【Scrapy源码阅读】Spider参数传递
官方文档Spider参数中提到,可以使用scrapy crawl命令的-a选项向Spider传递参数:
scrapy crawl myspider -a arg1=value1 -a arg2=value2
这些参数会被传递到自定义的MySpider类的构造函数,并且超类Spider的构造函数会将其拷贝到属性中:
1
2
3
4
5
6
7
8
9
10
11
import scrapy
class MySpider(scrapy.Spider):
name = 'myspider'
def __init__(self, *args, **kwargs):
# kwargs['arg1'] == 'value1'
# kwargs['arg2'] == 'value2'
super().__init__(*args, **kwargs)
# self.arg1 == 'value1'
# self.arg2 == 'value2'
那么这些命令行参数是如何被解析,并最终设置为Spider的属性的?下面通过源码分析这一过程。
1.解析命令行参数
从Scrapy的命令行模块scrapy.cmdline入手,通过命令行输入的命令由该模块中的execute()函数执行:
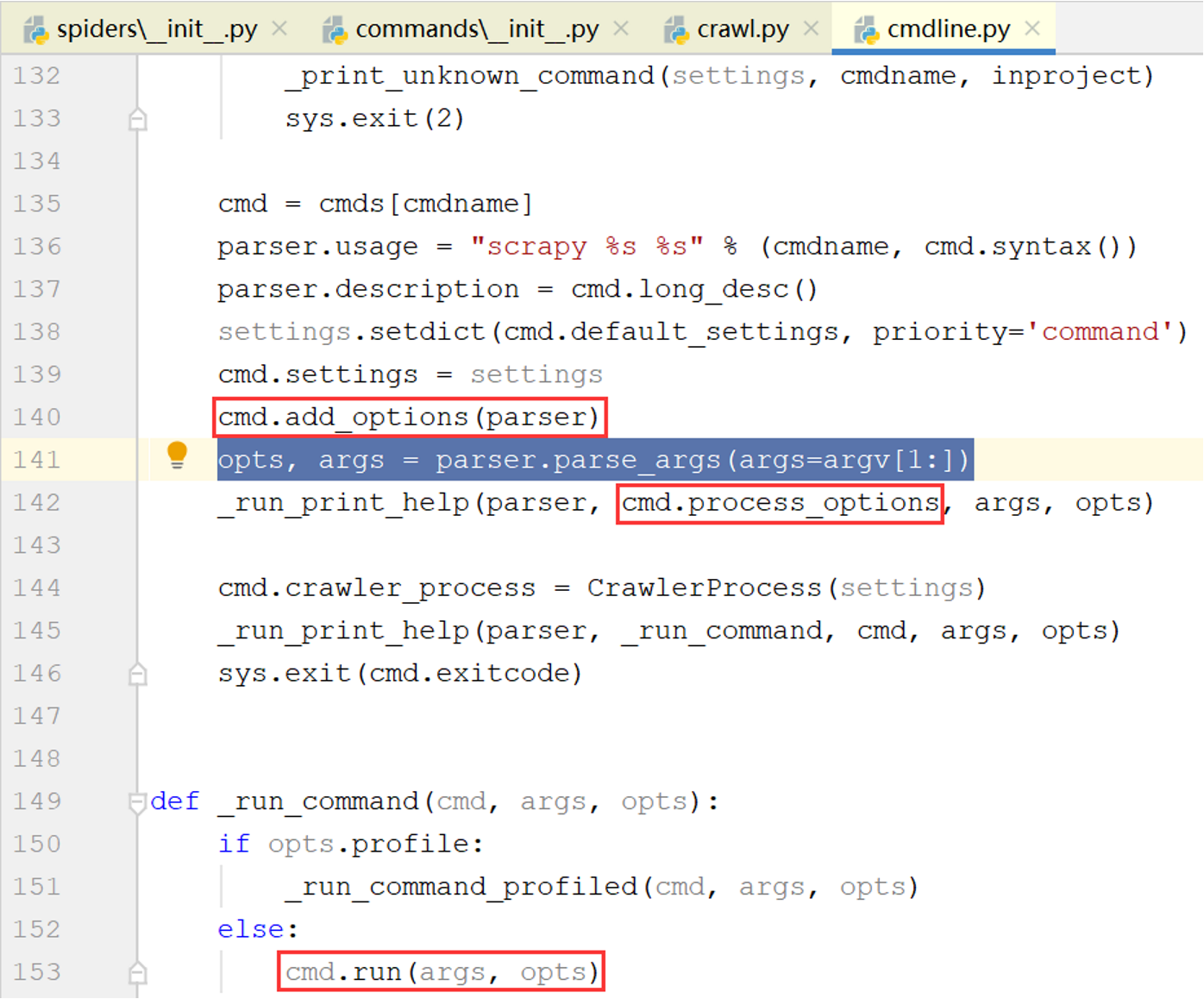
这里有两个关键的对象:parser是Python内置模块optparse中的OptionParser类的对象,用于解析命令行参数;cmd是命令类的对象(crawl命令对应scrapy.commands.crawl.Command类)
该函数的几个关键步骤:
- 调用
cmd.add_options(parser)方法为解析器添加可识别的选项 - 解析命令行参数并将结果保存在
opts和args两个变量中(opts包含选项参数,args包含位置参数) - 调用
cmd.process_options(args, opts)方法处理解析结果 - 将
cmd.crawler_process设置为一个新的CrawlerProcess对象 - 以这两个变量为参数调用命令对象的
run()方法
(1)添加选项
-a选项在scrapy.commands.BaseRunSpiderCommand类的add_option()方法中被添加:

其中action="append"表示该选项可重复,参数值将被存储在一个列表中,dest="spargs"表示该选项在解析结果中的属性名称为spargs
例如,待解析的命令行参数为-a arg1=value1 -a arg2=value2,解析结果为opts,则opts.spargs是长度为2的列表['arg1=value1', 'arg2=value2']
(2)处理解析结果
BaseRunSpiderCommand的process_options()方法解析了opts.spargs并将其转换为字典
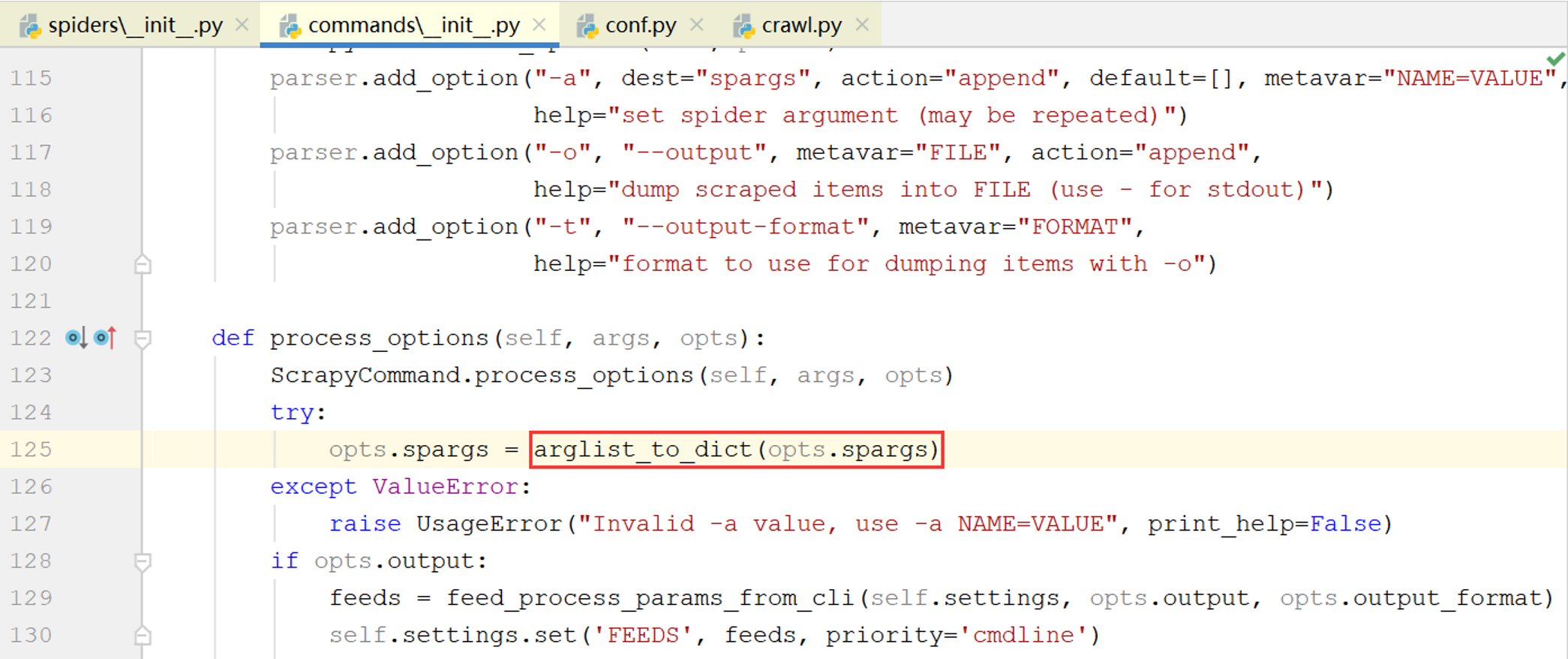
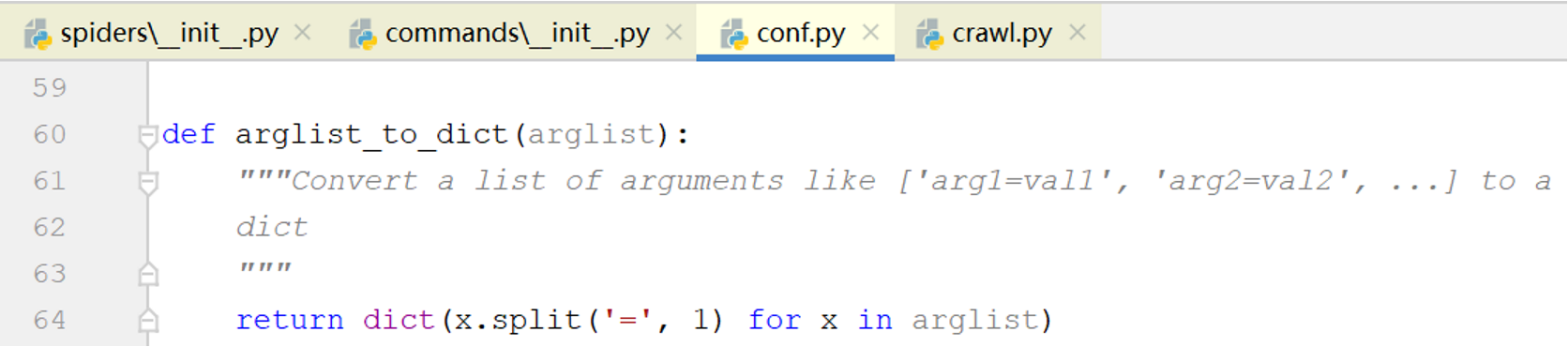
因此['arg1=value1', 'arg2=value2']将变为{'arg1': 'value1', 'arg2': 'value2'}
至此,解析命令行参数已完成,下面分析cmd.run()如何使用这些解析结果。
2.运行命令
查看scrapy.commands.crawl.Command的run()方法的代码:
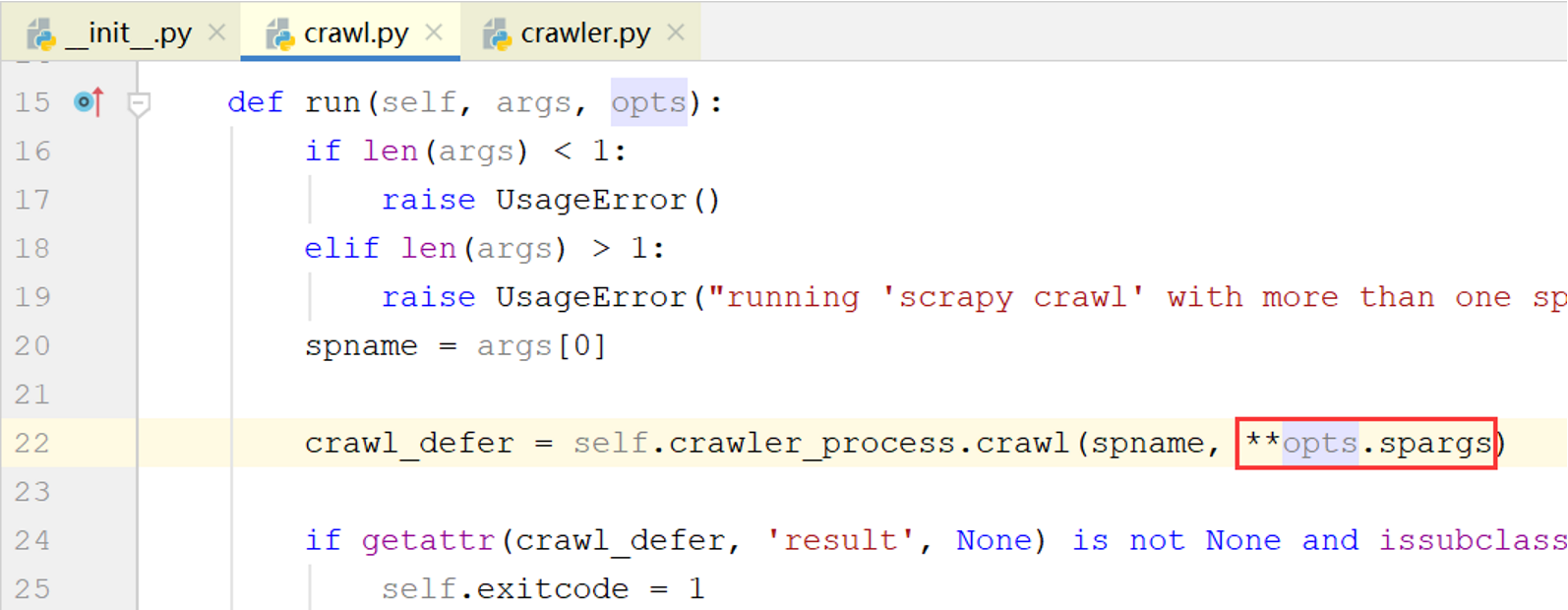
参数opts为之前的解析结果,run()方法以关键字参数的形式将opts.spargs传入scrapy.crawler.CrawlerProcess类的crawl()方法,该方法继承自CrawlerRunner.crawl(),继续跟踪该方法的调用过程
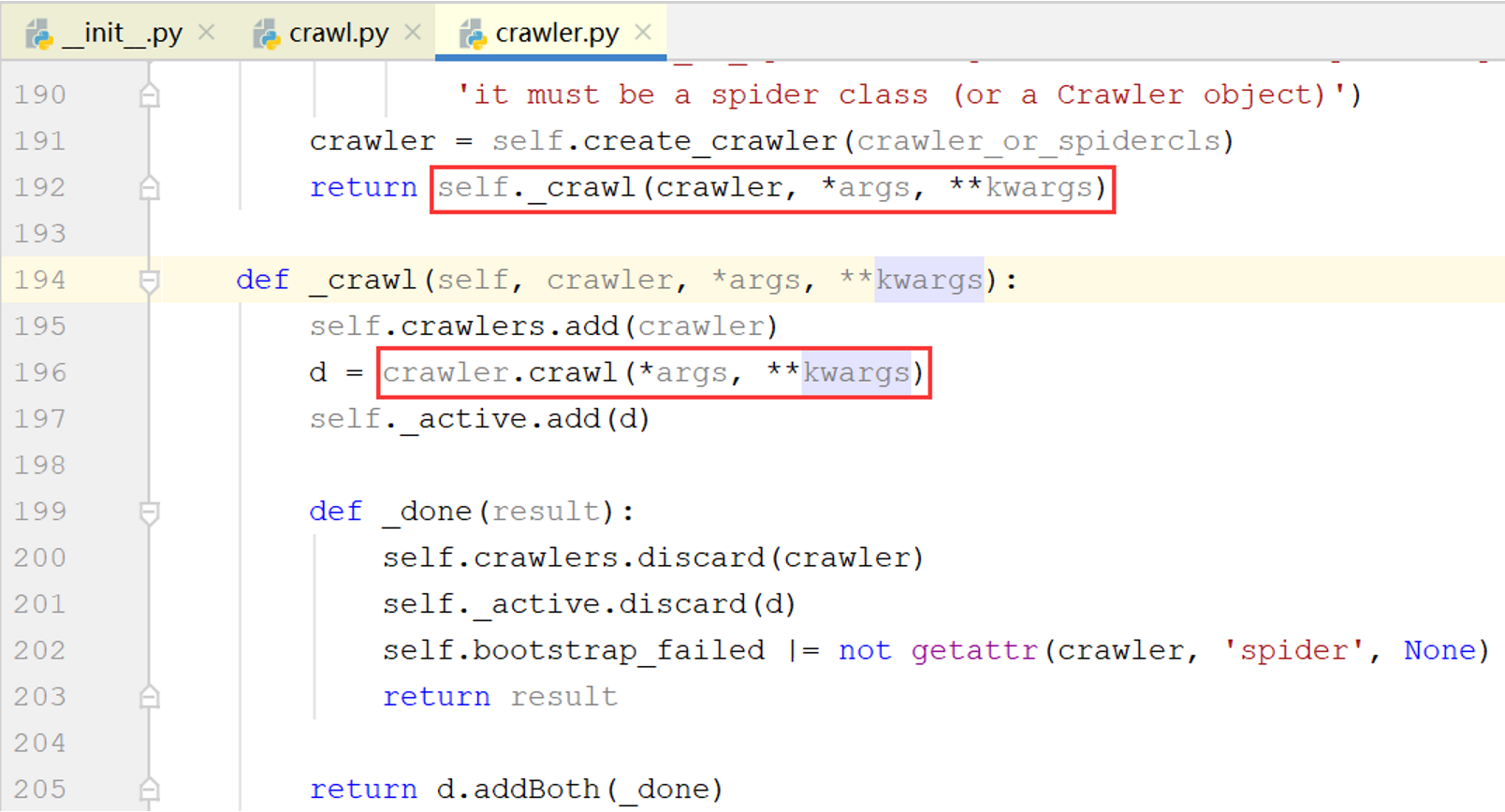
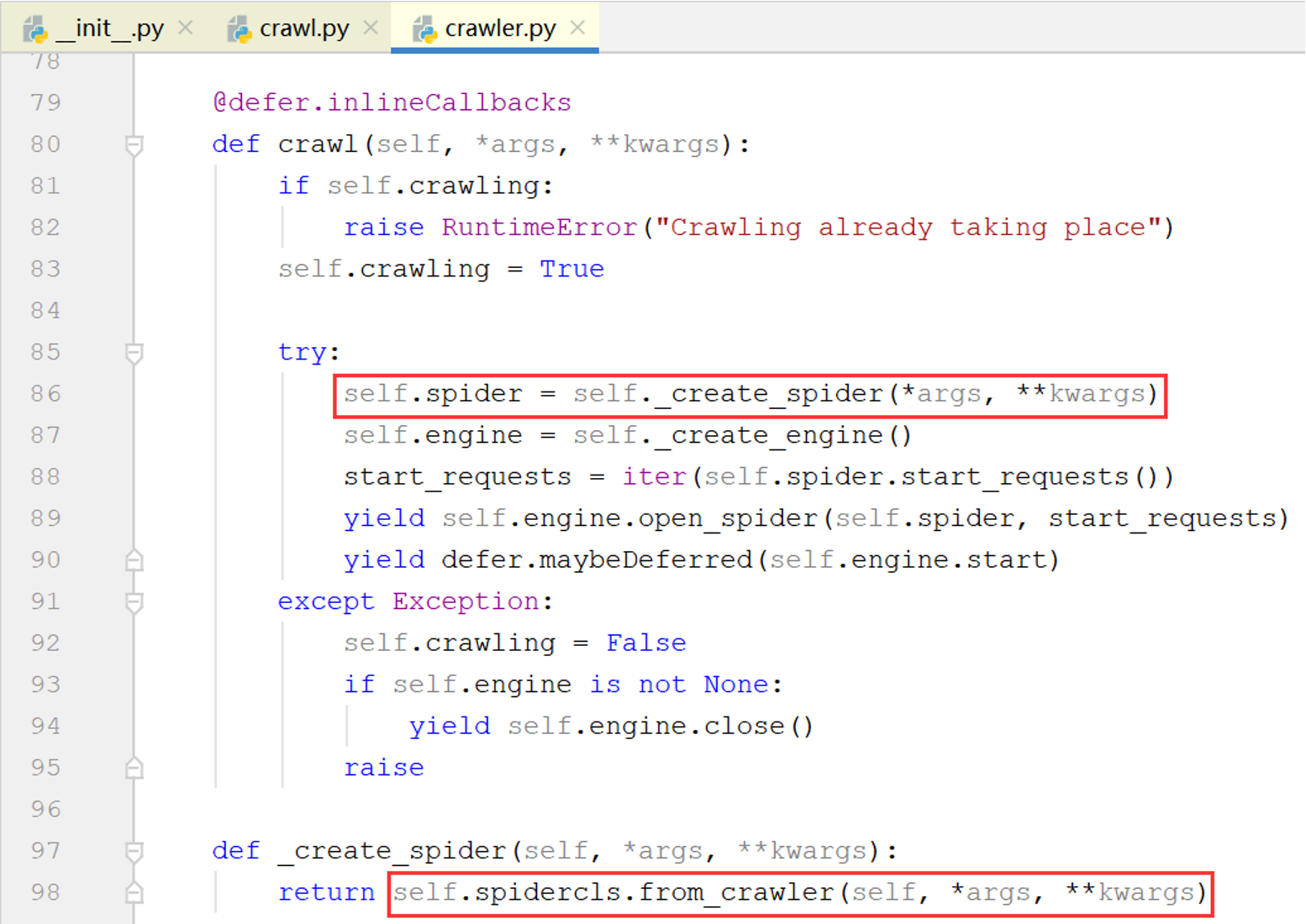
经过CrawlerRunner.crawl()->CrawlerRunner._crawl()->Crawler.crawl()->Crawler()._create_spider()几次调用后,kwargs(即之前的opts.spargs)最终被传递到Spider.from_crawler()方法,上图中最后一行的spidercls就是自定义的MySpider类
3.创建Spider对象
查看Spider.from_crawler()方法的代码:
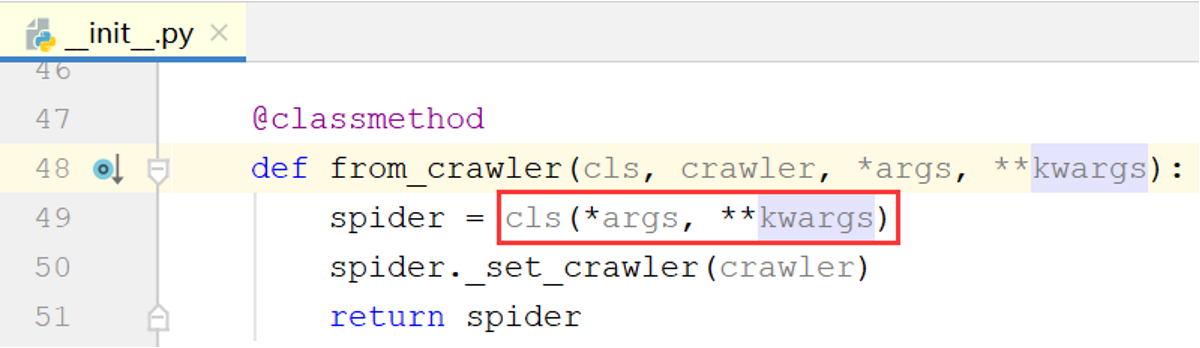
可以看到,kwargs被传入cls(即自定义的MySpider类)的构造函数,如果MySpider类没有定义构造函数则继承Spider类的构造函数
查看Spider类的代码,发现其构造函数中的下面这行代码将kwargs中的键值对转换为自身的属性:
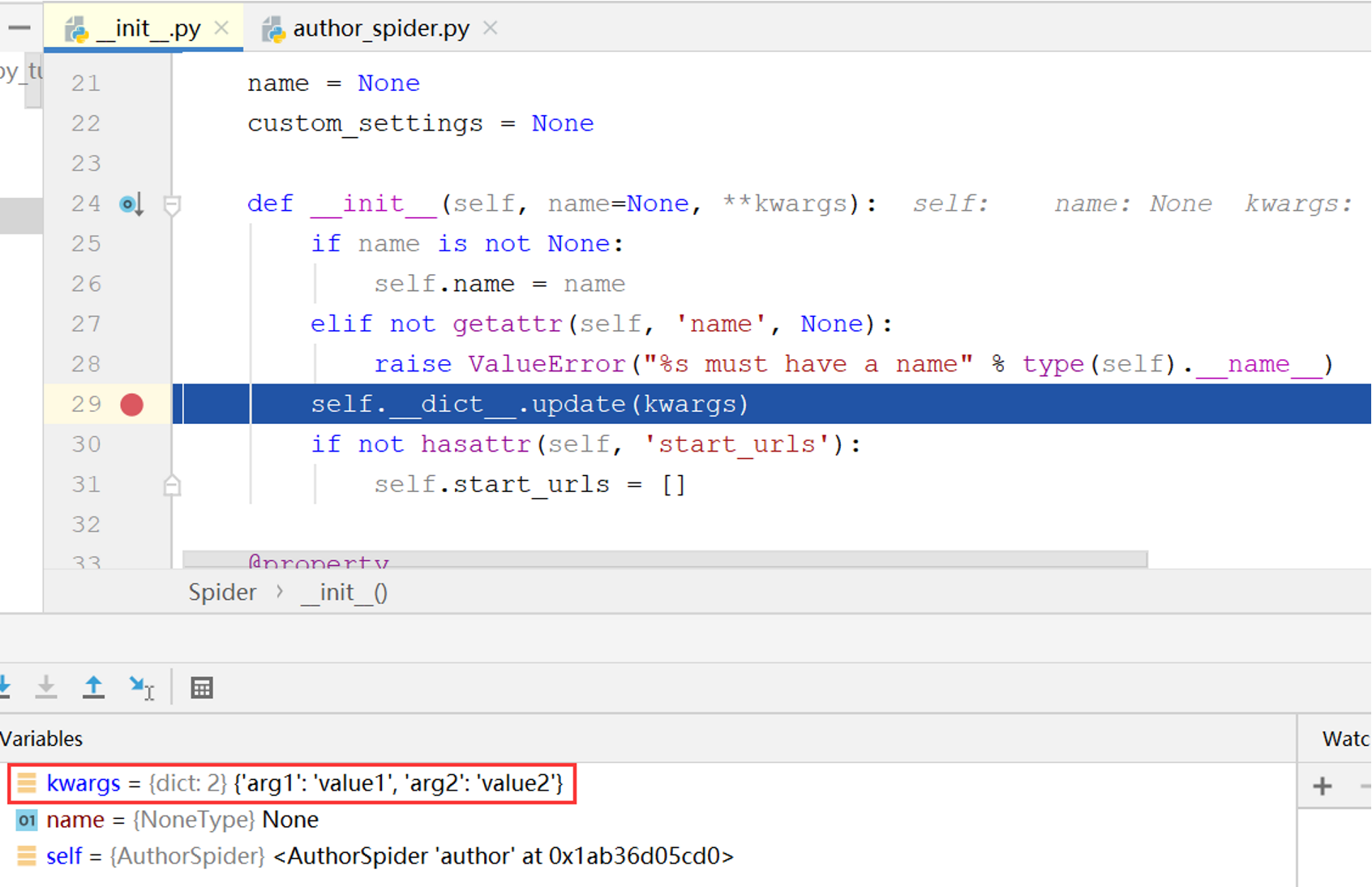
至此Spider参数的传递过程已经分析清楚。