【Scrapy源码阅读】ItemMeta类
下面的代码定义了一个Item类:
1
2
3
class MyItem(scrapy.Item):
foo = scrapy.Field()
bar = scrapy.Field()
按照Scrapy官方文档的说法,使用关键字参数创建Item对象,和字典一样使用下标访问和修改字段的值,此外还有一个fields属性用于访问字段本身(由于Field类就是dict,因此foo = Field()等价于foo = {}):
1
2
3
4
5
6
7
8
9
>>> item = MyItem(foo='abc', bar=123)
>>> item
{'bar': 123, 'foo': 'abc'}
>>> item['foo']
'abc'
>>> item.fields
{'bar': {}, 'foo': {}}
>>> item.fields['foo']
{}
但是,直接通过属性访问字段则会报错:
1
2
3
4
5
6
7
8
9
>>> item.foo
Traceback (most recent call last):
File "<input>", line 1, in <module>
...
AttributeError: Use item['foo'] to get field value
>>> 'foo' in dir(item)
False
>>> 'foo' in dir(MyItem)
False
那么问题来了:MyItem类明明定义了foo和bar两个属性,为什么通过实例访问foo这个属性时会报错,并且dir(item)甚至dir(MyItem)中根本没有这个属性?foo属性是何时被删除的?fields属性又是何时被添加的?
官方文档的”Declaring fields“一节中提到了这一问题,但没有提供更多细节:
It’s important to note that the Field objects used to declare the item do not stay assigned as class attributes. Instead, they can be accessed through the Item.fields attribute.
只能从源代码入手寻找原因。能够对对象进行“改造”的地方,一种可能是构造函数,但Item类的构造函数(继承自DictItem类)所做的工作只有将关键字参数保存到_values属性:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
class DictItem(MutableMapping, BaseItem):
fields = {}
def __init__(self, *args, **kwargs):
self._values = {}
if args or kwargs: # avoid creating dict for most common case
for k, v in dict(*args, **kwargs).items():
self[k] = v
def __getitem__(self, key):
return self._values[key]
def __setitem__(self, key, value):
if key in self.fields:
self._values[key] = value
else:
raise KeyError("%s does not support field: %s" % (self.__class__.__name__, key))
另一种可能是__new__()方法,但是MyItem类的__new__()方法只能操作该类的实例,不能修改类本身的属性。因此只有一种可能——元类。
元类是类的类,一般类的元类都是type(例如5的类型是int,而int的类型是type),而Scrapy自定义了Item类的元类ItemMeta,即ItemMeta类的实例是Item类(或其子类),Item类的实例是item对象。
1
2
3
4
5
class Item(DictItem, metaclass=ItemMeta):
"""
Base class for scraped items.
...
"""
Python语言定义一个类的__new__()方法返回该类的实例,因此元类的__new__()方法返回类对象,即:
1
2
3
ItemMeta.__new__(ItemMeta, 'MyItem', ...)->MyItem
MyItem.__new__(MyItem, foo='abc', bar=123)->item
因此关键就在于ItemMeta类的__new__()方法,下面对该方法的源代码进行探究。该方法的代码如下:
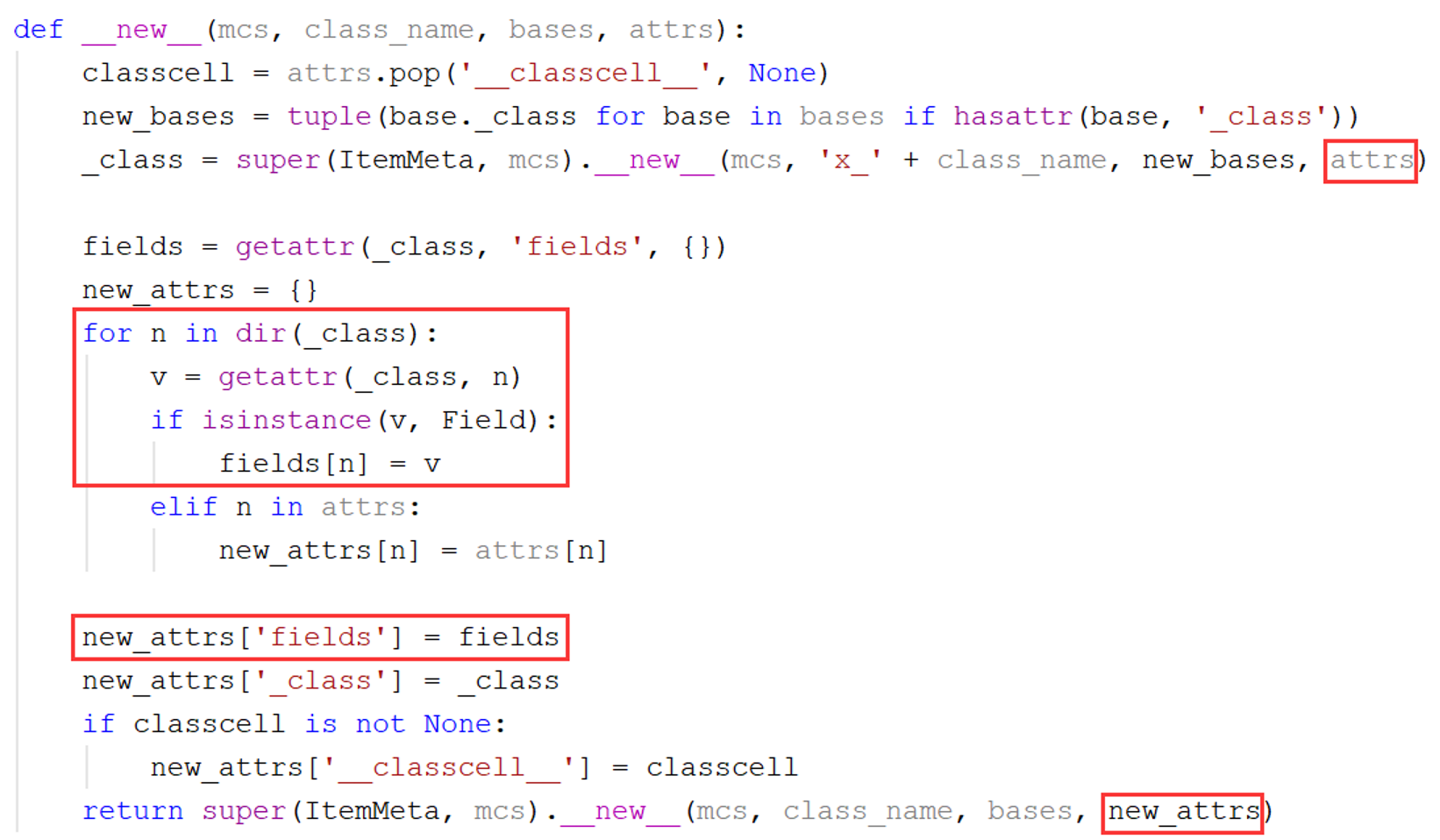
该方法的四个参数分别为要创建的类的类型mcs(这里就是ItemMeta本身,因为要创建的实例是MyItem,其类型是ItemMeta)、名称class_name(例如"Item", "MyItem"或其他Item的子类)、基类bases以及属性集合attrs(重点)。
该方法的大致逻辑是:首先使用旧属性集合attrs创建一个名为x_MyItem的临时类_class,该临时类应当是包含属性foo和bar的;之后遍历_class的所有属性,将Field类型的属性(即自定义的字段)保存在fields属性中;最后将fields放入新属性集合new_attrs,使用new_attrs创建真正的MyItem类并返回。
从以上过程中可以看出,创建真正的MyItem类时使用的属性集合new_attrs并不包含foo和bar,这就是自定义的字段只能通过item.fields['foo']访问而不能通过item.foo访问的原因。
下面通过调试验证以上猜想。在ItemMeta类的__new__()方法中设置断点,当程序执行到MyItem类的定义时就会调用该方法。
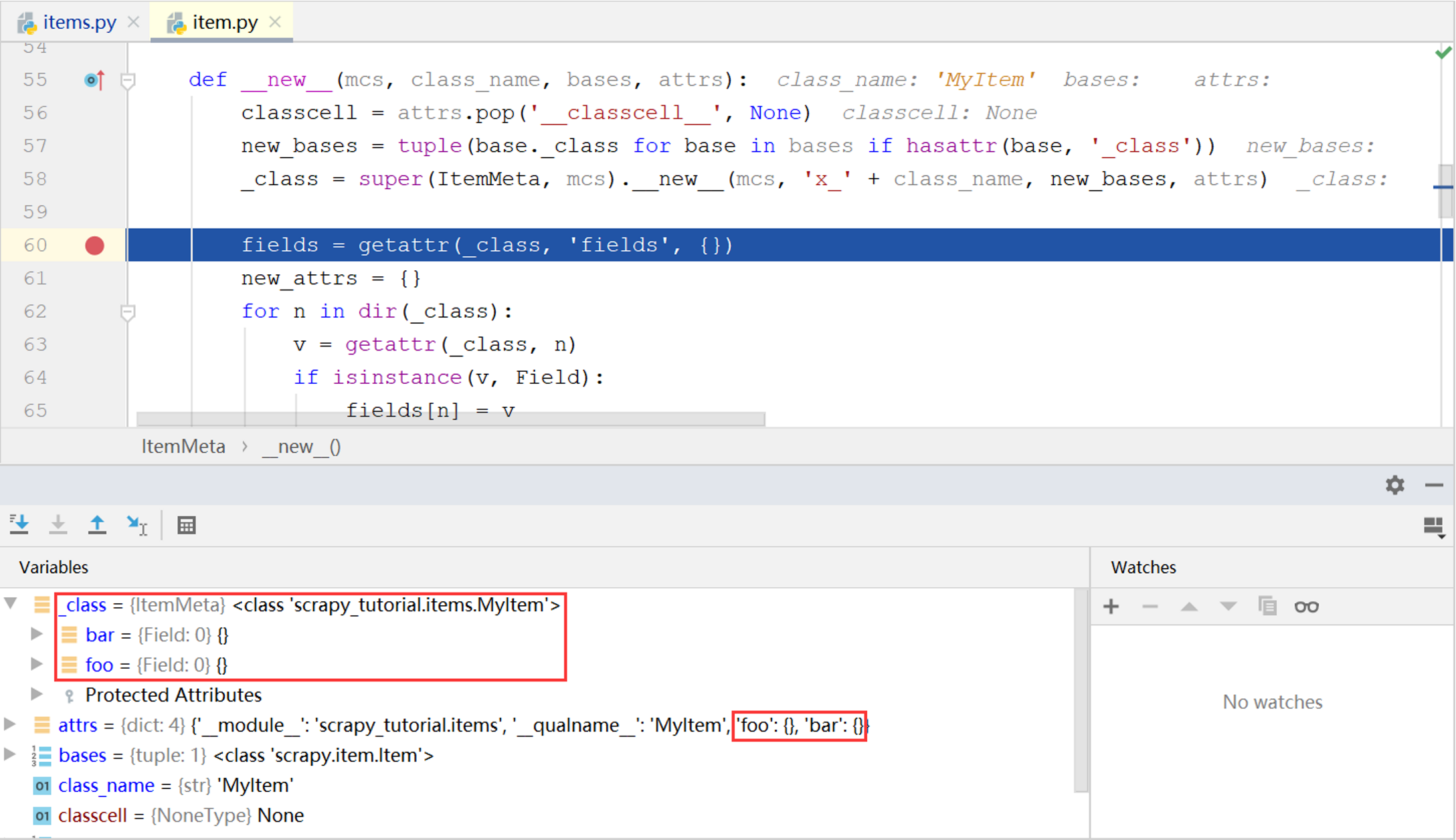
从调试窗口中可以看到,传入的参数attrs确实包含'foo'和'bar'这两项,由此创建出的临时类_class也确实包含foo和bar这两个属性。
综上,Item类及其子类在ItemMeta类的__new__()方法中被“改造”了,所有的字段属性被添加到fields属性中,而没有被包含在最终创建的类中,fields属性在Item类的超类DictItem类中定义:
1
2
3
class DictItem(MutableMapping, BaseItem):
fields = {}
# ...
至此,已经搞清了Item类自定义字段的问题。