PlainDestination的基础上增加了一些特性:
- 生成的文本是HTML
- 将文本写入文件而不是标准输出
- 除了新闻列表外还创建了一个目录
目录是使用链接到页面相应部分的超链接创建的。为此,我们使用形如<a href="#nn">...</a>的超链接(其中nn为数字),这将链接到包含锚点(anchor)标签<a id="nn">...</a>的标题。
在设计方面,我考虑过使用超类表示源和目的地。但不同的源和目的地在行为上并没有任何共同之处,因此使用公共超类没有任何意义。只要它们实现了必要的方法(get_items()和receive_items()),NewsAgent就能接受。(这是第9章介绍的“使用协议而不是超类”的一个例子)
创建表示NNTP新闻源的NNTPSource类时,大部分代码都可以从原型中复制而来,主要不同之处如下:
- 代码封装在
get_items()方法中。变量servername、group和howmany变成了构造函数的参数。 - 增加了
decode_header()调用,用于处理标头字段(例如主题)使用的特殊编码。 - 不是直接打印每条新闻,而是生成(yield)
NewsItem对象(使get_items()变成了生成器)。
为了证明这种设计的灵活性,我们再添加一个新闻源——可以(使用正则表达式)从网页提取新闻的新闻源SimpleWebSource。构造函数参数为一个URL和两个正则表达式(一个匹配标题,另一个匹配正文)。在get_items()中,使用正则表达式方法findall()找出所有匹配的标题和正文,并使用zip()组合起来。之后迭代(title, body)列表,每对生成一个NewsItem。如你所见,添加新种类的新闻源(或目的地)并不太难。
为了让代码能够运行,我们实例化一个代理、一些新闻源和一些目的地。在run_default_setup()中实例化以下对象:
- 一个
SimpleWebSource,用于NBC News网站 - 一个
NNTPSource,用于comp.lang.python.announce - 一个
PlainDestination,它打印收集的所有新闻 - 一个
HTMLDestination,它生成新闻页面news.html
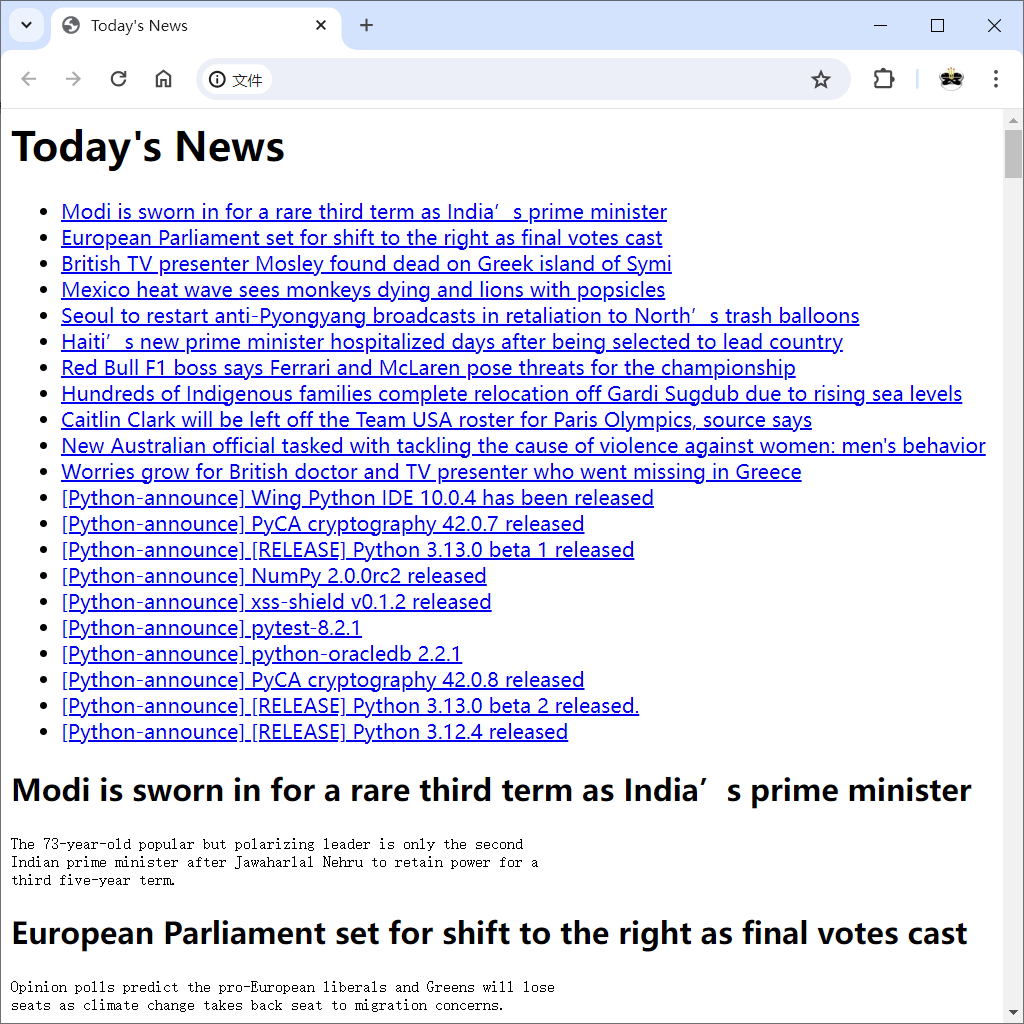
创建这些对象并将其添加到NewsAgent后,调用distribute()方法。再次实现的源代码如代码清单23-2所示。
生成的页面如下图所示。
23.6 进一步探索
由于其可扩展性,该项目值得进一步探索。以下是一些想法:
- 使用第15章讨论的屏幕抓取技术创建一个更厉害的
WebSource。 - 创建一个可以解析RSS的
RSSSource类。 - 改进
HTMLDestination生成的HTML布局。 - 创建一个页面监视器,它在指定网页发生变化时生成新闻。(只需下载页面,并与之前的页面比较。参见用于比较文件的标准库模块
filecmp。) - 创建这个新闻脚本的CGI版本(参见第15章)。
- 创建一个
EmailDestination类,它通过电子邮件将新闻发送给你。(参见用于发送电子邮件的标准库模块smtplib。) - 添加命令行开关,以指定要使用的新闻格式。(参见标准库模块
argparse。) - 向目的地提供有关新闻来源的信息,以实现更漂亮的布局。
- 尝试对新闻进行分类(可能通过搜索关键词)。
- 创建一个
XMLDestination类,它生成可供项目3(第22章)中网站生成器使用的XML文件——这样就可以创建一个新闻网站了。