《Python基础教程》笔记 第27章 项目8:使用XML-RPC进行文件共享
本章的项目是一个简单的文件共享应用,类似于BitTorrent (https://www.bittorrent.com/)等软件。
我们将使用的主要技术是XML-RPC,这是一种远程过程调用的协议。
27.1 问题描述
我们要创建一个P2P文件共享程序。文件共享意味着在运行于不同计算机上的程序之间交换文件。P2P (peer-to-peer)是描述计算机程序之间一种交互方式的术语,不同于常见的客户端-服务器(C/S)交互(客户端可以连接到服务器,但反之不然)。在P2P交互中,任何节点(peer)都可以连接到其他节点。
在构建P2P系统的过程中会遇到很多问题。为了简化问题,这个项目的系统将依次与每个邻居联系,等收到响应后再与下一个联系。
大多数P2P系统都采用巧妙的方式来组织其结构(每个节点与哪些节点相邻),以及这种结构如何随时间变化(节点连接和断开)。在这个项目中将采用非常简单的方式,但留有改进的余地。
文件共享程序必须满足以下需求:
- 每个节点必须跟踪已知节点的集合,以便向其寻求帮助。节点必须能够将自己介绍给其他节点(从而添加到其他节点的这个集合中)。
- 必须能够向节点请求文件(通过提供文件名)。如果节点有这个文件,应该将其返回;否则,应该依次向其邻居请求这个文件(而这些邻居可能转而向其邻居请求该文件)。如果某个节点有这个文件,就将其返回。
- 为了避免循环(A请求B,B又请求A),同时避免过长的请求链(A请求B请求C……请求Z),请求节点时必须提供历史记录。这个历史记录就是此前已查询过的节点列表。通过不向历史记录中已有的节点请求,可以避免循环;而通过限制历史记录的长度,可以避免请求链过长。
- 用户必须能够连接到其他节点,并将自己标识为可信任方。通过这样做,用户应该能够使用不可信任方(例如P2P网络中的其他节点)无法使用的功能,包括(通过查询)请求节点从网络中的其他节点下载文件并存储。
- 必须提供用户界面,让用户能够(作为可信任方)连接到节点并下载文件。这种界面应该很容易扩展乃至替换。
警告:正如文档指出,Python标准库的XML-RPC模块不能防范恶意构造的数据带来的风险。尽管这个项目将节点分为“可信任的”和“不可信任的”,但不应将此视为安全保障。在使用这个系统时,应该避免连接到你不信任的节点。
27.2 有用的工具
这个项目将用到很多标准库模块。
使用的主要模块是xmlrpc.client和xmlrpc.server。xmlrpc.client的用法非常简单,只需使用服务器的URL创建一个ServerProxy对象,马上就能够访问远程过程(函数)。xmlrpc.server使用起来要复杂些。
对于文件共享程序的界面,我们将使用cmd模块。为了获得(非常有限的)并行性,我们将使用threading模块。为了提取URL的组成部分,我们将使用urllib.parse模块。
其他要用到的模块包括random、string、time和os.path。参见第10章以及Python库参考手册。
27.3 准备工作
如果使用较新版本的Python,所有必需的库应该都直接可用。
要使用这个项目的软件,你并非一定要连接到网络,不过那样会更有意思。如果你有两台(或多台)相连的计算机(例如都连接到互联网),可以分别在每台计算机上运行这个软件,从而让它们互相通信。为了测试,也可以在同一台计算机上运行多个文件共享节点。
27.4 初次实现
在编写第一个原型之前,需要了解xmlrpc.server模块中的SimpleXMLRPCServer类的工作原理。这个类使用形如(servername, port)的元组来实例化。
实例化之后,可以使用register_function()方法来注册函数(供远程调用),也可以使用register_instance()来注册实例方法。准备好运行服务器后,调用serve_forever()方法(继承自TCPServer)。
可以很容易地尝试一下。启动两个交互式Python解释器,在第一个解释器中输入以下代码:
1
2
3
4
5
6
7
8
>>> from xmlrpc.server import SimpleXMLRPCServer
>>> s = SimpleXMLRPCServer(('', 4242)) # Localhost at port 4242
>>> def twice(x): # Example function
... return x * 2
...
>>> s.register_function(twice) # Add functionality to the server
<function twice at 0x0000014CA2B17920>
>>> s.serve_forever() # Start the server
执行完最后一条语句后,解释器看起来就像“挂起”了,但实际上它在等待RPC请求。切换到另一个解释器并执行如下代码:
1
2
3
4
>>> from xmlrpc.client import ServerProxy
>>> s = ServerProxy('http://localhost:4242')
>>> s.twice(2)
4
这很令人印象深刻,尤其是考虑到客户端可以运行在其他计算机上(在这种情况下,必须使用服务器的真实名称)。如你所见,要访问服务器实现的远程过程,只需使用正确的URL实例化一个ServerProxy即可。
27.4.1 实现简单的节点
Node类必须至少具有以下属性:
- 目录名:从而知道去哪里查找/存储文件。
- 密码:供其他节点将自己标识为可信任方。
- URL:可以被添加到历史记录中(例如http://localhost:4242)。
- 已知节点(URL)的集合。
Node类需要以下方法:
- 构造函数:设置4个属性。
query():请求该节点,返回文件内容。fetch():获取并存储文件。hello():将其他节点介绍给自己。
这个类的框架的伪代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
class Node:
def __init__(self, url, dirname, secret):
self.url = url
self.dirname = dirname
self.secret = secret
self.known = set()
def query(self, query):
Look for a file (possibly asking neighbors), and return its content as a string
def fetch(self, query, secret):
If the secret is correct, perform a regular query and store
the file. In other words, make the Node find the file and download it.
def hello(self, other):
Add the other Node to the known peers
XML-RPC要求所有方法都必须返回一个值,而不能返回None(除非设置服务器的构造函数参数allow_none=True)。因此,下面定义两个结果“状态码”表示成功还是失败。
1
2
OK = 1
FAIL = 2
使用register_instance()注册Node实例后,就可以远程调用其方法了。
hello()方法非常简单,只需将other添加到self.known中即可。
fetch()方法必须接受两个参数:查询(文件名)和密码(避免被其他节点随便操纵)。注意,调用fetch()将导致节点下载一个文件,因此相比于只是返回文件内容的query(),应该更严格地限制对其访问。
如果提供的密码与self.secret不同,fetch()直接返回FAIL;否则,调用query()来获得给定的查询(文件名)对应的文件。query()返回元组(code, data)。如果查询成功(code为OK),则data为包含文件内容的字符串,否则为空字符串。
在fetch()中,获取(query()返回的)code和data。如果code为FAIL,则直接返回FAIL。否则,将data写入文件(目录为self.dirname,文件名为query),并返回OK。
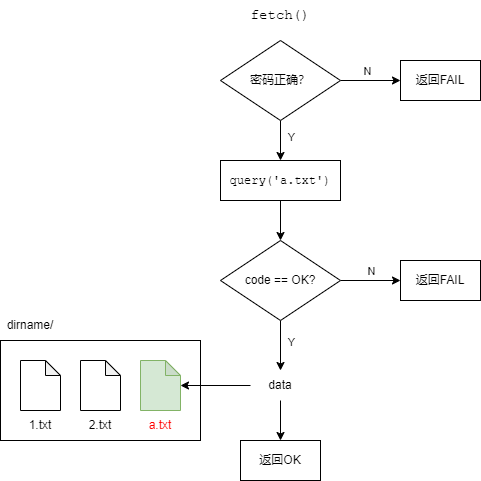
query()方法接受两个参数:查询和历史记录(包含已经查询过的节点的URL)。代码清单27-1通过创建两个辅助方法_handle()和_broadcast()抽象了query()的部分行为。注意,它们的名字以下划线开头,意味着不能通过XML-RPC访问(这是SimpleXMLRPCServer的行为,而不是XML-RPC本身的一部分)。
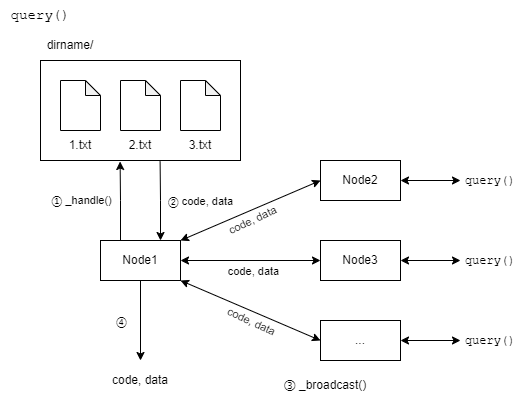
_handle()负责查询的内部处理(检查文件是否存在于当前节点、获取数据等),也返回code和data。在query()中,首先调用_handle()。如果code为OK(找到了文件),则直接返回data;否则,必须向其他已知节点寻求帮助,首先要将self.url添加到history中。
注意:更新history时,既没有使用+=运算符,也没有使用append()方法,因为它们都会原地修改列表,而你不希望修改参数的默认值。(修改可变类型的默认参数会影响后续调用,见官方教程Default Argument Values一节)
如果新的history太长,query()将返回FAIL。这里将最大长度设置为6,并保存在全局常量MAX_HISTORY_LENGTH中。
为何将MAX_HISTORY_LENGTH设置为6?
原因是网络中的任何节点最多通过6步就能到达其他任何节点。当然,这取决于网络的结构,不过也得到了有关人际关系的“六度分离”(six degrees of separation)假设的支持。参见 https://en.wikipedia.org/wiki/Six_degrees_of_separation 。
如果history不过长,则调用_broadcast()方法向所有已知节点广播查询。_broadcast()方法遍历self.known的副本。如果节点在history中则跳过,否则构造一个ServerProxy并调用其query()方法(远程调用该节点的query()方法)。如果查询成功,就将其返回值作为_broadcast()的返回值;如果发生异常(例如网络问题),则将节点的URL从self.known中删除;最后,如果到达了函数末尾(所有节点都未找到文件),则返回FAIL。
注意:不要直接遍历self.known,因为在循环中可能修改这个集合。
_start()方法创建一个SimpleXMLRPCServer,然后使用register_instance()注册self,并调用服务器的serve_forever()方法。
最后,这个模块的main()函数从命令行参数提取URL、目录和密码,创建一个Node并调用其_start()方法。
第一个原型的完整源代码如代码清单27-1所示。
27.4.2 尝试使用
下面看看使用这个程序的简单示例。
假设你要运行两个节点(在同一台机器上的不同终端)。为每个节点分别创建一个目录(例如files1和files2),将一个文件(例如test.txt)放在files2目录中。然后在一个终端中运行以下命令:
1
$ python simple_node.py http://localhost:4242 files1 secret1
注意:实际运行程序时,需要使用完整的机器名称(或IP地址)而不是localhost(否则其他节点无法连接到这个节点),也可以使用比secret1更复杂的密码。
这是第一个节点,下面创建另一个。在另一个终端中运行以下命令:
1
$ python simple_node.py http://localhost:4243 files2 secret2
这个节点使用了不同的目录、端口号和密码。现在有两个节点正在运行了。下面启动交互式Python解释器,尝试连接到其中一个节点。
1
2
3
4
5
>>> from xmlrpc.client import ServerProxy
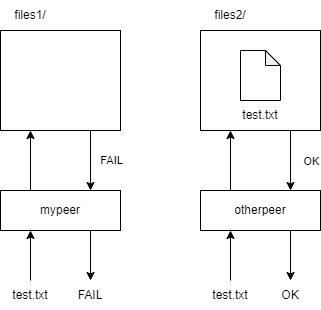
>>> mypeer = ServerProxy('http://localhost:4242') # The first peer
>>> code, data = mypeer.query('test.txt')
>>> code
2
可以看到,向第一个节点请求文件test.txt失败了。尝试用同样的方式请求第二个节点。
1
2
3
4
5
6
>>> otherpeer = ServerProxy('http://localhost:4243') # The second peer
>>> code, data = otherpeer.query('test.txt')
>>> code
1
>>> data
'This is a test\n'
这次查询成功了,因为文件test.txt可以在第二个节点的目录中找到。
下面将第二个节点介绍给第一个节点。
1
2
>>> mypeer.hello('http://localhost:4243') # Introducing otherpeer to mypeer
1
现在第一个节点知道了第二个节点的URL,因此可以向其寻求帮助。再次查询第一个节点,这次查询成功了。
1
2
>>> mypeer.query('test.txt')
[1, 'This is a test\n']
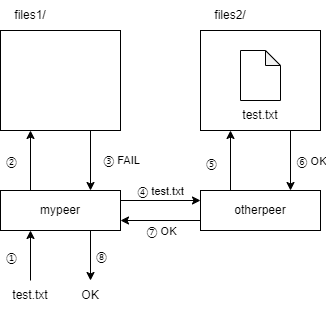
最后,让第一个节点从第二个节点那里下载并存储文件。
1
2
>>> mypeer.fetch('test.txt', 'secret1')
1
返回值1表示成功。如果查看目录files1,应该会看到文件test.txt奇迹般地出现了。
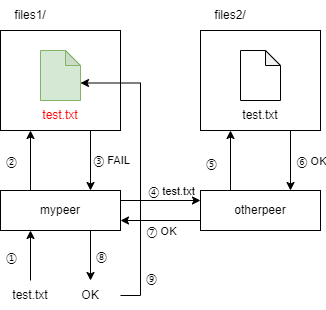
可以启动多个节点(如果愿意,也可以在不同的机器上),并将每个节点介绍给其他节点。
27.5 再次实现
初次实现存在很多缺陷和不足,这里只列出几个比较重要的:
- 如果停止并重启一个节点,可能会出现端口号被占用的错误信息。
- 提供对用户更友好的界面,而不是在交互式Python解释器中使用
xmlrpc.client。 - 返回码不方便。更自然、更符合Python风格的解决方案是使用自定义异常。
- 节点没有检查它返回的文件是否真的在文件目录中。通过使用诸如
'../somesecretfile.txt'这样的路径,图谋不轨的黑客就能非法访问其他任何文件。
第一个问题很好解决,只需将SimpleXMLRPCServer的allow_reuse_address属性设置为True即可(好像本来就是True)。其他问题要复杂些,将在以下几节中讨论。
27.5.1 创建客户端界面
客户端界面使用cmd模块中的Cmd类实现。简单来说,可以继承Cmd来创建一个命令行界面,并为每个希望处理的命令foo实现一个名为do_foo()的方法。这个方法将命令行余下的内容作为其唯一的参数(字符串)。例如,如果在命令行界面输入 “say hello” ,将调用do_say('hello')。Cmd子类的提示符(例如>)取决于prompt属性。
这里的界面将只实现命令fetch(下载文件)和exit(退出程序)。fetch命令调用服务器的fetch()方法,如果文件未找到则打印一条错误消息。exit命令打印一个空行(只是出于美观考虑)并调用sys.exit()。
Client(Cmd子类)的构造函数需要做什么呢?你希望每个客户端都关联一个自己的节点。为此,可以创建一个Node对象并调用其_start()方法,但这样客户端在_start()方法返回前什么都做不了,这导致客户端毫无用处(因为_start()调用的serve_forever()是一个无限循环)。为了解决这个问题,可以在一个独立的线程中启动Node。一般来说,使用线程会涉及很多保护和同步(使用锁)工作。然而,因为Client只通过XML-RPC与其Node交互,因此无需关心这一问题。要在独立的线程中运行_start()方法,只需将下面的代码放在程序的某个合适位置:
1
2
3
4
from threading import Thread
n = Node(url, dirname, self.secret)
t = Thread(target=n._start)
t.start()
警告:修改这个项目的代码时务必小心。Client开始直接与Node交互(或反过来)后,就很容易遇到与线程相关的问题。修改代码前确保你完全理解线程。
为了确保服务器在使用XML-RPC连接前已完全启动,启动后可以使用time.sleep()等待一段时间。
然后,遍历一个包含URL的文件,并使用hello()方法将这些节点介绍给服务器。
你不用自己去设计密码,可以使用辅助函数random_string()(见代码清单27-3)生成一个由Client和Node共享的随机密码字符串。
27.5.2 引发异常
你可以不用返回码指示成功或失败,而是假设会成功,并在失败时引发异常。在XML-RPC中,异常(或故障)是使用数字标识的。
在这个项目中,我们(随意地)选择了数字100和200,分别表示普通的失败(请求未被处理)和请求被拒绝(拒绝访问)。
1
2
3
4
5
6
7
8
9
10
UNHANDLED = 100
ACCESS_DENIED = 200
class UnhandledQuery(Fault):
def __init__(self, message="Couldn't handle the query"):
super().__init__(UNHANDLED, message)
class AccessDenied(Fault):
def __init__(self, message='Access denied'):
super().__init__(ACCESS_DENIED, message)
这些异常是xmlrpc.client.Fault的子类。当它们在服务器被引发时,将使用相同的faultCode传递到客户端。如果在服务器中引发了普通异常(例如IOException),仍然会创建Fault类的实例,因此你不能在服务器中随意地使用异常。
注:
UnhandledQuery表示查询的文件不存在:在_handle()中引发表示当前节点未找到,在_broadcast()中引发表示所有已知节点都未找到。AccessDenied表示密码错误或文件名“越界”。
从代码清单27-3可知,服务器的逻辑基本上与原来一样,但不再使用if语句来检查返回码,而是使用了异常。(由于你只能使用Fault对象,因此需要检查faultCode。)
27.5.3 验证文件名
需要处理的最后一个问题是,检查指定的文件名是否位于指定的目录中。为了保持平台独立(在Windows、UNIX和macOS中都适用),应该使用os.path模块。
这里采用的简单方法是,创建由目录名和文件名组成的绝对路径(例如,将'/foo/bar/../baz'转换为'/foo/baz'),将目录名与空文件名连接起来以确保它以文件分隔符(例如'/')结尾,然后检查绝对文件名是否以绝对目录名开头。如果是,就说明文件在目录中。
注:例如,假设当前工作目录是/path/to/project
1
2
3
4
5
6
7
dir='files1' -> abspath(dir)='/path/to/project/files1'
query='test.txt' -> name=join(dir,query)='files1/test.txt'
-> abspath(name)='/path/to/project/files1/test.txt' -> OK
query='../secret.txt' -> name=join(dir,query)='files1/../secret.txt'
-> abspath(name)='/path/to/project/secret.txt' -> AccessDenied
再次实现的完整源代码如代码清单27-2和27-3所示。
27.5.4 尝试使用
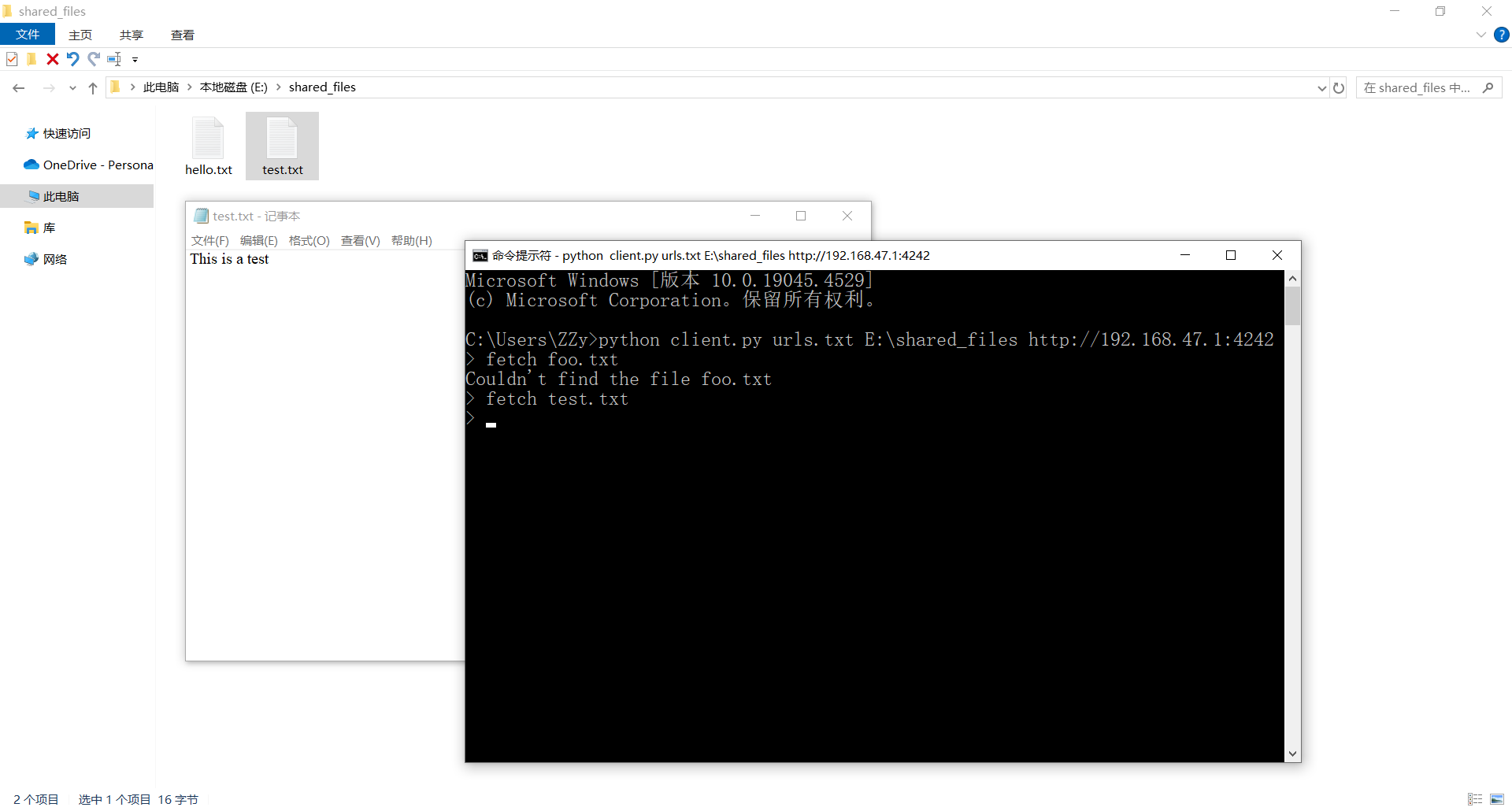
下面来看看如何使用这个程序。首先像下面这样启动它:
1
$ python client.py urls.txt directory http://servername.com:4242
文件urls.txt应该包含所有已知节点的URL,每行一个。第二个参数指定包含要共享的文件的目录(也是新文件的下载位置)。最后一个参数是节点的URL。运行这个命令,将出现提示符>。
通过(在同一台机器的不同端口或不同机器上)启动几个相互认识的节点(只要将它们的URL都放在URL文件中),可以尝试像第一个原型那样使用这个程序。
尝试获取文件:
1
2
3
4
> fetch foo.txt
Couldn't find the file foo.txt
> fetch test.txt
>
输入exit命令退出程序。
27.6 进一步探索
你可能会想出多种方式来改进和扩展本章介绍的系统。下面是一些建议:
- 添加缓存功能。在节点通过调用
query()来传递文件时,可以同时存储该文件。这样,下次有人请求这个文件时就可以更快地响应。可以设置缓存的最大容量,删除旧文件等等。 - 使用线程化(异步)服务器(有点难)。这样,可以向多个节点寻求帮助而无需等待回复,它们可以在之后通过调用
reply()方法来回应。 - 支持更高级的查询,例如查询文本文件的内容。
- 更广泛地使用
hello()方法。当(通过调用hello())发现新节点时,可以将其介绍给所有已知节点。或许你还能想到更巧妙的发现新节点的方式。 - 深入研究用于分布式系统的表述性状态转移(representational state transfer, REST)思想。REST可用于替代XML-RPC等Web服务技术。(参见 https://en.wikipedia.org/wiki/REST )
- 使用
xmlrpc.client.Binary来包装文件,从而更安全地传输非文本文件。 - 阅读
SimpleXMLRPCServer的代码。研究DocXMLRPCServer类以及xmlrpc.client中的多调用(MultiCall)扩展。