【Scrapy源码阅读】response处理过程
以官方教程QuotesSpider为例,结合源码分析一下Scrapy中response的处理过程。
下面是待爬取的网页,红框中的是目标HTML标签:
1.quote文字内容
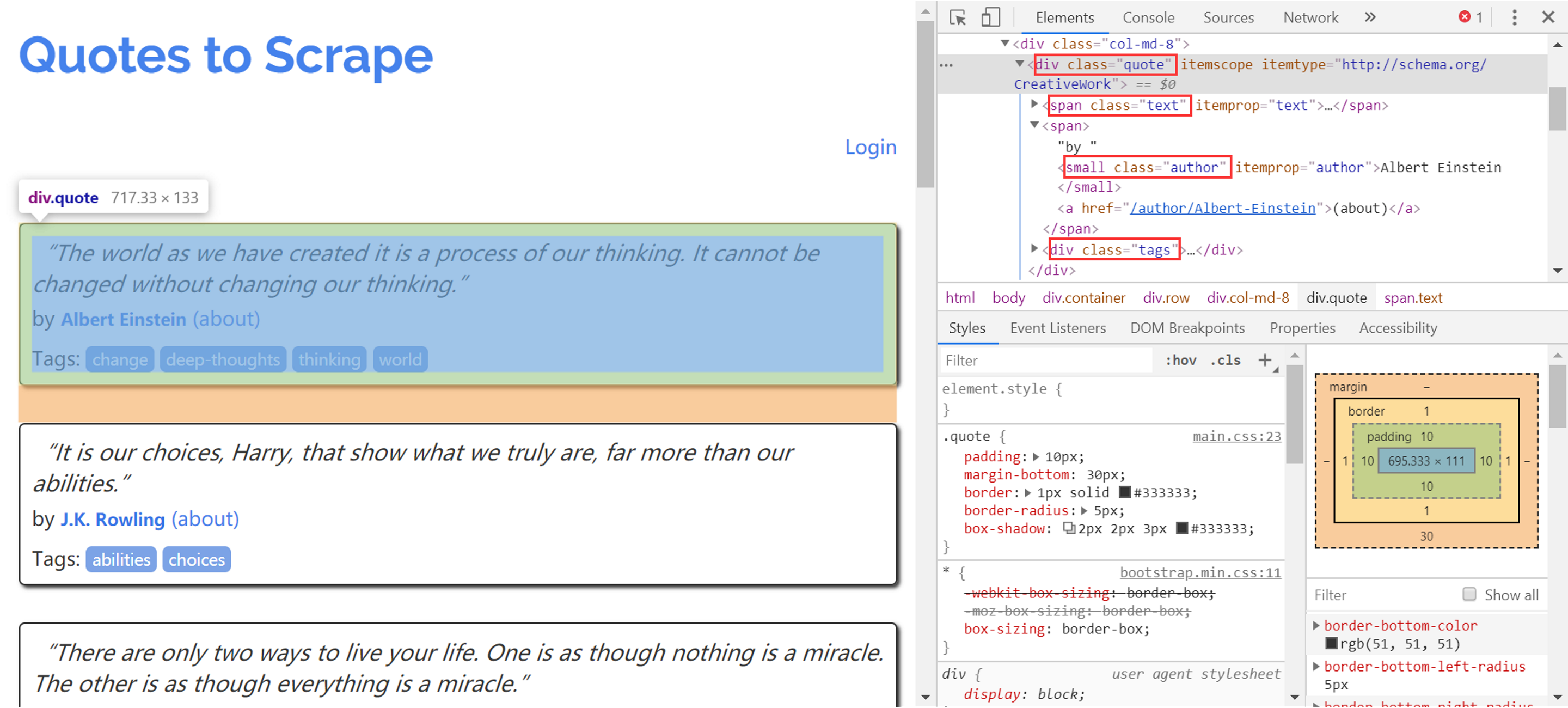
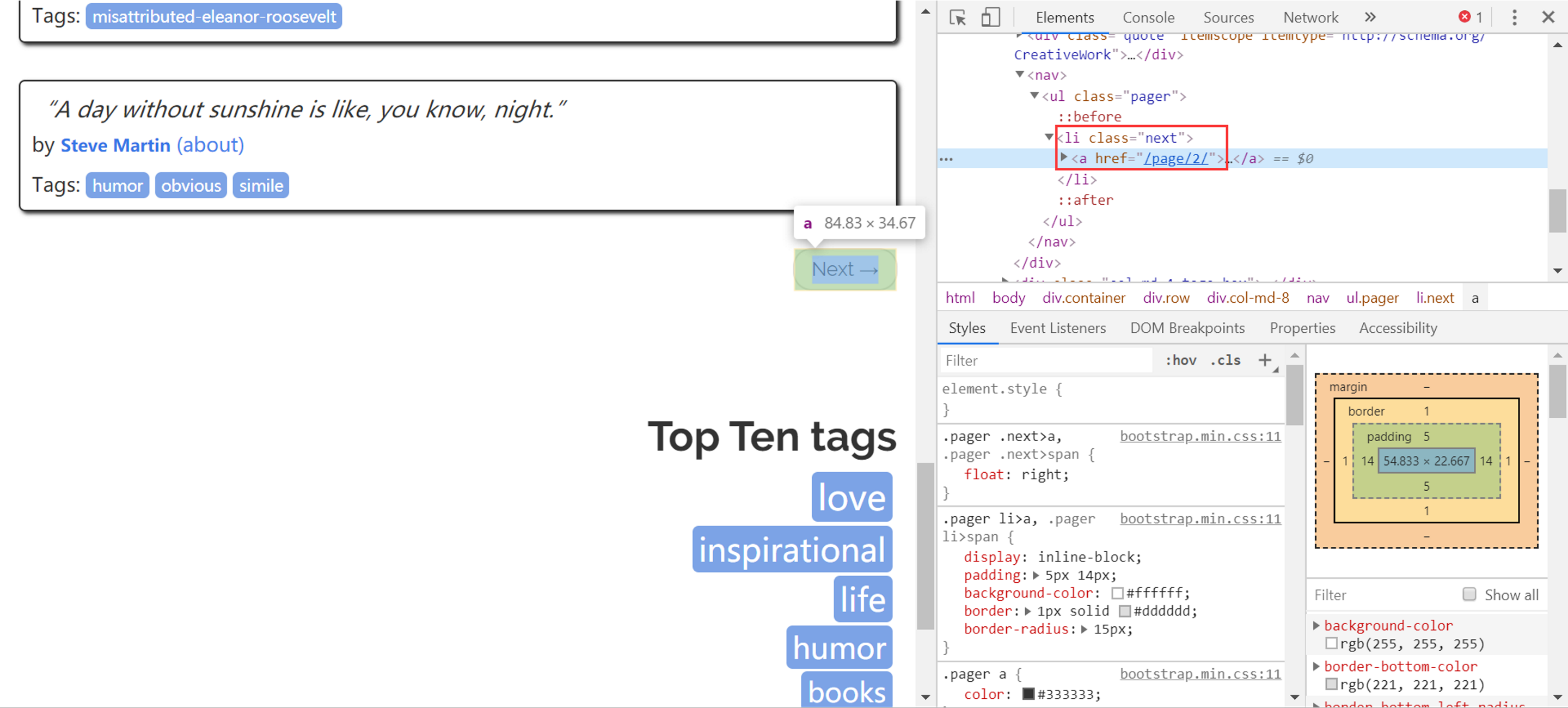
2.下一页链接
QuotesSpider代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
start_urls = [
'http://quotes.toscrape.com/page/1/',
]
def parse(self, response):
for quote in response.css('div.quote'):
yield {
'text': quote.css('span.text::text').get(),
'author': quote.css('small.author::text').get(),
'tags': quote.css('div.tags a.tag::text').getall()
}
next_page = response.css('li.next a::attr(href)').get()
if next_page is not None:
yield scrapy.Request(response.urljoin(next_page), callback=self.parse)
可以看出parse方法是一个生成器,其中有两个yield语句,一个产生包含quote内容的字典对象,这是我们要获取的数据;另一个产生包含下一页链接的Request对象,用于继续爬取。先运行一下这个爬虫,得到下面的输出结果:
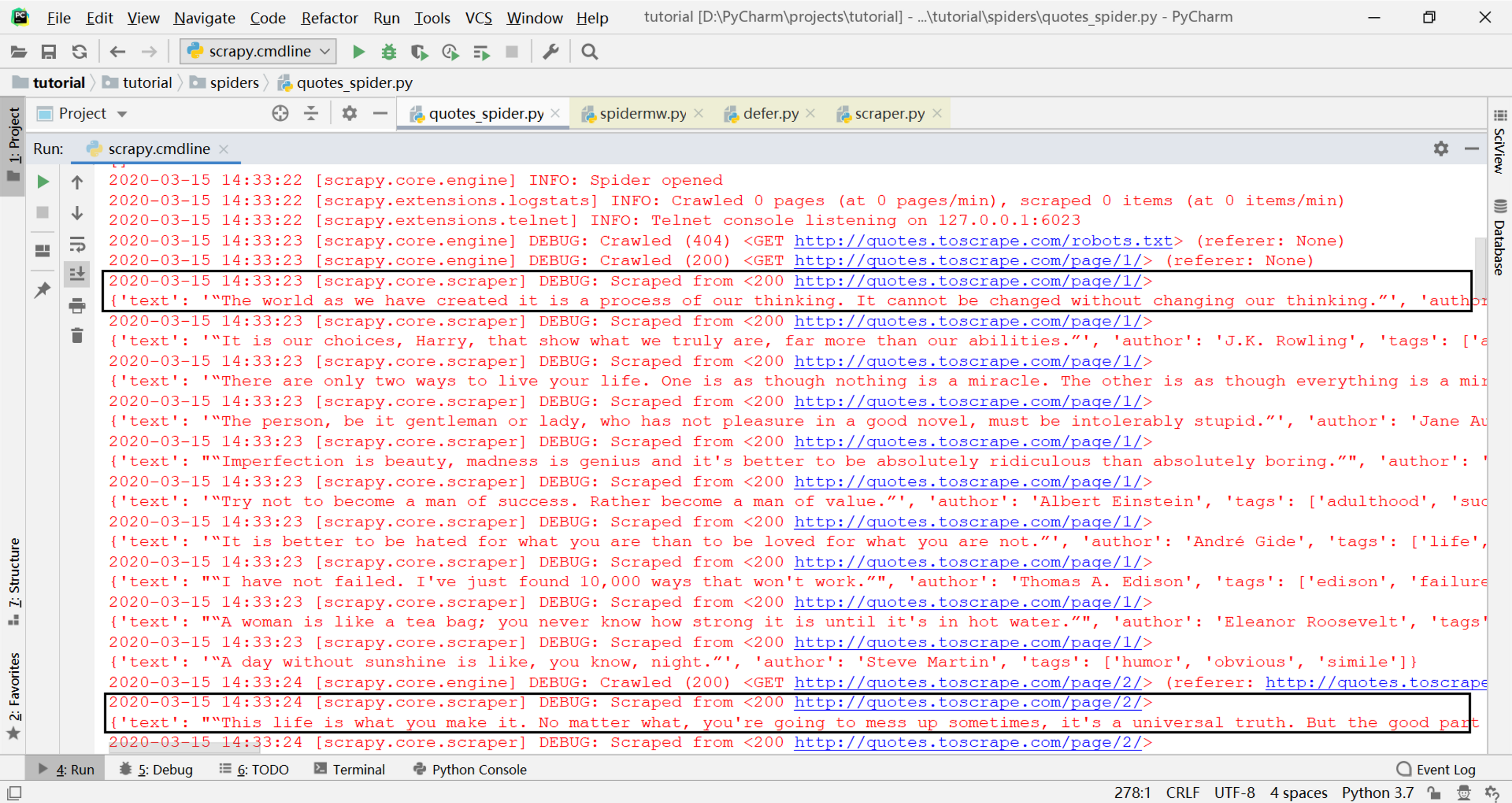
可以看到parse方法产生的字典对象都通过日志输出了,而Request对象包含的后续链接也被正确爬取了。那么这两种类型的对象在哪里被处理?分别被如何处理?
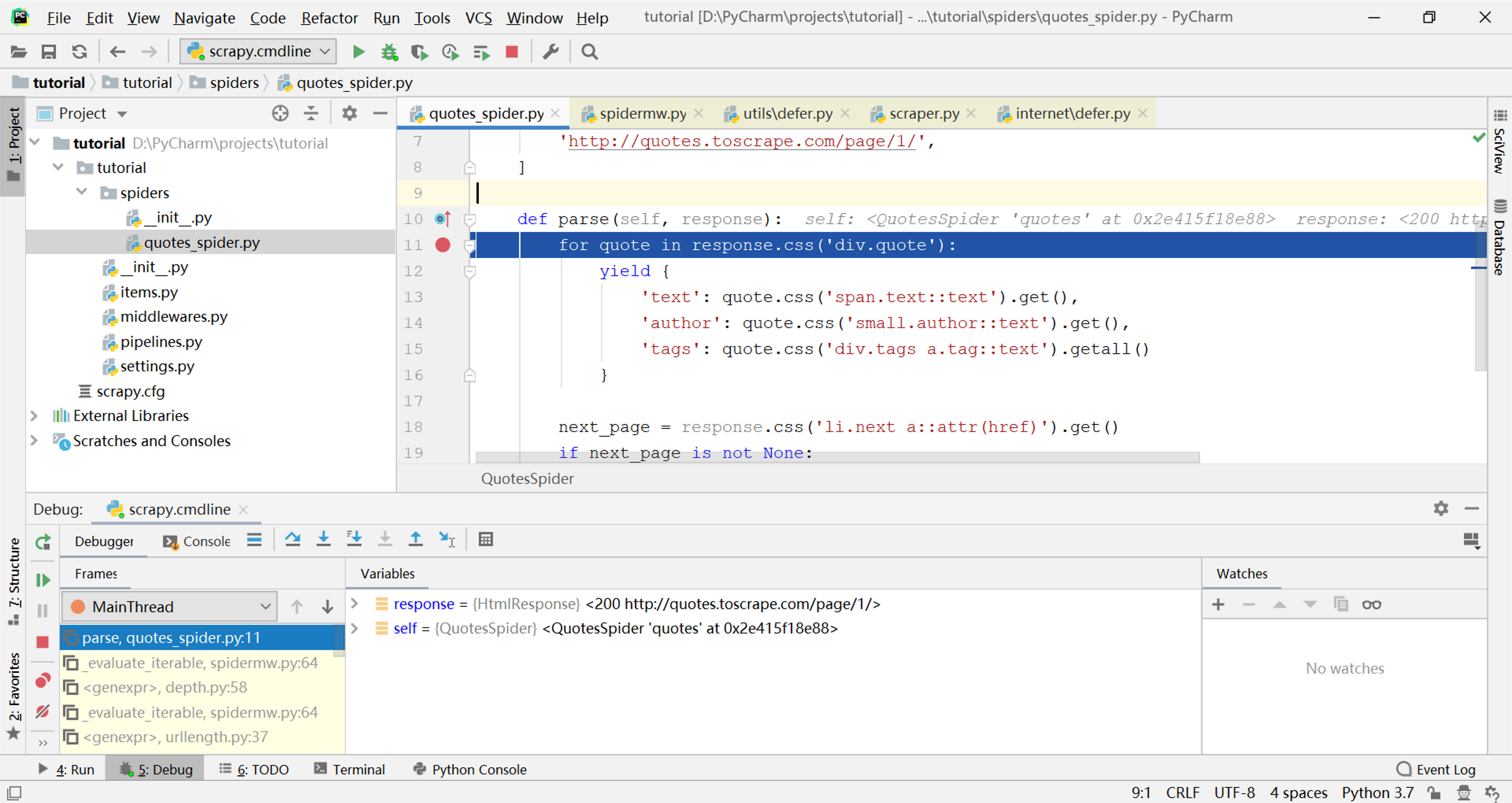
首先在parse方法中设置断点,进入调试状态(具体方法见在PyCharm中调试Scrapy爬虫),如下图所示:
在左下角的调用栈中找到上一层调用,如下图所示:
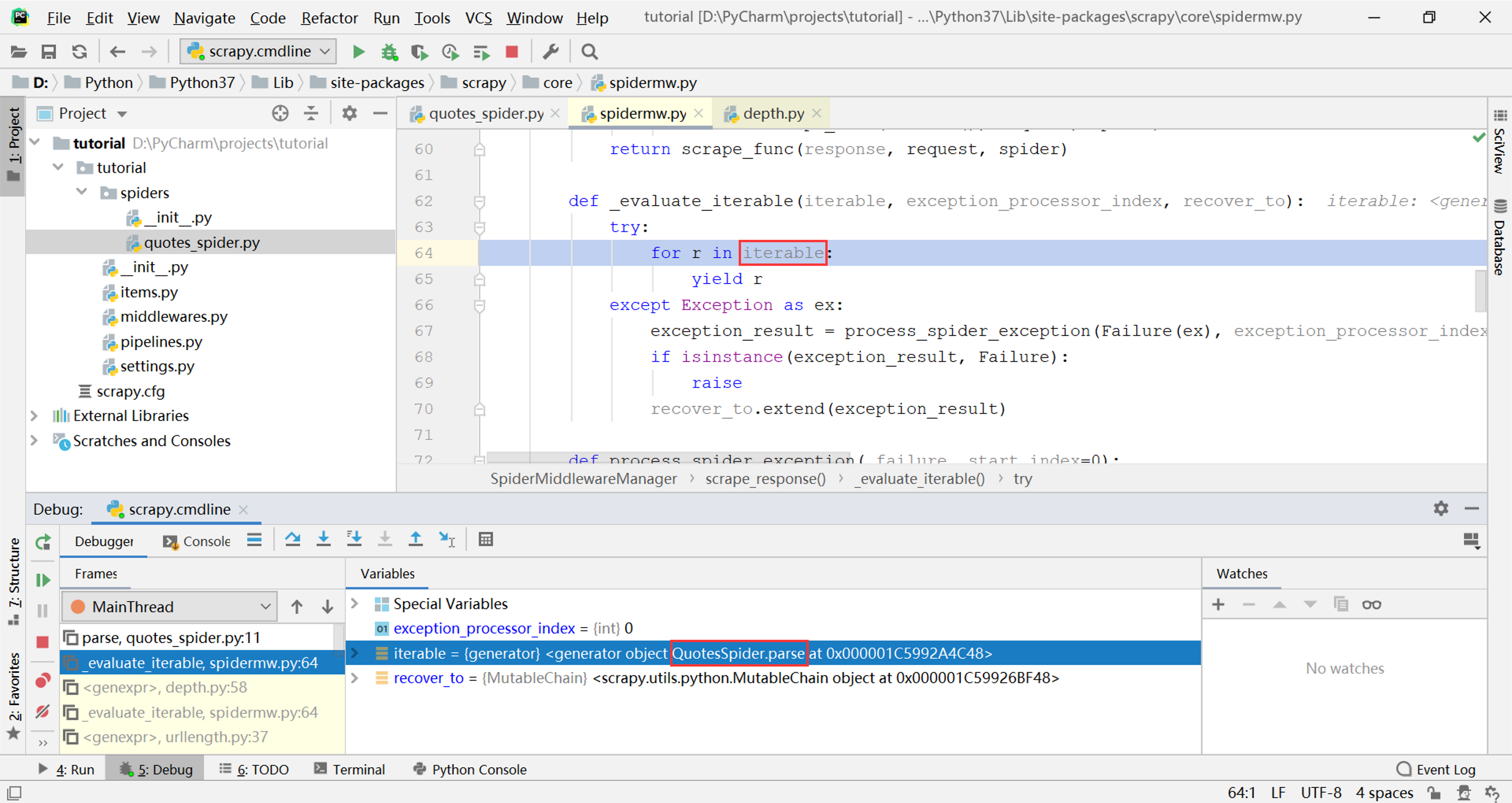
可以看到parse方法(生成器)在一个叫作_evaluate_iterable的函数中作为参数iterable被迭代,而这个函数本身也是一个生成器。
继续寻找上一层调用栈,发现_evaluate_iterable函数(生成器)在DepthMiddleware.process_spider_output方法中被以生成器表达式的形式迭代:
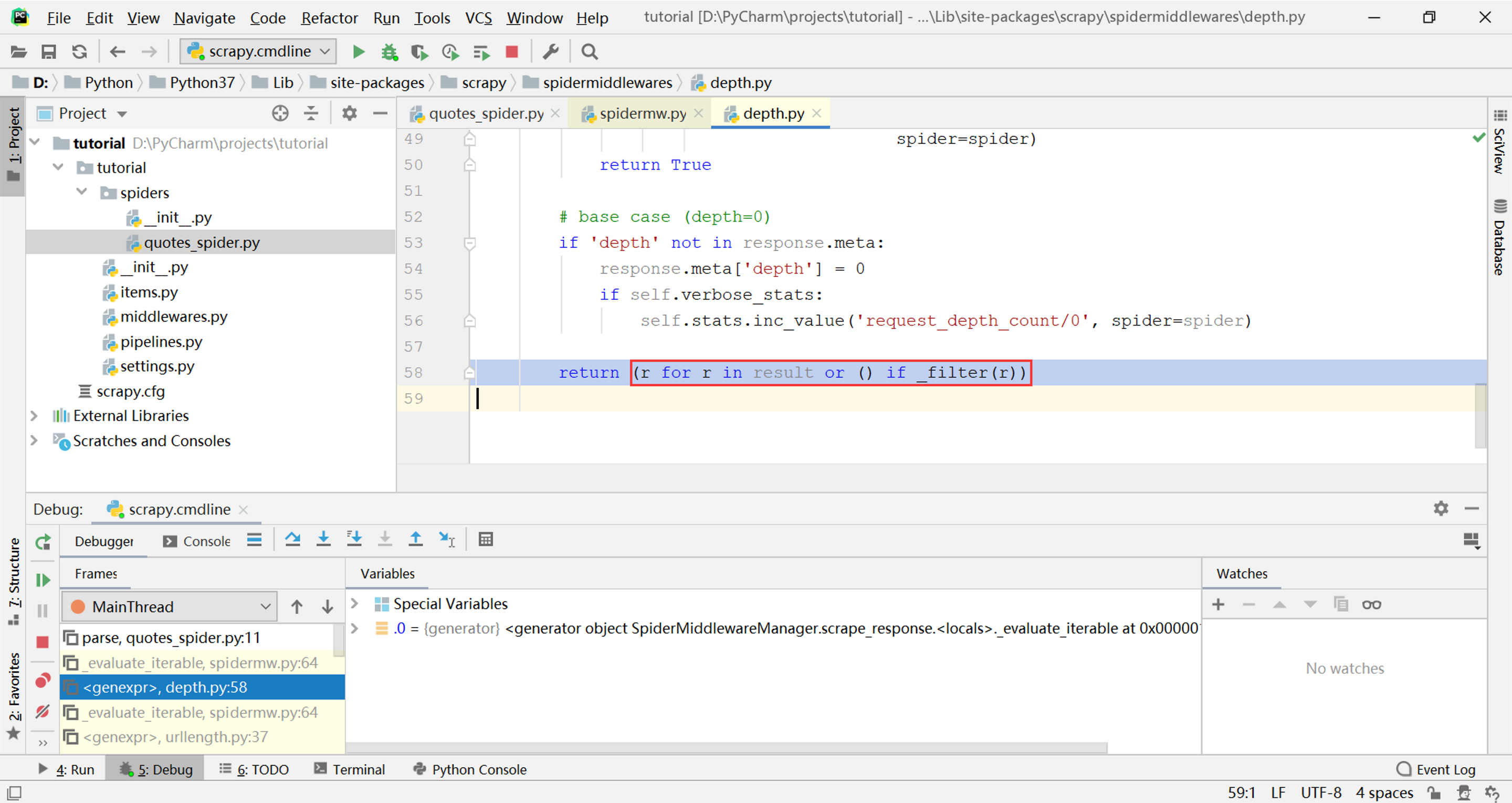
这两层调用就是一个内置中间件depth,可以看出所谓中间件其实就是对spider生成的对象做一个过滤,其中的_filter函数就是中间件自己定义的过滤规则,其他的中间件也都包含这一行相同的代码。
spider产生的对象通过中间件的过程对应官方文档整体架构图中的第7步。
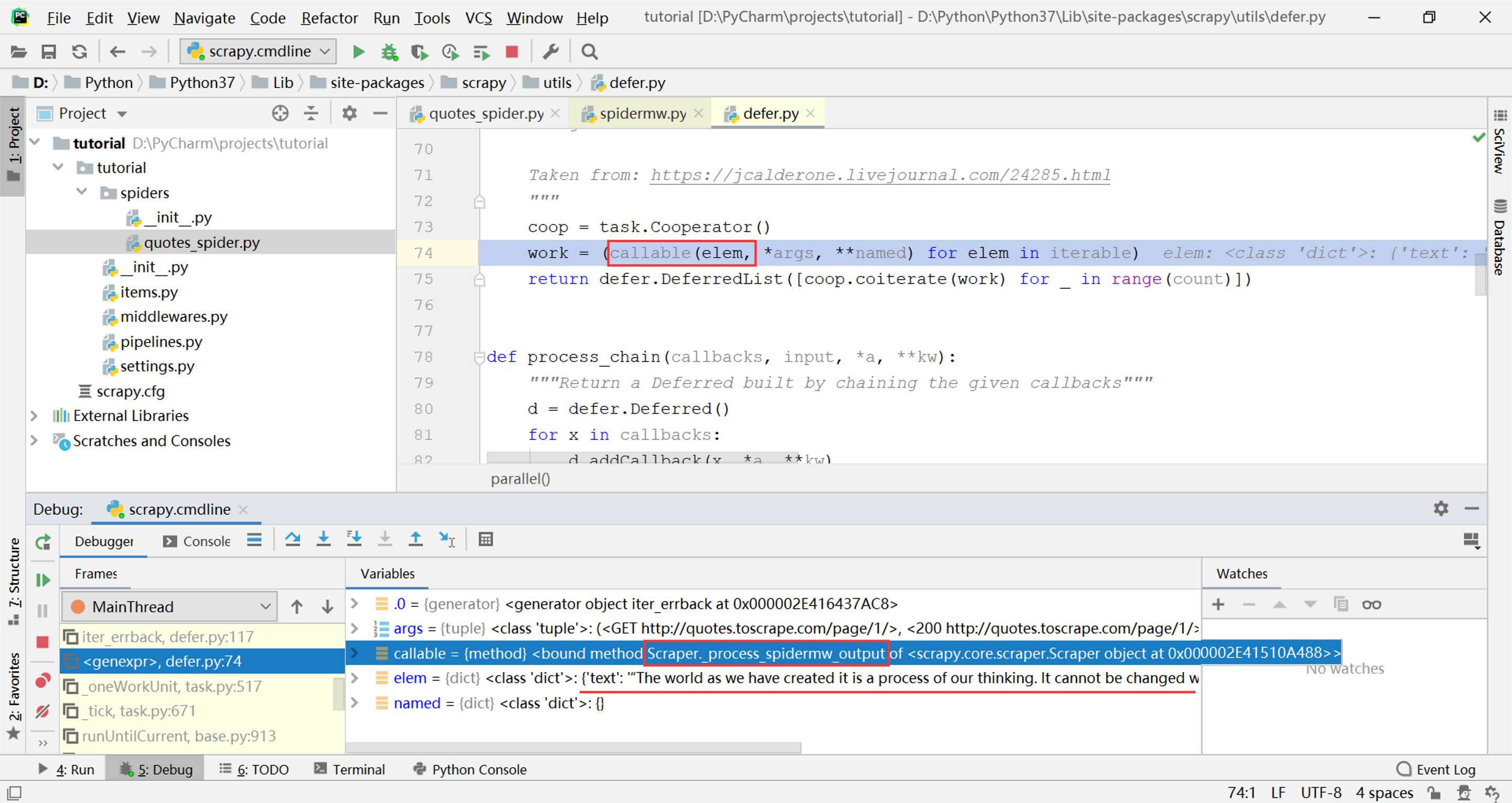
在调用栈中继续向上寻找,越过其他的中间件,找到最顶层调用在scrapy.utils.defer.parallel函数的一个生成器表达式work中,如下图所示(这张图实际上是在parse方法的下一次循环时截的,否则调试窗口中看不到elem),将本次产生的elem对象应用于一个callable对象,从调试窗口中可以看到这个callable是Scraper._process_spidermw_output方法(从方法名中可以猜测这是处理经过所有中间件后得到的最终输出结果的方法)
打开菜单Navigate->Class…,输入Scraper,打开这个类的源代码

找到_process_spidermw_output方法,如下图所示,可以看到这个方法中果然有对output类型的判断,从调试窗口中可以看到参数output就是刚才的elem,即parse方法本次通过yield语句产生的对象
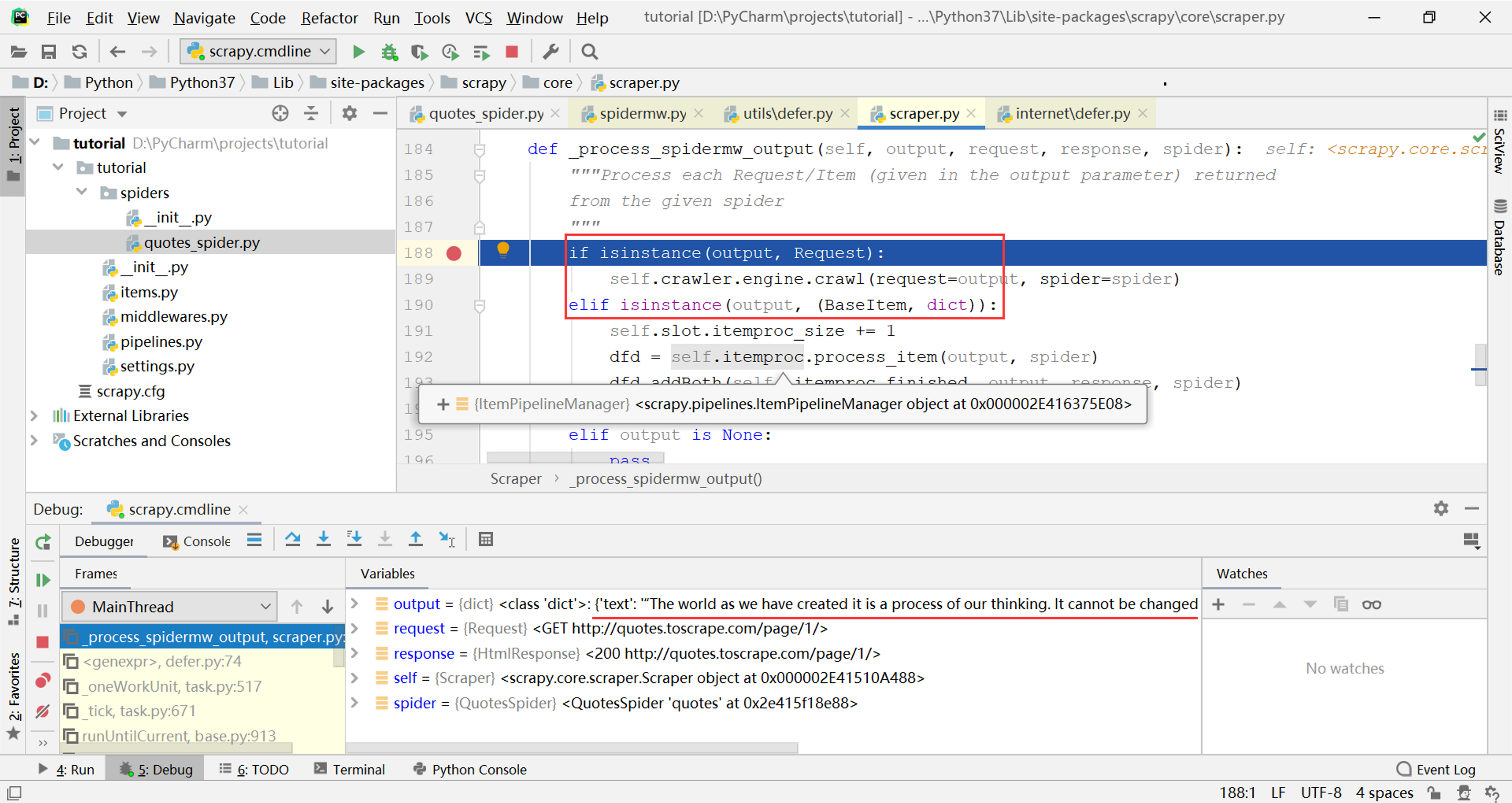
很明显,这个方法对不同类型的对象做不同的处理,对应上面整体架构图中的第8步:

- 如果output是
Request对象,则将其交给引擎准备继续爬取,打开ExecutionEngine类的crawl方法可以看到引擎直接将其交给了调度器 - 如果output是
BaseItem或字典类型,则将其交给Item Pipeline处理,下面具体分析一下这一步的处理过程
回到_process_spidermw_output方法,由于本次的output是字典类型,因此将其应用于self.itemproc.process_item方法(其中self.itemproc是一个ItemPipelineManager类型的对象,也是一种中间件)。如果项目自定义了Item Pipeline(例如将结果保存到数据库等),其process_item方法将会在此处被调用。
self.itemproc.process_item方法返回了一个包含数据信息(在result属性)的Deferred类型的对象dfd(完整类名是twisted.internet.defer.Deferred,属于Scrapy的底层依赖库Twisted)
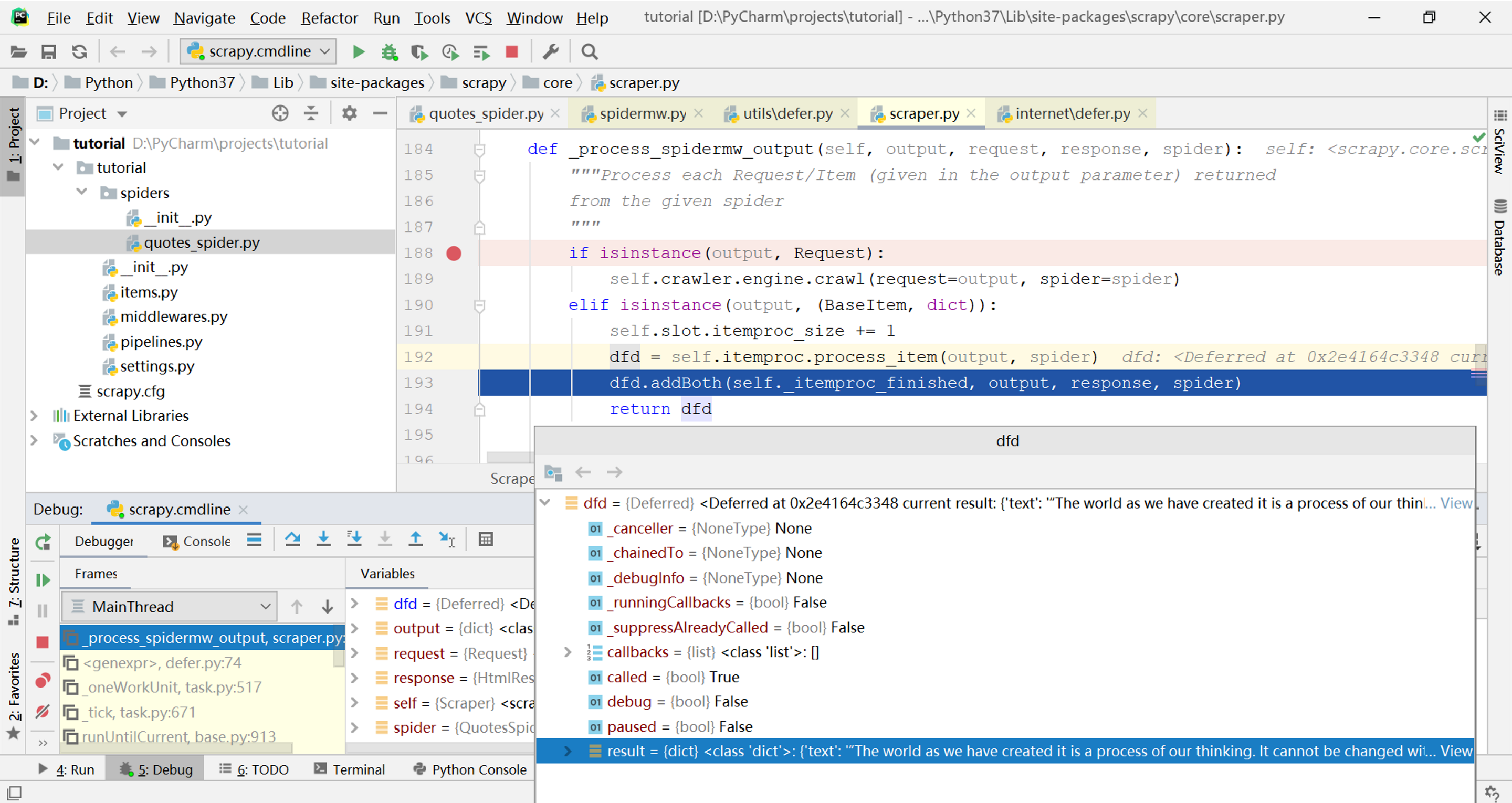
接下来以self._itemproc_finished为”callback”参数调用了dfd.addBoth方法,继续跟踪源代码,经过addBoth->addCallbacks->_runCallbacks几次调用,在下图的位置找到了对callback这个参数的调用:
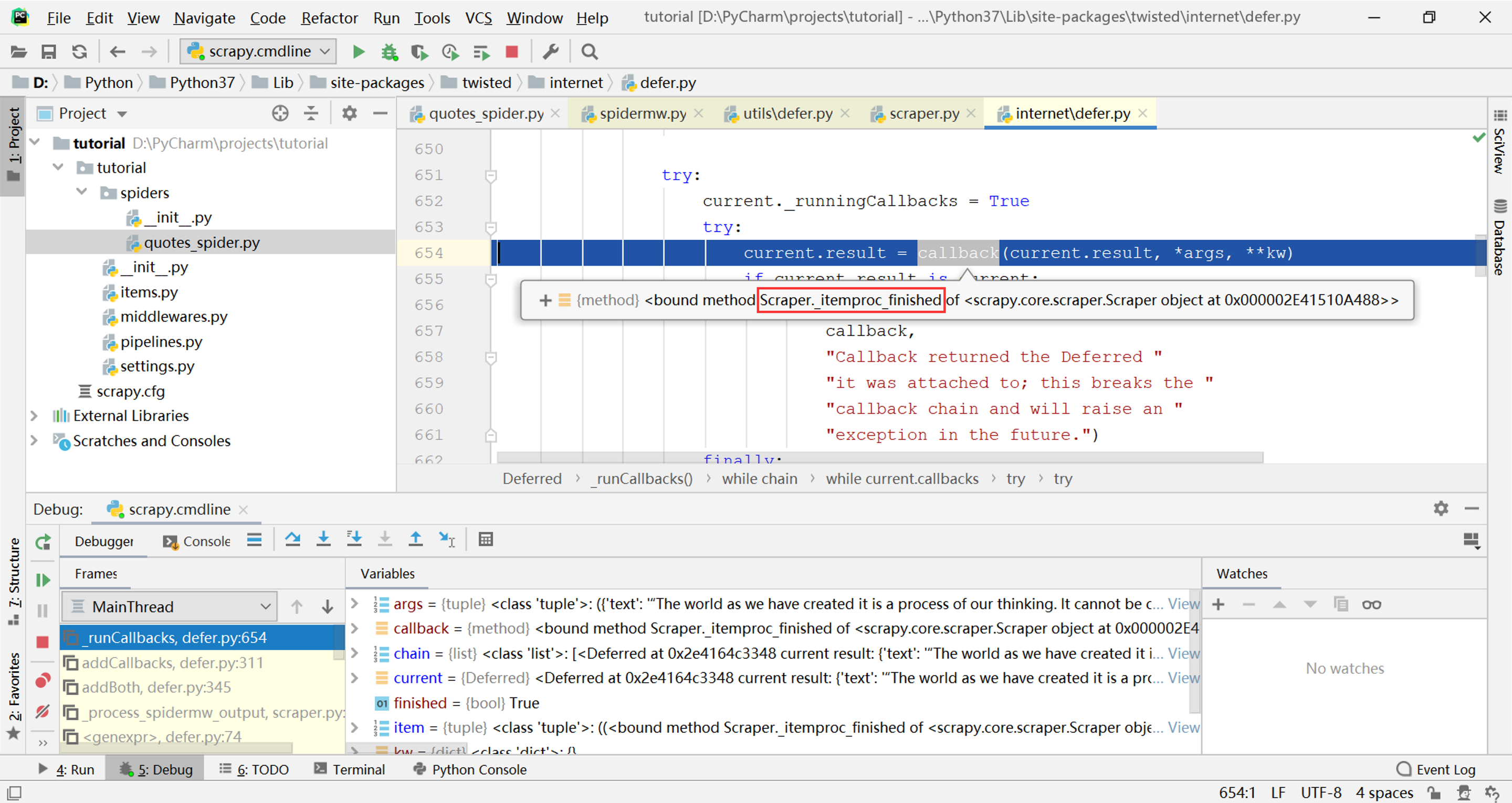
这个参数就是刚才传入的Scraper._itemproc_finished,所以调用又回到Scraper类,终于在下图的位置找到了日志输出的来源:
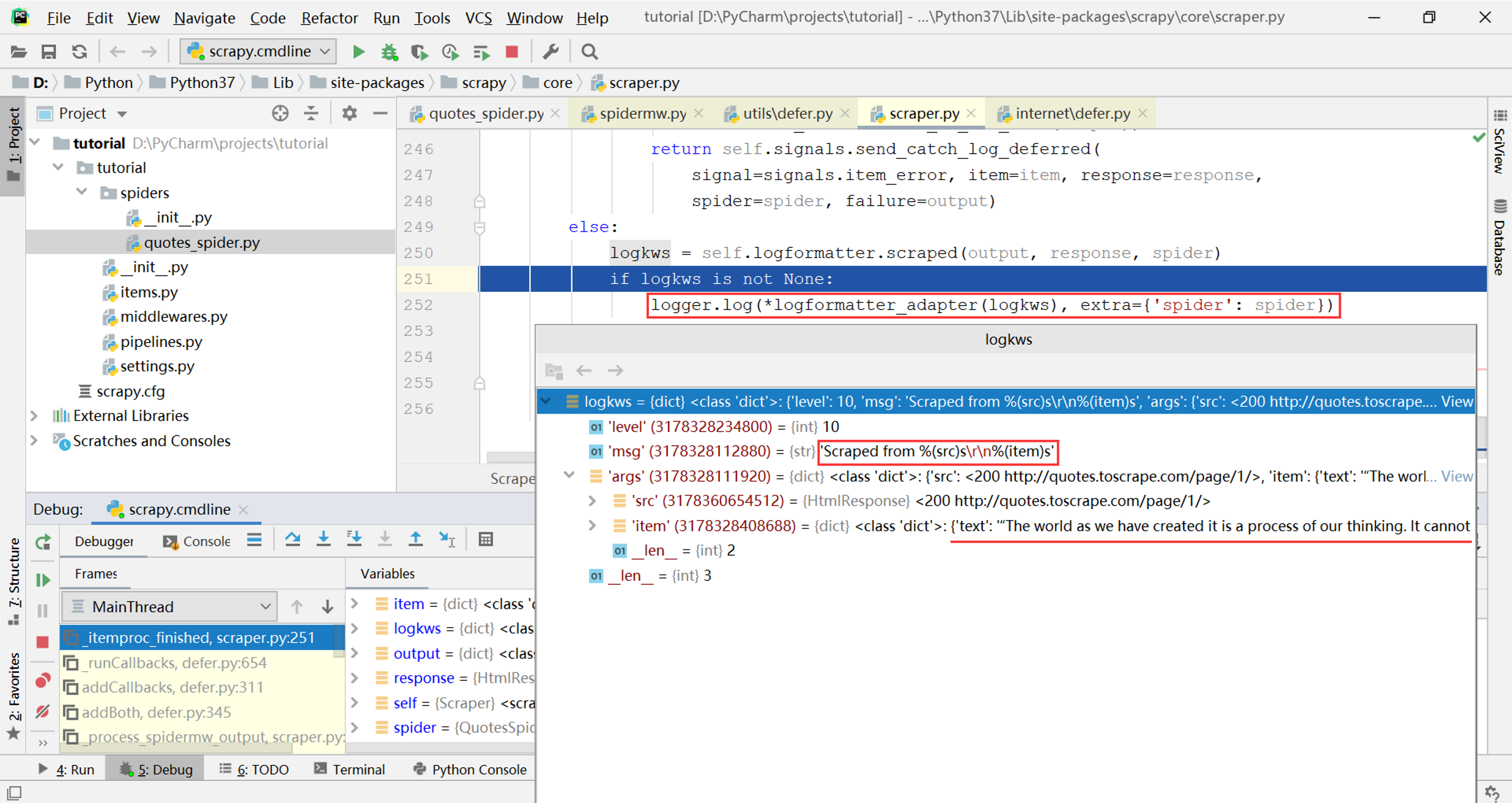
logkws是日志输出的格式,其中的item参数就是parse方法产生的字典对象,通过调试单步执行这一行,可以看到打印这个字典对象的日志输出就是这一行代码:
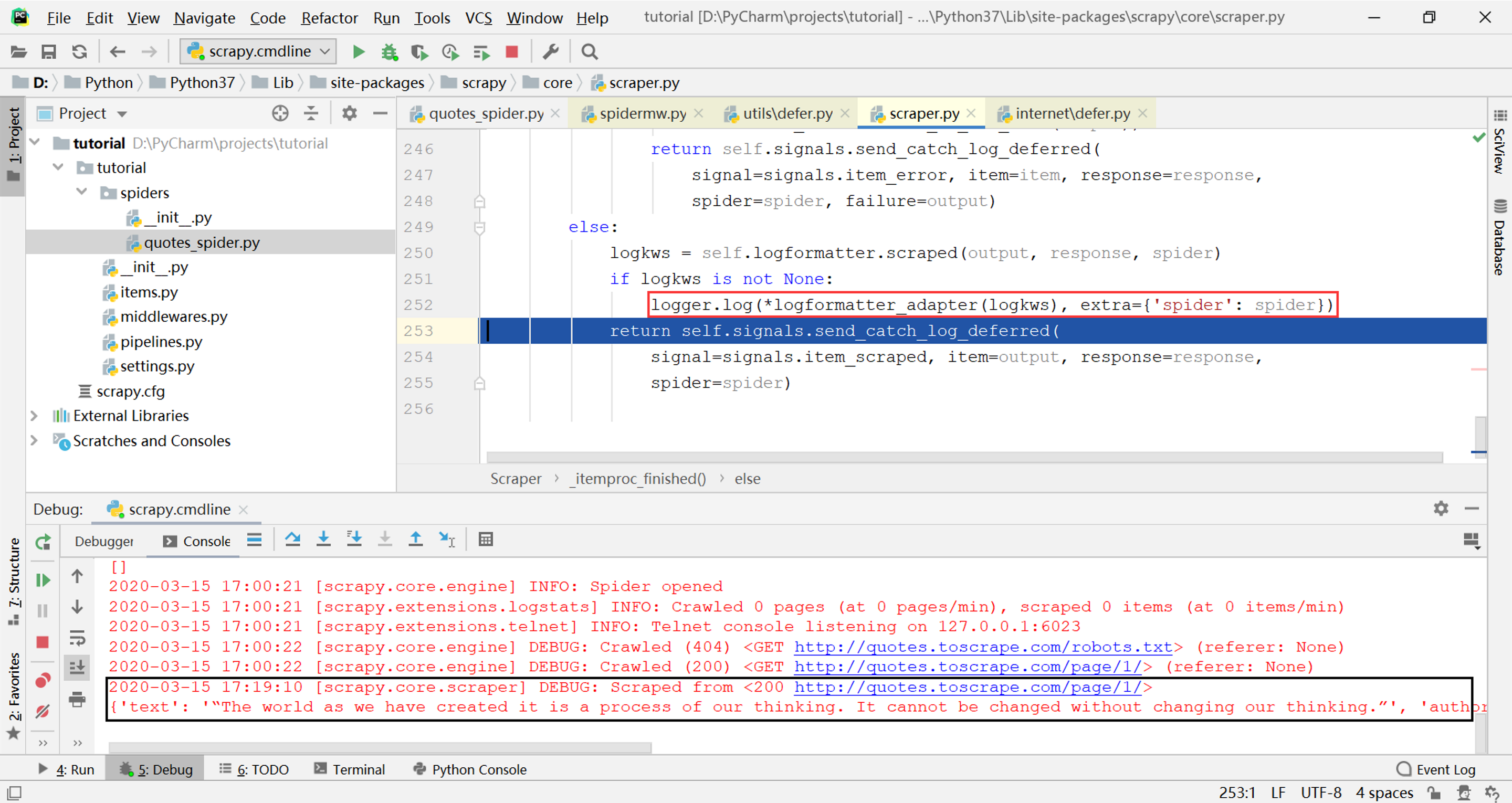
至此已经搞清楚了Scrapy中spider的parse方法生成结果的处理过程,即整体架构图中的第7~8步。然而这只是Scrapy源码的一小部分,其他部分有机会再继续研究。