【论文笔记】R-HGNN
Heterogeneous Graph Representation Learning with Relation Awareness
2021
论文链接:https://arxiv.org/pdf/2105.11122
官方代码:https://github.com/yule-BUAA/R-HGNN/
个人实现:https://github.com/ZZy979/pytorch-tutorial/tree/master/gnn/rhgnn
1.引言
在异构图中,不同类型的关系能够反映顶点不同的特性
因此,学习特定于关系的(关系感知的,relation-aware)顶点表示是至关重要的
现有方法主要分为三类:
- GNN: GCN, GraphSAGE, GAT→用于同构图
- 设计专门的GNN来学习异构图的顶点表示:HAN, HetGNN, HetSANN, HGT→仅关注顶点表示,没有研究关系的语义
- 建模关系属性:R-GCN, RSHN, RHINE, GATNE→由于在处理不同类型的顶点特征上的简单性,无法很好地应用于异构图
该论文提出的关系感知异构图神经网络(R-HGNN)不仅能够根据不同类型的关系学习细粒度的顶点表示,还能学习关系的语义表示
2.相关工作
。
3.预备知识
3.1 定义
- 异构图:异构图定义为一个有向图图G=(V, E),以及顶点类型映射φ: V→A和边类型映射ψ: E→R,A和R分别表示顶点类型集合和边类型集合,|A|+|R|>2
- 关系(relation):边e=(u, v)对应的关系定义为<φ(u), ψ(e), φ(v)>(可简写为ψ(e)),逆关系表示为 $<φ(v), ψ^{-1}(e), φ(u)>$
3.2 问题定义
给定一个异构图G=(V, E),异构图表示学习的目标是学习一个函数 $f: V→R^d, d≪|V|$ ,学习到的表示能够捕获顶点特征和关系信息,可用于顶点分类、顶点聚类、连接预测等多种任务
4.方法
4.1 模型框架
模型框架如图2所示
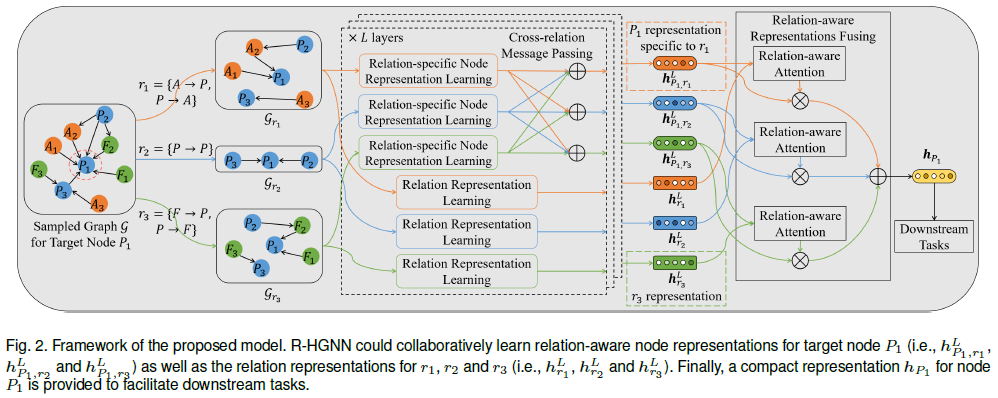
输入为目标顶点采样的图G(minibatch训练)和顶点特征矩阵,输出低维顶点表示 $h_v, v \in V$
模型由四部分组成:
- 特定关系的顶点表示学习:将输入的异构图分解为关系二分图,使用图卷积分别从每个关系子图学习不同的顶点表示
- 跨关系消息传递:建立连接,提升跨不同关系的顶点表示的交互(即关于不同关系的顶点表示再互相混合一次)
- 关系表示学习:逐层学习关系的表示,用于指导顶点表示学习过程(后续计算注意力权重)
- 关系感知的表示混合:将关系感知的顶点表示聚集为一个表示,考虑关系的语义特征
4.2 特定关系的顶点表示学习
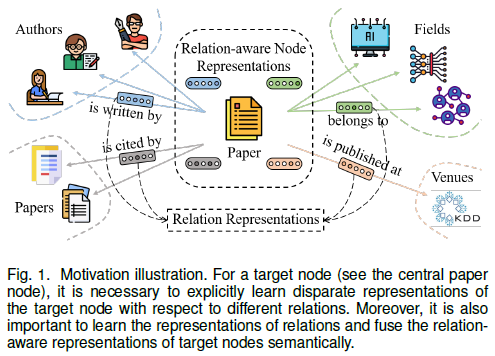
如图1所示,在异构图中,一个目标顶点通常关联多种关系
现有的方法基本都是按照顶点表示的传播机制设计,没有显式地利用关系的角色
因此,该论文提出的顶点表示学习考虑关系的特性,这意味着每个顶点都与特定于关系的表示相关联,以反映该顶点相对于对应关系的特性
首先,将异构图G分解为关系子图 $\lbrace G_r \vert r \in R\rbrace$ ,逆关系 $r^{-1}$ 也被加到图Gr中
之后,设计了一个专用的图卷积模块来从每个关系子图学习独特的顶点表示
最后,使用加权残差连接来组合目标顶点特征和聚集的邻居信息
特定关系的卷积
每个关系子图上的卷积过程如图3所示
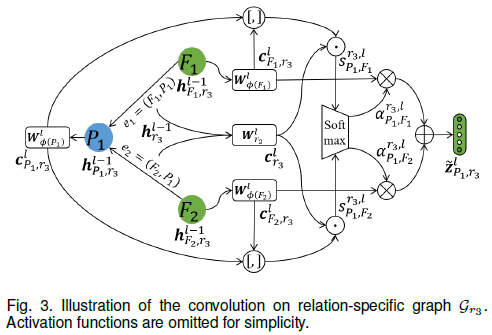
首先通过顶点类型和关系类型特定的变换矩阵将源顶点u、目标顶点v和关系ψ(e)映射到各自的隐含空间
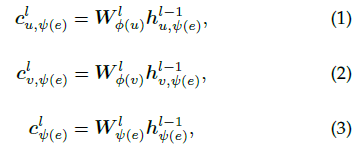
其中 $h_{u,\psi(e)}^{l−1},h_{v,\psi(e)}^{l−1},h_{\psi(e)}^{l−1}$ 分别是第l-1层源顶点u、目标顶点v关于关系ψ(e)的表示和关系ψ(e)本身的表示, $h_{u,\psi(e)}^0,h_{v,\psi(e)}^0,h_{\psi(e)}^0$ 分别设置为 $x_u, x_v, x_{\psi(e)}$ ,输入顶点特征 $x_u$ 和 $x_v$ 通常由图给出, $x_{\psi(e)}$ 表示为one-hot编码,即关系类型对应的分量为1
之后计算源顶点u对目标顶点v的归一化的重要性,并聚集顶点v在关系ψ(e)下的邻居信息
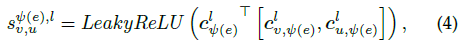
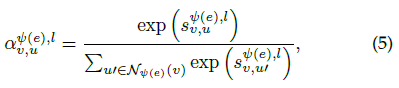
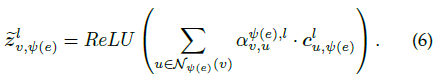
加权残差连接
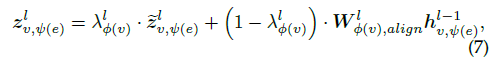
4.3 跨关系消息传递
通过特定关系的顶点表示学习,能够获取目标顶点特定于关系类型的多个表示
事实上,与目标顶点交互的不同关系之间通常也相互关联,因此有必要跨越不同关系传播消息,从而提供包含更多信息的顶点表示
简单的池化操作无法区分关于不同关系的顶点表示,因此该论文提出建立顶点表示的连接来提升跨关系的消息传递并自动区分关系的重要性
令R(v)表示顶点v关联的关系集合,给定已学习的顶点v关于每个关系的表示,即 $\lbrace z_{v,r}^l \vert r \in R(v)\rbrace$ ,关系ψ(e)和R(v)中的关系之间的消息传递实现方式为
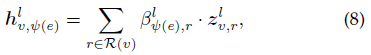
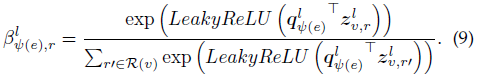
其中 $q_{\psi(e)}^l$ 是第l层特定于关系ψ(e)的可学习注意力向量,用于控制关系ψ(e)和R(v)中关系之间的信息流, $\beta_{\psi(e),r}^l$ 表示在第l层关系r和关系ψ(e)之间的相关性
4.4 关系表示学习
该论文的方法还建立在关系的语义特性的基础上,这在现有方法中很少研究
尽管HAN, R-GCN, HGT等现有方法也设计了特定于元路径或关系的可学习参数来捕获这种特性,但没有显式地关注关系的角色,这意味着不同关系的语义表示被忽略了
为了显式地学习关系的语义表示,该论文提出了一个用于关系表示的一般传播机制:
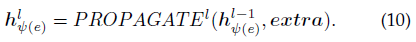
该论文的实现方式如下
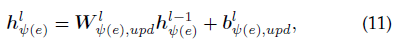
(就是一次线性变换……)
4.5 关系感知的表示混合
定义一个R-HGNN层由上述三部分组成,并堆叠L层从多跳邻居接收信息
最后一层能够提供目标顶点v的关系感知的顶点表示 $\lbrace h_{v,r}^L \vert r \in R(v)\rbrace$ 以及关系的表示 $\lbrace h_r^L \vert r \in R\rbrace$
下游任务仅需要一个顶点表示,为此可以使用简单的池化操作(例如平均或最大池化),但这样无法考虑关于不同关系的顶点表示的重要性
因此该论文设计了一个语义混合模块来将特定关系的顶点表示聚集为一个顶点表示
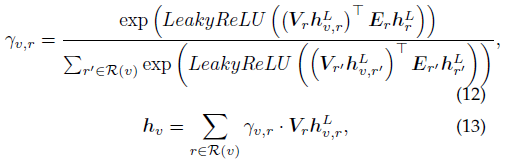
4.6 端到端学习过程
首先堆叠L个R-HGNN层来学习关系感知的顶点表示,之后使用关系感知的表示混合模块将多个表示集成为一个表示
还使用了多头注意力机制来增强训练过程的稳定性,不同注意力头的输出通过拼接操作组合起来
半监督学习策略
对于有标签的任务(例如顶点分类),R-HGNN可以通过最小化交叉熵损失来优化
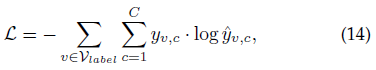
分类器可以使用单层神经网络
无监督学习策略
对于没有标签的任务(例如连接预测),R-HGNN可以通过最小化Skipgram中使用负采样的二元交叉熵损失来优化
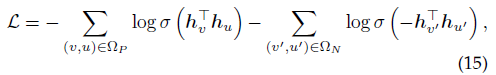
5.实验
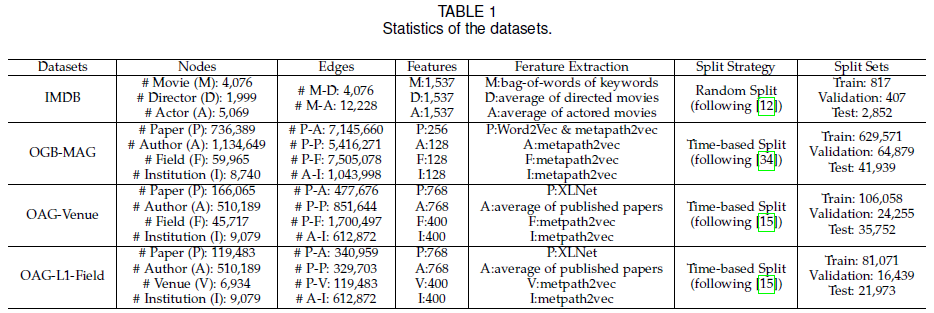
5.1 数据集
5.2 比较的方法
Baseline方法可分为四组:
- 忽略图结构的方法:MLP
- 同构图学习方法:GCN, GraphSAGE, GAT
- 图关系学习方法:R-GCN, RSHN
- 异构图学习方法:HAN, HetSANN, HGT
5.3 实验设置
对于需要元路径的模型
- IMDB: MDM, MAM
- OGB-MAG和OAG-Venue: PAP, PFP, PPP
- OAG-L1-Field: PAP, PVP, PPP
对于同构图模型,在每条元路径生成的图上分别测试,取最好结果
对于需要所有类型顶点特征的模型,增加一个映射层来对齐维数
所有模型都使用Adam优化器+cosine annealing learning rate scheduler
对于小规模和大规模数据集,分别从[32, 64, 128]和[128, 256, 512]中搜索隐含维数,关系表示的隐含维数设置为64
注意力头数为8,两层R-HGNN
对于大规模数据集,使用邻居采样策略,以mini-batch方式训练GNN 第一层的邻居采样数为10,之后逐层加1
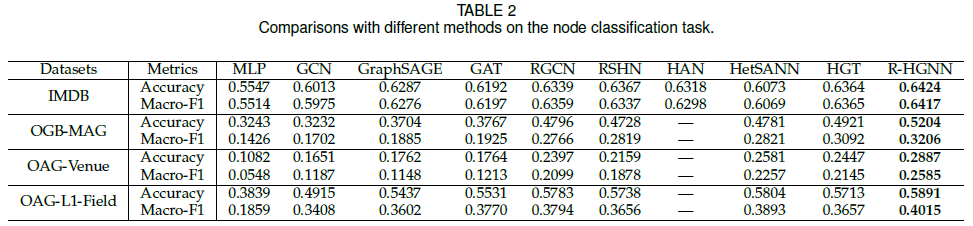
5.4 顶点分类
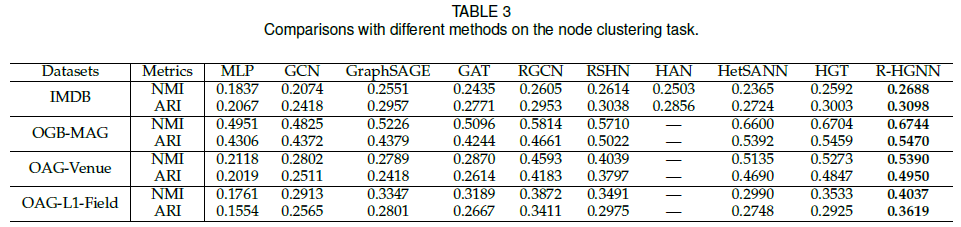
5.5 顶点聚类
5.6 顶点可视化
。
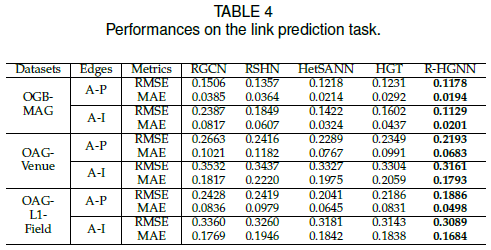
5.7 连接预测
预测A-P和A-I两种类型的边,计算顶点表示的内积作为预测概率
5.8 消融实验
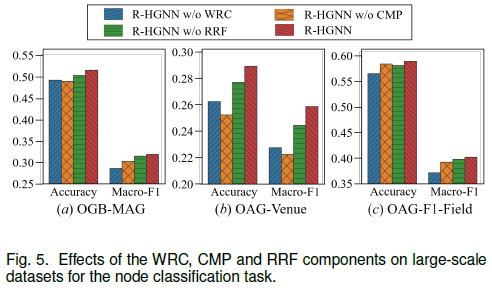
通过大规模数据集上的顶点分类任务研究加权残差连接(WRC)、跨关系消息传递(CMP)和关系感知的表示混合(RRF)三部分的作用,分别对应三种变体R-HGNN w/o WRC, R-HGNN w/o CMP和R-HGNN w/o RRF
- R-HGNN w/o WRC:移除残差连接(令(7)式中 $\lambda_{\phi(v)}^l=1$)
- R-HGNN w/o CMP:移除不同关系的顶点表示之间的连接((8)式改为 $h_{v,\psi(e)}^l=z_{v,\psi(e)}^l$)
- R-HGNN w/o RRF:将关系感知的表示混合替换为平均池化操作((13)式改为 $h_v=\frac{1}{\vert R(v) \vert}\sum_{r \in R(v)}h_{v,r}^L$)
结果如图5所示
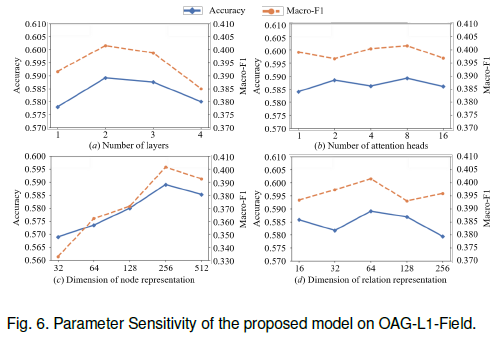
5.9 参数敏感性分析
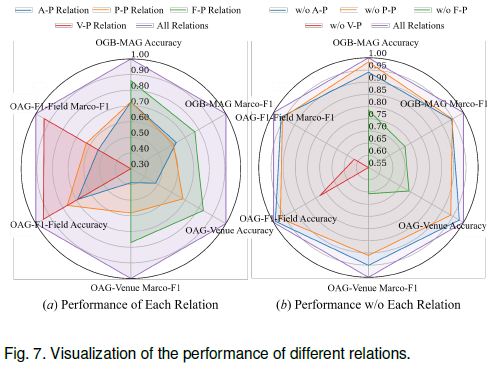
5.10 不同关系的分析