【Scrapy】选择器
【Scrapy】选择器
解析页面时最常见的任务是使用选择器从HTML中提取数据,Scrapy使用CSS选择器和XPath两种方式从HTML中提取数据
官方文档:https://docs.scrapy.org/en/latest/topics/selectors.html
使用选择器提取数据的相关方法
Response类
| 方法 | 返回值 |
|---|---|
| css(query) | SelectorList对象 |
| xpath(query) | SelectorList对象 |
SelectorList类:Selector的列表
| 属性/方法 | 返回值 |
|---|---|
| css(query) | SelectorList对象 |
| xpath(query) | SelectorList对象 |
| re(regex) | 字符串列表 |
| re_first(regex) | 字符串 |
| getall() | 字符串列表,包含每个元素的get()方法的返回值 |
| get(default=None) | 字符串,第一个元素的get()方法的返回值,如果列表为空则返回default |
| attrib | 字典,第一个元素的attrib属性,如果列表为空则返回空字典 |
Selector类:HTML/XML节点的包装类,可以提取数据或者做进一步查询
| 属性/方法 | 返回值 |
|---|---|
| css(query) | SelectorList对象 |
| xpath(query) | SelectorList对象 |
| re(regex) | 字符串列表 |
| re_first(regex) | 字符串 |
| get() | 字符串,包含该选择器匹配的内容 |
| attrib | 字典,包含该选择器匹配节点的属性 |
CSS选择器常用语法
| 选择器 | 例子 | 描述 |
|---|---|---|
element | p | 选择所有<p>元素 |
#id | div#firstname | 选择id=”firstname”的<div>元素 |
.class | p.intro | 选择所有class包含”intro”的<p>元素 |
element1,element2 | div,p | 选择所有<div>元素和所有<p>元素 |
element1 element2 | div p | 选择<div>元素内部的所有<p>元素 |
element1>element2 | div>p | 选择父元素为<div>元素的所有<p>元素 |
[attribute] | div[target] | 选择带有target属性的所有<div>元素 |
[attribute=value] | a[href=/page/2] | 选择href=”/page/2”的所有<a>元素 |
:first-child | p:first-child | 选择属于父元素的第一个子元素的每个<p>元素 |
:last-child | p:last-child | 选择属于父元素最后一个子元素的每个<p>元素 |
:nth-child(n) | p:nth-child(2) | 选择属于父元素的第2个子元素的每个<p>元素 |
::text | p::text | (Scrapy特有)选择所有<p>元素内部的文本 |
::attr(attribute) | a::attr(href) | (Scrapy特有)选择所有<a>元素的href属性值 |
使用浏览器的检查元素功能可以方便地得到所需的CSS选择器,例如:
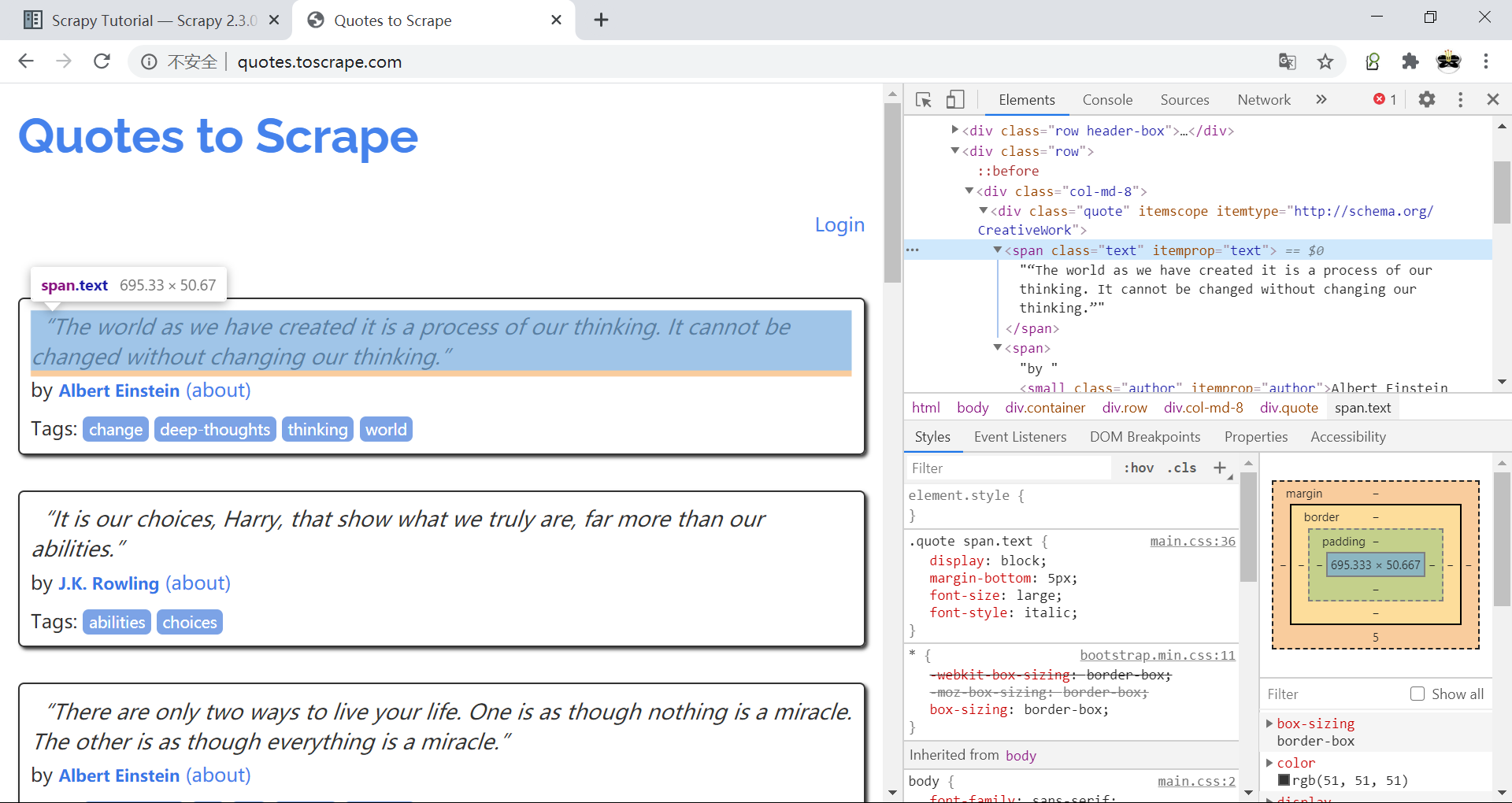
要想获得所有quote文本所在的<span>元素,只需div.quote > span.text即可
XPath常用语法
在XPath中,HTML/XML文档是被当作节点树来对待的
在XPath中有7中类型的节点:文档(根)节点、元素、属性、文本、命名空间、处理指令、注释
基本语法
| 语法 | 解释 |
|---|---|
/node | 选择根节点 |
//node | 选择所有匹配节点,不考虑在文档中的位置 |
@attr | 选择属性 |
[pred] | 谓语 |
. | 选择当前节点 |
.. | 选择当前节点的父节点 |
示例
| 表达式 | 描述 |
|---|---|
/html | 选择根节点<html> |
//p | 选择所有<p>元素,不考虑在文档中的位置 |
//@href | 选择所有href属性的值 |
//div[@id="firstname"] | 选择id=”firstname”的<div>元素 |
//p[@class="intro"] | 选择所有class=”intro”的<p>元素 |
//div/p | 选择所有<div>元素的所有直接子元素<p> |
//div//p | 选择所有<div>元素内部的所有<p>元素 |
//div/p | //div/span | 选择所有<div>元素的所有直接子元素<p>和<span> |
//div[@target] | 选择带有target属性的所有<div>元素 |
//a[@href="/page/2"] | 选择href=”/page/2”的所有<a>元素 |
//div[@id="main"]/p[1] | 选择id=”main”的<div>元素的第一个<p>子元素 |
//div[@id="main"]/p[last()] | 选择id=”main”的<div>元素的最后一个<p>子元素 |
//div[@id="main"]/p[position()< 3] | 选择id=”main”的<div>元素的前两个<p>子元素 |
//p/text() | 选择所有<p>元素内部的文本 |
//a/@href | 选择所有<a>元素的href属性值 |
This post is licensed under CC BY 4.0 by the author.