《C程序设计语言》笔记 第5章 指针与数组
指针(pointer)是一种保存变量地址的变量。在C语言中,指针的使用非常广泛。一个原因是,指针有时是表达某个计算的唯一途径;另一个原因是,同其他方法比起来,使用指针可以生成更紧凑、更高效的代码。指针与数组之间的关系十分密切,本章将讨论它们之间的关系,并探讨如何利用这种关系。
指针和goto语句一样,会导致程序难以理解。如果使用者粗心,指针很容易就指向了错误的地方。但是,如果谨慎地使用指针,便可以利用它写出简单、清晰的程序。
5.1 指针与地址
首先,通过一个简单的示意图来说明内存是如何组织的。通常的机器都有一系列连续编号或编址的存储单元,这些存储单元既可单独进行操作,也可以以连续成组的方式操作(每个存储单元是一个字节(byte),一个字节是8个二进制位)。通常情况下,1个字节可以存储一个char,2个相邻的字节可以存储一个short,4个相邻的字节可以存储一个long。指针是能够存放地址的一组存储单元(通常是2个或4个字节)。因此,如果c是一个char,p是指向它的指针,则可用下图表示它们之间的关系:

注:
- 地址本质上就是一个整数,表示存储单元的编号,一般使用十六进制表示。假设地址范围为0~232-1,则可以使用32位无符号整数表示一个地址,指针为4字节
- 上图中变量c的地址是826,其中的值为97(即字符a);指针p的值为c的地址826,因此指针p 指向变量c
- 其他存储单元属于其他变量或者其他程序,而通过指针可以直接对任意的存储单元进行操作,因此使用指针必须非常小心
一元运算符&可用于取一个对象的地址,因此语句
1
p = &c;
将c的地址赋给变量p,称p为“指向”c的指针。地址运算符&只能用于内存中的对象,即变量与数组元素,不能用于表达式、常量或register变量。
一元运算符*是间接寻址(indirection)或解引用(dereference)运算符。当它作用于指针时,将访问指针所指向的对象。例如,假设x和y是整数,ip是指向int的指针,下面的代码段说明了如何声明指针以及如何使用运算符&和*:
1
2
3
4
5
6
7
int x = 1, y = 2, z[10];
int *ip; /* ip是指向int的指针 */
ip = &x; /* 现在ip指向x */
y = *ip; /* 现在y等于1 */
*ip = 0; /* 现在x等于0 */
ip = &z[0]; /* 现在ip指向z[0] */
指针ip的声明
1
int *ip;
是为了便于记忆:这表明表达式*ip是一个int。这种声明变量的语法与该变量所在表达式的语法类似。对函数的声明也可以采用这种方式。例如,声明
1
double *dp, atof(char *);
表明在表达式中,*dp和atof(s)的值都是double类型,且atof的参数是一个指向char类型的指针。
应该注意,每个指针都必须指向某种特定的数据类型(即指向int类型的指针不能指向char类型的变量)。(一个例外是指向void类型的指针可以存放指向任何类型的指针,但它本身不能被解引用,将在5.11节中讨论)
如果指针ip指向整型变量x,那么在x可以出现的任何上下文中都可以使用*ip。因此语句*ip = *ip + 10;将*ip(即x)的值增加10。
一元运算符*和&的优先级比算术运算符高,因此赋值语句y = *ip + 1;将把ip指向的对象的值取出并加1,然后再将结果赋值给y;而*ip += 1则将ip指向的对象的值加1,它等同于++*ip或(*ip)++的执行结果。表达式(*ip)++中的圆括号是必需的,否则该表达式将对ip而不是ip指向的对象进行加1运算,因为类似于*和++这样的一元运算符遵循从右到左的结合顺序(*ip++等价于*(ip++))。
最后,由于指针也是变量,所以可以不解引用而直接使用。例如,如果iq是另一个指向int的指针,则iq = ip将把ip中的值(地址)拷贝到iq中,这样指针iq将与ip指向同一个对象。
5.2 指针与函数参数
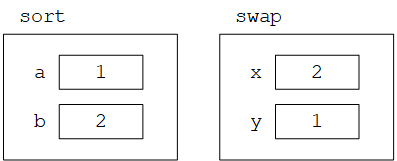
由于C语言是以传值的方式将参数传递给函数,因此被调函数不能直接修改主调函数中变量的值。例如,排序函数可能会使用一个名为swap的函数来交换两个元素。但是,如果将swap函数定义为
1
2
3
4
5
6
7
void swap(int x, int y) {
int temp;
temp = x;
x = y;
y = temp;
}
则语句swap(a, b);无法达到该目的。这是因为,由于传值调用,上述swap函数不会影响到实际参数a和b的值,它仅仅交换了a和b的副本(形式参数)的值,如下图所示:
要实现交换的目的,可以使主调函数将指向所要交换的变量的指针传递给被调函数,即:
1
2
3
4
5
6
7
8
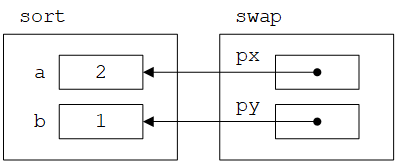
/* 交换*px和*py */
void swap(int *px, int *py) {
int temp;
temp = *px;
*px = *py;
*py = temp;
}
swap函数的参数声明为指针,并通过指针来间接访问操作数,此时调用swap(&a, &b);才能真正交换a和b的值,如下图所示:
注:4.10节中的swap函数能够成功交换数组元素,是因为数组名本身就是地址,详见5.3节
指针参数使得被调函数能够访问和修改主调函数中对象的值。考虑下面的例子:函数getint从输入的字符流中读取一个整数。getint需要返回转换后得到的整数,并且在到达输入结尾时要返回文件结束标记。这些值必须通过不同的方式返回,因为无论EOF用什么值表示,该值也可能是一个输入整数的值。(例如,如果读取的整数和EOF都通过返回值来返回,而EOF的值为-1,则调用函数无法区分-1是EOF还是输入的整数)
可以这样设计该函数:将标识是否达到文件结尾的状态作为getint函数的返回值,同时使用一个指针参数存储转换后得到的整数并传回给主调函数。函数scanf就采用了这种方法,详见7.4节。
例如,下面的循环语句通过调用getint函数给一个整型数组赋值:
1
2
3
4
int n, array[SIZE], getint(int *);
for (n = 0; n < SIZE && getint(&array[n]) != EOF; ++n)
;
每次调用getint时,输入流中的下一个整数将被赋值给数组元素array[n],同时n的值加1(例如:输入”123 456 789 回车 Ctrl+D”,则前3次调用getint分别得到整数123、456、789并赋值给array[0]~array[2],第4次调用getint将返回EOF,循环结束)。注意,这里必须将array[n]的地址&array[n]传递给getint函数,否则getint无法把转换得到的整数传回给调用者。
该版本的getint函数在到达文件结尾时返回EOF,当下一个输入不是数字时返回0,当输入中包含一个合法数字时返回一个正值。
在getint函数中,*pn始终作为一个普通的整型变量使用。其中还使用了getch和ungetch两个函数(见4.3节),从而多读入的一个字符可以被放回到输入中。
练习5-1 在上面的例子中,getint将后面不跟着数字的+或-视为数字0的有效表达方式。修改该函数,将这种字符放回到输入中。
练习5-2 模仿getint函数,编写一个读取浮点数的函数getfloat。getfloat函数的返回值应该是什么类型?
5.3 指针与数组
在C语言中,指针和数组之间的关系十分密切,因此接下来将同时讨论指针与数组。通过数组下标能完成的任何操作都可以通过指针来实现。 一般来说,用指针编写的程序执行速度更快,但更难理解。
声明int a[10];定义了一个长度为10的数组a,即10个连续的对象组成的一块内存区域,名字分别为a[0]、a[1]、…、a[9],如下图所示:

a[i]表示该数组的第i个元素。如果pa是一个指向整数的指针,声明为int *pa;,则赋值语句pa = &a[0];将pa指向数组a的第0个元素,也就是说pa的值为a[0]的地址,如下图所示:
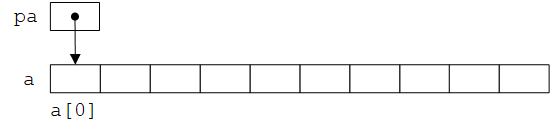
这样,赋值语句x = *pa;将把a[0]的值赋值到变量x中。
★如果pa指向数组中的某个元素,那么根据定义,pa+1指向下一个元素,pa+i指向pa之后的第i个元素,pa-i指向pa之前的第i个元素。因此,如果pa指向a[0],则pa+i是a[i]的地址,*(pa+i)是a[i]的值,如下图所示:
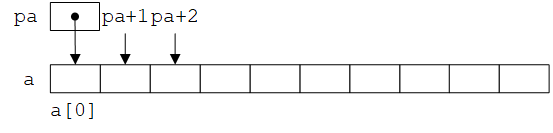
无论数组元素的类型或大小是什么,上面的结论都成立。“指针加1”就意味着指向下一个对象(实际上地址值之差为该类型对象的大小,例如pa指向int类型,则pa+1与pa的实际值之差为4)。例如,假设pa的值为0x9F36FAE8,则pa+1的值为0x9F36FAE8+1*sizeof(int)=0x9F36FAE8+4=0x9F36FAEC。
下标和指针运算之间具有密切的对应关系。根据定义,数组类型的变量或表达式的值是该数组第0个元素的地址,即数组名就是数组首元素的地址。因此,赋值语句pa = &a[0];等价于pa = a;。例如,在Visual Studio调试窗口可以看到:

★a[i]也可以写成*(a+i)。在对a[i]进行求值时,C语言实际上先将其转换为*(a+i)的形式,这两种形式是等价的。如果对这两种等价的形式分别施加地址运算符&,便可得到:&a[i]和a+i也是等价的,a+i是a之后第i个元素的地址。相应的,如果pa是一个指针,那么在表达式中也可以在它的后面加下标:pa[i]等价于*(pa+i)。简而言之,一个通过数组和下标实现的表达式可等价地通过指针和偏移量实现。
但是必须记住,数组名和指针之间有一个不同之处:指针是一个变量,因此pa=a和pa++都是合法的;但数组名不是变量,因此a=pa和a++是非法的。
注:也不能将一个数组赋值给另一个数组,例如:
1
2
int a[4] = {0, 1, 2, 3}, b[4];
b = a; /* 错误 */
当把数组名传递给一个函数时,实际上传递的是该数组首元素的地址。在被调用函数中,数组参数是一个指针。可以利用这一特性编写strlen函数的另一个版本:
因为s是一个指针,所以对其执行自增运算是合法的。执行++s不会影响到调用函数中的字符串,而只对strlen函数中的私有副本进行自增运算。因此,类似于下面的函数调用都可以正确执行:
1
2
3
strlen("hello, world"); /* 字符串常量 */
strlen(array); /* char array[100]; */
strlen(ptr); /* char *ptr; */
在函数定义中,形式参数char s[]和char *s是等价的。通常更习惯于后一种形式,因为它更直观地表明了该参数是一个指针。将一个数组名或指针传递给函数,对函数来说是一样的。
使用指向子数组起始位置的指针可以将数组的一部分传递给函数。例如,如果a是一个数组,则f(&a[2])和f(a+2)都将把起始于a[2]的子数组的地址传递给函数f。在函数f中,形式参数可以声明为f(int arr[]) { ... }或f(int *arr) { ... }。对于函数f来说,它并不关心参数引用的是否只是一个更大数组的一部分。
如果确信元素存在,也可以使用负数下标。例如,假设指针p指向数组元素a[5],则p[-1]和p[-2]分别引用a[4]和a[3]。当然,引用数组边界之外的对象是非法的(例如a[-1]、p[-10])。
5.4 地址算术运算
如果p是一个指向数组中某个元素的指针,那么p++将自增p使其指向下一个元素,p+=i将自增p使其指向当前指向的元素之后的第i个元素。这类运算是指针或地址算术运算最简单的形式。
C语言中的地址算术运算方法是一致且有规律的,将指针、数组和地址算术运算集成在一起是该语言的一大优点。为了说明这一点,下面编写一个简单的存储分配程序(用数组和指针来模拟操作系统的内存分配)。该程序由两个函数组成。第一个函数alloc(n)返回一个指向n个连续字符存储单元的指针,alloc函数的调用者可利用该指针存储字符序列。第二个函数afree(p)释放已分配的存储空间,以便以后重用。之所以说这两个函数是“简单的”(rudimentary),是因为调用afree函数的次序必须与alloc函数相反。换句话说,alloc和afree管理的存储空间是一个栈。标准库<stdlib.h>提供了具有类似功能的函数malloc和free,它们没有上述限制。
注:“次序相反”的意思是alloc和afree函数必须按以下方式使用:
1
2
3
4
5
6
7
char *p1 = alloc(5);
char *p2 = alloc(10);
char *p3 = alloc(3);
/* 使用p1, p2和p3 */
afree(p3);
afree(p2);
afree(p1);
或者
1
2
3
4
5
6
7
8
char *p1 = alloc(5);
char *p2 = alloc(10);
/* 使用p1和p2 */
afree(p2);
char *p3 = alloc(3);
/* 使用p3 */
afree(p3);
afree(p1);
即afree的参数必须是上一次调用alloc返回的指针。
最简单的实现方式是让alloc函数对一个大字符数组allocbuf中的空间进行分配。该数组是alloc和afree两个函数私有的数组,因此将其声明为static。
allocbuf中的空间使用状况也是需要了解的信息。使用指针allocp指向allocbuf中的下一个空闲单元。当调用alloc申请n个字符的空间时,alloc检查allocbuf中有没有足够的剩余空间。如果有,则alloc返回allocp的当前值(即空闲块的开始位置),然后将allocp加n使其指向下一个空闲区域。如果空闲位置不够,则alloc返回0。afree(p)仅仅是将allocp的值设置为p,前提是p在allocbuf的边界之内。
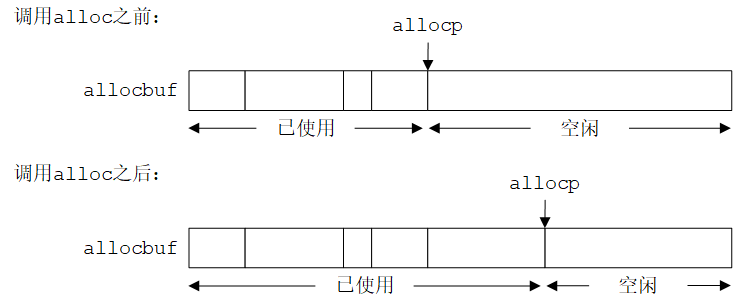
一般来说,指针和其他变量一样可以初始化,但有意义的初始化值只有0和表示此前已定义的具有适当类型的数据地址的表达式。例如,声明static char *allocp = allocbuf;定义了一个字符指针allocp,并将其初始化为allocbuf的起始地址。
测试语句if (allocbuf + ALLOCSIZE - allocp >= n)检查是否有足够的空闲空间来满足n个字符的请求。如果有足够的空间,则allocp的新值至多是allocbuf的尾端地址加1。如果请求可以满足,alloc将返回一个指向所需大小的字符块首地址的指针。如果请求无法满足,alloc必须返回某种信号以说明没有剩余空间。C语言保证0永远不是有效的数据地址,因此返回值0可用于表示发生了异常事件。
以下是使用这两个函数的一个示例程序(为便于说明,假设ALLOCSIZE为10):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
#include <stdio.h>
#include <string.h>
#include "alloc.h"
int main() {
char *p1 = alloc(6);
strcpy(p1, "hello");
printf("%s\n", p1);
char *p2 = alloc(3);
strcpy(p2, "42");
printf("%s\n", p2);
afree(p2);
char *p3 = alloc(4);
strcpy(p3, "ABC");
printf("%s\n", p3);
printf("%p\n", alloc(1));
afree(p3);
afree(p1);
return 0;
}
这段程序将输出
1
2
3
4
hello
42
ABC
0
执行过程中allocbuf和allocp的状态如下:
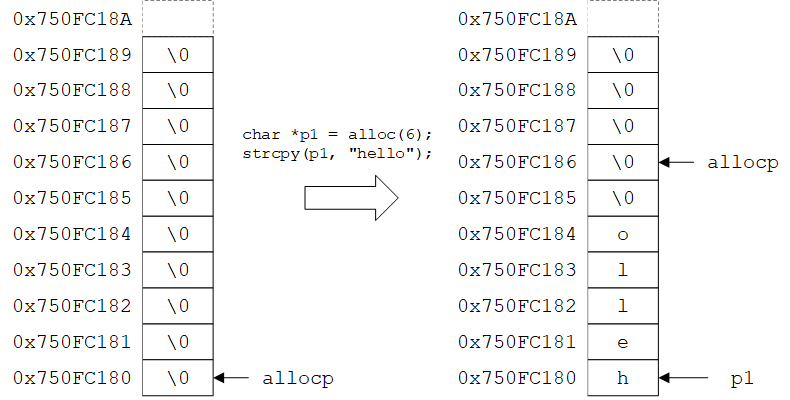
(1)假设allocbuf数组的首地址为0x750FC180,大小为10,则该数组的地址范围为0x750FC180~0x750FC189。最后一个元素的下一个位置为0x750FC18A,用虚线表示。由于该数组被声明为static,因此所有元素均初始化为0(即字符'\0')。allocp的值为0x750FC180,即指向数组首地址。
(2)语句char* p1 = alloc(6);分配了6个字节的空间,返回首地址0x750FC180并赋值给指针p1;并将allocp加6,指向下一个空闲位置0x750FC186。指针p1可以视为一个长度为6的字符数组,可以使用strcpy函数将字符串"hello"拷贝到该数组中。注意:分配给p1的地址范围为0x750FC180~0x750FC185,但C语言并没有任何机制来防止通过该指针操作这个地址范围以外的存储单元。例如,如果拷贝的字符串长度大于5,则会覆盖后面的存储单元。这就是使用指针的危险性,保证地址不越界只能靠自觉。
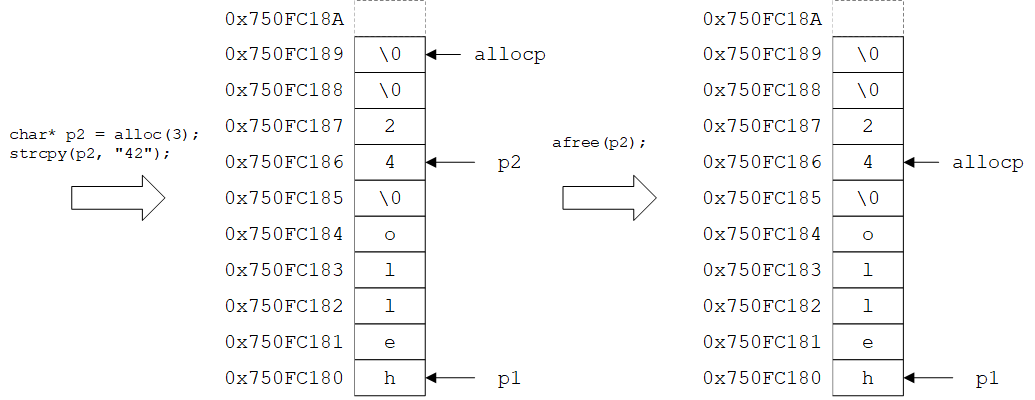
(3)语句char *p2 = alloc(3);分配3个字节的空间给指针p2,并向其中写入字符串"42"。此时p2的值为0x750FC186,allocp的值为0x750FC189。之后调用afree(p2);将分配给p2的空间释放,该操作仅仅是将allocp的值置为p2(即0x750FC186),使得这3个字节的空间变成空闲区域。由此也可以看出为什么调用afree函数的次序必须与alloc函数相反:如果先调用afree(p1),则会将allocp的值置为p1(即0x750FC180),使得分配给p2的空间变成空闲区域,从而可能被分配给其他指针,导致其中的内容被覆盖。另一方面,已经被释放的指针就不应该再使用,否则可能会覆盖分配给其他指针的区域中的内容(这也只能靠自觉来保证)。
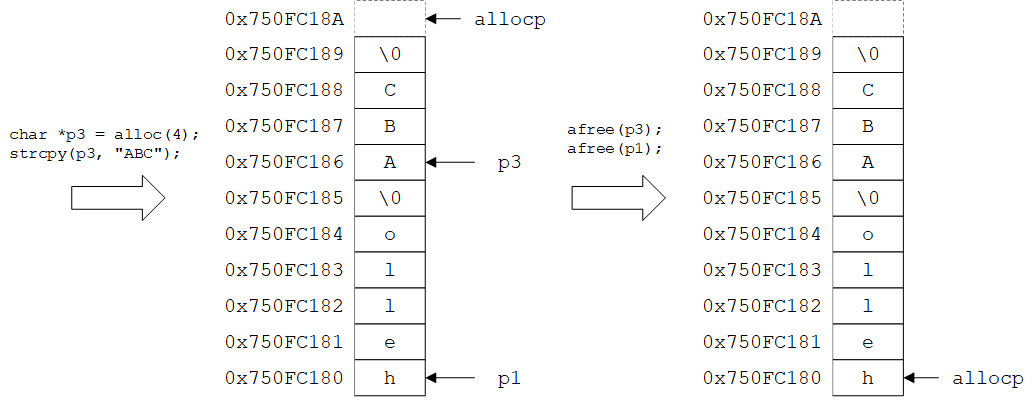
(4)语句char *p3 = alloc(4);分配3个字节的空间给指针p3,并向其中写入字符串"ABC"(此时如果仍然使用指针p2,则会覆盖分配给p3的空间,或者被通过p3写入的内容覆盖)。分配前,由于剩余空间大小allocbuf + ALLOCSIZE - allocp = 0x750FC180 + 10 - 0x750FC186 = 0x750FC18A - 0x750FC186,刚好等于4,因此分配成功。之后再调用alloc(1)时没有剩余空间,因此直接返回0。
指针与整数之间不能相互转换,但0是唯一的例外:常量0可以赋值给指针,也可以与指针进行比较。程序中经常使用符号常量(宏)NULL代替常量0(表示空指针),该常量定义在标准头文件<stdio.h>中。
类似于if (allocbuf + ALLOCSIZE - allocp >= n)和if (p >= allocbuf && p < allocbuf + ALLOCSIZE)的条件测试语句表明指针算术运算具有以下几个重要特点:
- 在某些情况下可以对指针进行比较运算。如果指针p和q指向同一个数组的成员,那么可以进行
==、!=、<、<=、>和>=的关系比较运算。例如,如果p指向的数组元素在q之前,则p < q为真。任何指针与0进行相等或不相等的比较都有意义。但是,指向不同数组的元素的指针之间的算术运算或比较运算没有定义(特例:数组最后一个元素的下一个元素的地址可用于指针算术运算)。 - 指针和整数可以相加或相减。 例如,
p + n表示指针p当前指向的对象之后第n个对象的地址。无论指针p指向的对象是何种类型,上述结论都成立。n将根据p指向的对象的长度按比例缩放,而该长度取决于p的声明。 - 指针的减法运算也是合法的:如果p和q指向同一个数组的元素,且
p < q,那么q - p就是位于p和q指向的元素之间的元素数目(左闭右开)。利用这一性质可以编写函数strlen的另一个版本:
字符串中的字符数有可能超过int类型所能表示的最大范围。头文件<stddef.h>中定义的类型ptrdiff_t(等价于long)足以表示两个指针之间的带符号差值。标准库<string.h>中的strlen函数的返回值类型为size_t(等价于unsigned long),这也是sizeof运算符的返回类型。
指针的算术运算具有一致性:如果处理的是比char占据更多存储空间的float,并且p是一个指向float的指针,则p++将移动到下一个float。因此,只需将alloc和afree函数中所有的char改为float,就可以得到一个适用于float类型的内存分配函数。所有的指针运算都会自动考虑它所指向的对象长度。
总结:有效的指针运算包括同类型指针之间的赋值、指针和整数的相加和相减、指向同一个数组中元素的指针之间的减法或比较、将指针赋值为0或与0之间的比较。其他所有形式的指针运算都是非法的,例如两个指针之间的加法、乘法、除法或位运算,指针与float或double之间的加法,以及不经强制类型转换而直接将一种类型的指针赋值给另一种类型的指针(void *除外)。
5.5 字符指针与函数
字符串常量是一个字符数组,例如:"I am a string"。在内部表示中,字符数组以空字符'\0'结尾,因此程序可以找到字符串结尾。字符数组的长度也因此比双引号内的字符数大1。
字符串常量最常见的用法也许是作为函数参数,例如:printf("hello, world\n);。字符串常量是通过指向其第一个元素的指针访问的。
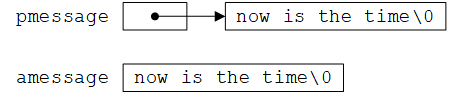
假设指针pmessage的声明为char *pmessage;,则语句pmessage = "now is the time";将一个指向字符数组的指针赋值给pmessage。该过程并没有进行字符串的赋值,而只是涉及到指针的操作。C语言没有提供将整个字符串作为一个整体进行处理的运算符。
下面两个定义之间有很大的差别:
1
2
char amessage[] = "now is the time"; /* 一个数组 */
char *pmessage = "now is the time"; /* 一个指针 */
上述声明中
amessage是一个大小刚好足以存放初始化字符串(包括'\0')的一维数组(长度为16),数组中的单个字符可以修改,但amessage始终指向同一个存储位置pmessage是一个指针,其初值指向一个字符串常量(其中的字符存储在另外的某个位置),之后它可以被修改以指向其他地址,但如果试图修改字符串的内容,结果是没有定义的
为了更进一步地讨论指针和数组其他方面的问题,下面研究标准库中两个有用的函数的不同实现版本。第一个函数strcpy(s, t)将字符串t拷贝到字符串s中。s = t拷贝是的指针,不是字符串。为了拷贝字符串,需要一个循环。第一个版本使用数组下标:
为了进行比较,下面是指针版本的strcpy:
因为参数是通过值传递的,所以在strcpy函数中可以以任何方式使用参数s和t(对其进行自增不影响实参数组的地址,但通过解引用和赋值可以修改数组元素的值)。在这里,s和t是使用数组初始化的指针,每次循环都沿着相应的数组前进一个字符,直到将t中的结束符'\0'复制到s为止。
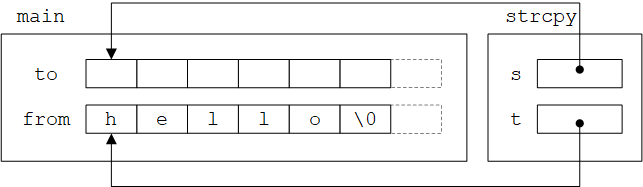
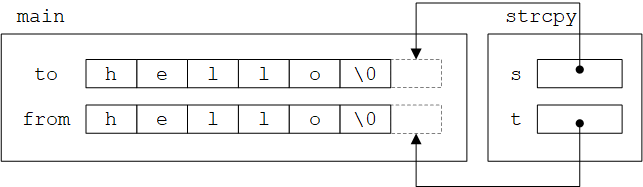
对于以下程序:
1
2
3
4
5
int main() {
char *from = "hello";
char to[6];
strcpy(to, from);
}
调用strcpy前后,实参数组的内容以及形参s和t的值如下图所示:
实际上,strcpy函数并不会按照上面的这些方式编写。经验丰富的C程序员更喜欢下列形式:
该版本将s和t的自增运算放到循环的测试部分中。表达式*t++的值是t自增前指向的字符,后缀运算符++在读取该字符之后才改变t的值。同理,在s自增之前,字符就被存储到了指针s指向的旧位置。该字符同时也用来和'\0'进行比较,以控制循环的执行。最后的结果是依次将t中的字符复制到s,包括结束符'\0'。
为了进一步简化程序,注意到表达式与'\0'的比较是多余的,因为只需要判断赋值表达式的值(当前被拷贝的字符)是否为0即可('\0'的值为0)。因此,该函数可以写成下列形式:
该函数初看起来不太容易理解,但这种表示方式是很有好处的。应该掌握这种方法,因为在C语言程序中经常会采用这种写法。
标准库<string.h>中提供的strcpy函数把目标字符串作为函数返回值。
将要研究的第二个函数是strcmp(s, t)。该函数比较字符串s和t,并且在s按照字典顺序小于、等于或大于t时分别返回负数、0或正数。该返回值是s和t第一个不相等的字符的差值。
下面是strcmp的指针版本:
注:strcmp("abc", "abd")、strcmp("abc", "abc")、strcmp("abc", "ab")的返回值分别为'c' - 'd' = -1、'c' - 'c' = 0、'c' - '\0' = 99,但根据函数的功能描述,不需要关注具体值,只需要考虑正负即可。
由于++和--既可以作为前缀运算符,也可以作为后缀运算符,所以还可以将运算符*与++和--按照其他方式组合,尽管并不常用。例如,*--p先对p自减后读取p指向的值。事实上,下面的两个表达式
1
2
*p++ = val; /* 将val压入栈 */
val = *--p; /* 将栈顶元素弹出到val中 */
是压栈和弹栈的标准用法(详见4.3节)。
标准库<string.h>包含本节提到的函数以及其他一些字符串处理函数的声明。
练习5-3 用指针的方式实现第2章中的函数strcat:strcap(s, t)将字符串t拷贝到s尾部。
练习5-4 编写函数strend(s, t),如果字符串t出现在s的尾部则返回1,否则返回0。
练习5-5 实现库函数strncpy、strncat和strncmp,它们对参数字符串的最多前n个字符进行操作。例如,strncpy(s, t, n)将t中最多前n个字符拷贝到s(如果n小于等于t的长度则不会拷贝结尾的'\0',因此拷贝后的s可能不是一个合法的C字符串)。
练习5-6 采用指针而非数组索引的方式改写前面章节和练习中的某些程序,例如getline(第1、4章),atoi、itoa以及它们的变体(第2、3、4章),reverse(第3章),strindex、getop(第4章)等等。
5.6 指针数组以及指向指针的指针
由于指针本身也是变量,所以可以像其他变量一样存储在数组中。下面通过UNIX程序sort的一个简化版本说明这一点。该程序对一组文本行按字母顺序排序。
例如:假设文件test.txt的内容为
1
2
3
4
foo
bar
baz
foobar
则在命令行执行sort test.txt将输出
1
2
3
4
bar
baz
foo
foobar
第3章给出了一个用于排序整数数组的Shell排序函数,并在第4章用快速排序算法对它进行了改进。这些排序算法再次仍然是有效的,但是现在要比较的对象不是整数而是长度可变的文本行(字符串)。与整数不同的是,字符串不能在单个运算中完成比较(<)或移动(=)操作。我们需要一个能够高效、方便地处理变长文本行的数据表示方式。
可以使用指针数组处理这种问题。如果待排序的文本行首尾相连地存储在一个长字符数组中(注:这是因为读入的文本行存储在由5.4节介绍的alloc函数分配的存储中,这个“长字符数组”实际上就是allocbuf),那么每个文本行可通过指向它第一个字符的指针来访问。这些指针本身可以存储在一个数组中。这样,将指向两个文本行的指针传递给strcmp函数即可实现对这两个文本行的比较。当交换次序颠倒的两个文本行时,实际上交换的是指针数组中的指针,而不是文本行本身。
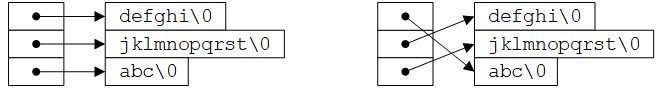
这种方法消除了移动文本行本身所带来的复杂的存储管理和巨大的内存开销(由于地址本质上就是一个整数,因此交换指针与交换整数一样容易)。
排序过程包括以下三步:
1
2
3
读取所有输入行
对文本行进行排序
按次序打印文本行
通常情况下,最好将程序划分成与问题的自然划分相一致的函数,并通过主函数控制其他函数。
输入函数必须收集并保存每个文本行,并建立一个指向这些文本行的指针数组。同时它还必须统计输入的行数,因为在排序和打印时需要这一信息。由于输入函数只能处理有限数目的输入行(指针数组的大小),所以在输入行数过多时,该函数返回一个非法的行数,例如-1。
输出函数只需按照指针数组的次序依次打印这些文本行即可。
主要的新概念是lineptr的声明:char *lineptr[MAXLINES],它表示lineptr是一个具有MAXLINES个元素的数组,每个元素是一个指向char的指针。也就是说,lineptr[i]是一个字符指针(可表示一个文本行,即字符串),*lineptr[i]是第i个文本行的第一个字符。
由于lineptr本身是一个数组名,可以将其作为指针使用,因此writelines函数可以改写为
1
2
3
4
5
/* writelines:写输出行 */
void writelines(char *lineptr[], int nlines) {
while (nlines-- > 0)
printf("%s\n", *lineptr++);
}
注:
- 在
readlines函数中,将当前行读入数组line中,但该数组是局部变量,在readlines函数退出后就会消失,因此使用strcpy将其拷贝到通过alloc函数分配的、指针p指向的存储区域中 - 排序前文本行在内存中的实际存储情况如下图所示:
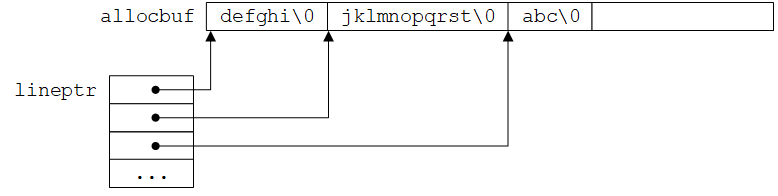
为了实现文本行的排序,需要对第4章的快速排序函数做一些小改动:首先需要修改声明(参数v改为char *v[]);其次需要调用strcmp完成文本行的比较。除此之外的算法部分不需要做任何改动。同样,swap函数也只需要做一些很小的改动。
练习5-7 重写函数readlines,将输入的文本行存储到由main函数提供的一个数组中,而不是调用alloc分配的存储空间。程序比改写前快多少?
(似乎更慢了?测试数据为4000行长度为500的随机字符串,运行100次,改写前2.39 s,改写后2.56 s)
5.7 多维数组
C语言提供了类似于矩阵的多维数组。
考虑一个日期转换的问题:把某月某日转换为一年中的第几天,反之亦然。例如,3月1日是非闰年的第60天,是闰年的第61天。定义两个函数来进行日期转换:day_of_year将月和日转换为指定年份的第几天,month_day将指定年份的第几天转换为月和日。因为后一个函数需要计算两个值,因此月和日这两个参数是指针。例如,month_day(1988, 60, &m, &d)将m设置为2、d设置为29(2月29日)。
这些函数都要用到一张记录每月天数的表。由于闰年和非闰年2月的天数不同,所以将这些天数分别存放在一个二维数组中的两行比在计算过程中判断2月有多少天更容易。该数组及转换函数如下:
前面讲过,逻辑表达式的值只可能是0(假)或1(真),因此leap可以用作数组daytab的下标。
数组daytab必须在函数day_of_year和month_day的外部声明,使得这两个函数都可以使用该数组。这里之所以将daytab的元素类型声明为char,是为了说明在char类型的变量中存放较小的非字符整数也是合法的。
在C语言中,二维数组实际上是一维数组,它的每个元素也是一维数组。 因此,数组下标应该写成daytab[i][j]而不是daytab[i, j]。数组元素按行存储,因此按照存储顺序访问元素时,最右边的下标(即列)变化得最快。
数组可以使用花括号括起来的初值表进行初始化,二维数组的每一行由相应的子列表进行初始化。在本例中,将数组daytab的第一列元素设置为0,这样月份的值为1~12,而不是0~11。由于在这里存储空间并不是主要问题,所以这种处理方式比调整数组的下标更加直观。
如果将二维数组作为参数传递给函数,那么在函数的参数声明中必须指明数组的列数,数组的行数没有太大关系。 因为函数调用时传递的是一个指向由行(row)构成的一维数组的指针,其中每个行是一个一维数组。
注:类比普通的一维数组
int a[13]定义a是具有13个int的数组,将其传递给函数f(int a[])或f(int *a)实际上传递的是指向首元素的指针,首元素类型为intint a[2][13]定义a是具有2个元素的数组,其中每个元素是具有13个int的数组,将其传递给函数f(int a[2][13])实际上传递是是指向首元素的指针,首元素类型为int [13]
如果将数组daytab传递给函数f,那么f的声明应该是
1
f(int daytab[2][13]) { ... }
也可以写成
1
f(int daytab[][13]) { ... }
因为数组的行数无关紧要,还可以写成
1
f(int (*daytab)[13]) { ... }
这表明参数是一个指向13个整型元素的数组的指针。因为方括号[]的优先级比*高,因此圆括号是必需的。如果没有圆括号,则声明int *daytab[13]是由13个指向整型的指针构成的数组。
一般来说,只有数组的第一维下标可以不指定大小,其余各维都必须指定。
5.12节将进一步讨论复杂声明。
练习5-8 函数day_of_year和month_day中没有进行错误检查,请解决该问题。
5.8 指针数组的初始化
考虑这样一个问题:编写一个函数month_name(n),它返回一个指向第n个月的名字的字符串的指针。这是内部static数组的一种理想的应用场景。
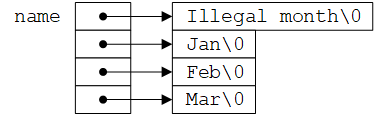
指针数组的初始化语法与普通数组类似。其中每个元素是一个字符指针,因此可以使用字符串常量初始化。第i个字符串存储在另外的某个位置,指向它的指针存储在name[i]中。由于没有指定数组name的长度,编译器将统计初值个数并填入数组长度。
5.9 指针数组与多维数组
对于C语言的初学者来说,很容易混淆二维数组与指针数组之间的区别。假设有以下定义:
1
2
int a[10][20];
int *b[10];
那么从语法上,a[3][4]和b[3][4]都是对一个int的合法引用。但a是一个真正的二维数组,它分配了200个int类型长度的存储空间,并且通过下标计算公式 20×row+col 计算得到元素a[row][col]的位置。但是,对于b来说,该定义仅仅分配了10个指针,并且没有初始化。指针数组的一个重要优点在于,数组的每一行长度可以不同。 也就是说,b的每个元素不必都指向长度为20的数组。
指针数组最频繁的用处是存放具有不同长度的字符串,比如month_name。下图比较了指针数组和二维数组的声明和图形化描述:
1
char *name[] = {"Illegal month", "Jan", "Feb", "Mar"};
1
char aname[][15] = {"Illegal month", "Jan", "Feb", "Mar"};
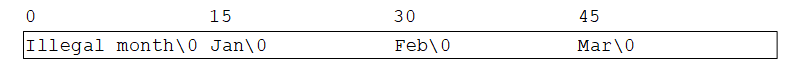
关于二维数组与指针的关系见博客:二维数组的行指针和列指针
练习5-9 用指针代替数组下标改写函数day_of_month和month_day。
5.10 命令行参数
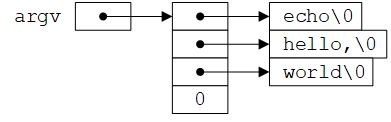
在支持C语言的环境中(例如Linux Shell命令行、Windows CMD命令行),可以在程序开始执行时向程序传递命令行参数(command-line arguments)。调用main函数时带有两个参数:第一个参数(习惯上称为argc, argument count)是命令行参数的数量;第二个参数(习惯上称为argv, argument vector)是一个字符串数组(对应的形参),其中每个字符串对应一个参数。
最简单的例子是程序echo,它将命令行参数原样打印在一行中,用空格分隔。也就是说,命令
1
echo hello, world
将打印以下输出:
1
hello, world
按照C语言的约定,argv[0]的值是程序名,因此argc至少为1。如果argc是1,则说明在程序名后没有命令行参数。在上面的例子中,argc为3,argv[0]、argv[1]和argv[2]的值分别为"echo"、"hello,"和"world"。除程序名外,命令行参数的个数为argc-1,第一个是argv[1],最后一个是argv[argc-1]。另外,ANSI标准要求argv[argc]必须是一个空指针。如下图所示:
第一个版本的echo程序将argv看成一个字符指针数组:
运行方式:
Windows
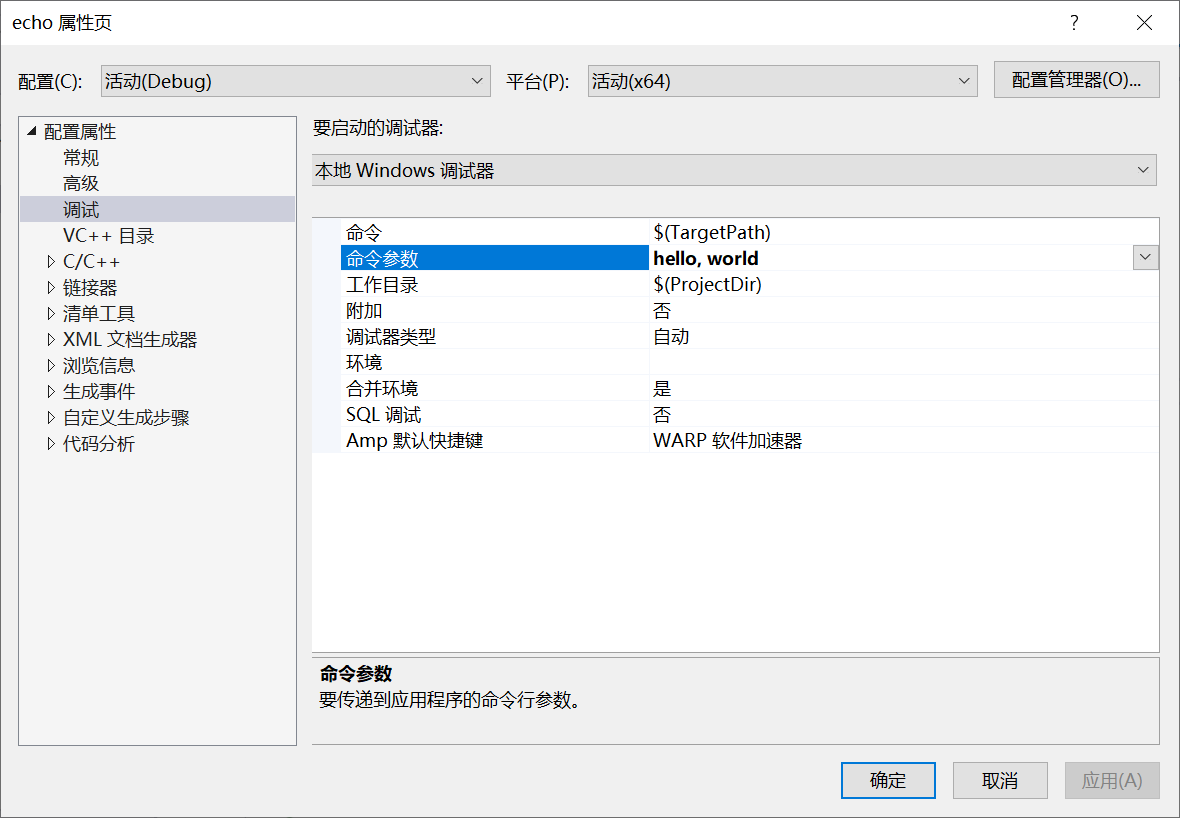
- 方法一:Visual Studio 选择“项目”菜单→“属性”,打开项目属性页,在“调试”中的“命令参数”中输入参数,点击确定后运行即可,如下图所示:
- 方法二:命令行 打开CMD窗口,进入项目生成的.exe文件所在目录,执行
echo.exe [参数]即可:
1
2
3
4
C:\Users\ZZy>cd "source\repos\C++\x64\Debug"
C:\Users\ZZy\source\repos\C++\x64\Debug>echo.exe hello, world
hello, world
Linux:将源文件编译为可执行文件(为了避免与系统命令echo冲突,这里将可执行文件命名为echo.out),执行./echo.out [参数]即可:
1
2
3
$ gcc -o echo.out echo.c
$ ./echo.out hello, world
hello, world
因为argv是一个指针,所以可以通过指针而非数组下标来处理命令行参数。echo程序的第二个版本是在对argv(指向char类型指针的指针)进行自增运算、对argc进行自减运算的基础上实现的:
由于argv是一个指向参数字符串数组起始位置的指针,因此自增1 (++argv)使其指向argv[1]而不是argv[0]。每次自增使得argv移动到下一个参数,*argv就是指向那个参数(首字符)的指针。同时,argc执行自减运算,当它变成0时,就完成了所有参数的打印。
也可以将printf语句写成以下形式:
1
printf(argc > 1 ? "%s " : "%s", *++argv);
注:命令行参数的作用在于在程序运行时向程序传递参数,如下面的例子所示
第二个例子将增强4.1节中模式查找程序的功能。在4.1节中,将查找模式内置(硬编码)到程序中了,这种解决方法显然不能令人满意。下面效仿UNIX程序grep来改写该程序,通过命令行的第一个参数指定待匹配的模式。
标准库函数strstr(s, t)返回一个指针,该指针指向字符串t在字符串s中第一次出现的位置,如果未出现则返回NULL。该函数声明在头文件<string.h>中。
为了进一步说明指针结构,下面改进模式查找程序。假定允许程序带两个可选参数:一个表示“打印除匹配模式之外的所有行”,另一个表示“在每个打印的行前面加上相应的行号”。
UNIX系统中的C语言程序有一个公共的约定:以负号(-)开头的参数表示一个可选标志(flag)或选项(option)。 假定用-x (except)表示第一个参数,用-n (number)表示第二个参数,那么命令find -x -n pattern将打印所有与模式不匹配的行,并在前面加上行号。
选项参数应该允许以任意次序出现。此外,如果选项参数能够组合使用将会很方便,例如find -nx pattern (即简写形式)。
改写后的模式查找程序如下:
注:外层循环用于遍历所有以”-“开头的参数,内层循环用于处理组合使用的选项参数(例如-nx)。
在处理每个选项参数之前,argc自减,argv自增。外层循环结束时,如果没有错误(例如:缺少模式参数find -n、模式参数和选项参数顺序颠倒find pattern -x等非法形式),则argc的值为还没有处理的参数数目,argv则指向第一个未处理参数。因此,argc应该为1,*argv应该是模式。注意,*++argv是一个参数字符串(类型为char *),因此(*++argv)[0]是它的第一个字符(等价于**++argv)。因为[]的优先级比*和++高,因此圆括号是必须的,否则该表达式将变成*++(argv[0])。实际上,在内层循环中就使用了该表达式,其目的是遍历一个特定的参数字符串。在内层循环中,表达式*++argv[0]对指针argv[0]进行了自增运算。
注:++argv和++argv[0]的效果如下图所示:
![++argv和++argv[0]](/assets/images/tcpl-note-ch5-pointers-and-arrays/++argv和++argv0.png)
很少有人会使用比这更复杂的指针表达式。如果遇到这种情况,将它们分为两步或三步会更直观一些。
练习5-10 编写程序expr,计算命令行参数中的逆波兰表达式的值,其中每个运算符或操作数用一个单独的参数表示。例如,命令expr 2 3 4 + *将计算表达式2×(3+4)的值。
练习5-11 修改程序entab和detab(练习1-20和1-21),使其接受一组制表符停止位作为参数。如果没有参数则使用默认的制表符停止位设置。
练习5-12 扩充entab和detab程序,使其接受缩写形式entab -m +n,表示制表符从第m列开始,每隔n列停止。选择(对于使用者而言)比较方便的默认行为。
练习5-13 编写程序tail,打印输入中的最后n行。默认情况下,n的值为10,但可以通过一个选项参数改变n的值,因此tail -n将打印输入中的最后n行。无论输入或n的值是否合理,该程序都应该能正常运行。编写的程序要充分利用存储空间;输入行的存储方式应该同5.6节中排序程序一样,而不是固定长度的二维数组。
5.11 指向函数的指针
在C语言中,函数本身不是变量,但可以定义指向函数的指针。这种类型的指针(与普通指针一样)可以被赋值、存放在数组中、传递给函数以及作为函数的返回值等等。为了说明指向函数的指针的用法,下面修改本章前面的排序程序,在给定选项参数-n时,将按数值顺序而不是字典顺序对输入行进行排序(例如,按字典顺序 “2” > “10”,按数值顺序2 < 10)。
排序程序通常由三部分组成:判断任意两个对象之间次序的比较操作、颠倒对象次序的交换操作,以及执行比较和交换操作直到所有对象都按正确顺序排列的排序算法。排序算法与比较和交换操作无关,因此通过将不同的比较和交换函数传递给排序算法,便可以实现按照不同的标准排序。这就是新版本排序程序所采用的方法。
strcmp按字典顺序比较两个输入行,这里还需要一个函数numcmp按数值顺序比较两个输入行、并返回与strcmp相同类型的状态指示(负数、0和正数分别表示小于、等于和大于)。这些函数在main之前声明,指向恰当函数的指针将被传递给qsort函数(有-n参数时选numcmp,否则选strcmp)。
在调用qsort函数的语句中,strcmp和numcmp是函数的地址。因为它们是函数,所以不需要&运算符。同样的原因,数组名前面也不需要&运算符。
注:取函数的地址时加不加&运算符都可以,因此以下写法是等价的:
1
2
int (*pf)(char *, char *) = &numcmp;
int (*pf)(char *, char *) = numcmp;
通过函数指针调用函数时,加不加*运算符也都可以,因此以下写法是等价的:
1
2
int x = (*pf)(s, t);
int x = pf(s, t);
改写后的qsort函数能够处理任何数据类型,而不仅限于字符串。从函数原型可以看出,qsort函数的参数包括一个指针数组、两个整数和一个有两个指针参数并返回整数的函数。指针数组参数的类型为通用指针类型 void *。由于任何类型的指针都可以转换为void *、并转换回原来的类型,而不会丢失信息,所以调用qsort函数时对指针数组和函数指针进行强制类型转换。这种转换通常不会影响数据的实际表示(指针的值),但可以确保编译器不会报错。
qsort函数的第四个参数声明为int (*comp)(void *, void *),它表明comp是一个指向具有两个void *参数、返回int的函数的指针。
在语句if ((*comp)(v[i], v[left]) < 0)中,comp的使用和声明是一致的:comp是一个指向函数的指针,*comp是一个函数,(*comp)(v[i], v[left])是对该函数的调用。其中的圆括号是必需的,否则int *comp(void *, void *)表明comp是一个返回指向int的指针的函数,与本意有很大差别。
numcmp函数通过atof计算的数值来比较字符串。
交换两个指针的swap函数与本章前面所述的相同,但它的参数声明为void *类型(为了配合qsort函数可用于任何数据类型)。
注:
- 新版本的
qsort函数确实可用于排序任何类型的数组,但使用起来有两个不方便的地方:- 必须提供一个指向原数组中每个元素的指针数组,而不是直接传递原数组,例如:如果要对一个
int数组排序,需要先构造一个对应的指针数组并传递给qsort - 对于基本类型的数组,仍然需要为每种类型提供不同的比较函数(因为
void *指针不能解引用)
- 必须提供一个指向原数组中每个元素的指针数组,而不是直接传递原数组,例如:如果要对一个
- 另外,标准库<stdlib.h>也提供了一个qsort函数,只需传递首元素的地址、元素个数以及每个元素的大小,而不需要构造完整的指针数组,因为这个指针数组实际上是一个等差数列,首项是首元素的地址,公差是每个元素的大小,因此只需给出首项、公差和项数(元素个数)即可得出每个元素的地址。但要注意:标准库qsort函数传递给比较函数的
void *参数是元素的指针,在排序文本行的例子中实际类型是char **,因此不能直接使用strcmp或numcmp作为比较函数,而必须定义一个“包装”函数:
1
2
3
int compare(const void *a, const void *b) {
return strcmp(*(char **) a, *(char **) b);
}
可以将其他一些选项增加到排序程序中,有些可以作为较难的练习。
练习5-14 修改排序程序,使其能处理-r选项,表示按逆序(递减顺序)排序。要保证-r和-n能够一起使用。
练习5-15 增加选项-f,使得排序过程不区分大小写(fold upper and lower case together)。例如,比较"a"和"A"时认为它们相等。
练习5-16 增加选项-d (directory order),只对字母、数字和空格进行比较。保证该选项可以和-f一起使用。
练习5-17 增加字段处理功能,使得可以对行内的字段进行排序,每个字段按照一组独立的选项进行排序。(对本书的索引排序时,索引类别使用-df,页码使用-n)
5.12 复杂声明
注:本节需要编译原理中自顶向下的语法分析作为知识背景,否则理解起来有些困难
C语言常常因为声明的语法而受到批评,特别是涉及到函数指针的语法。C语言的语法力图使声明和使用一致。对于简单的情况是很有效的,但是对于复杂的情况则容易让人混淆,原因在于声明不能从左到右阅读,而且使用了太多的圆括号。下面两个声明:
1
int *f(); /* f: function returning pointer to int (返回指向int的指针的函数) */
以及
1
int (*pf)(); /* pf: pointer to function returning int (指向返回int的函数的指针) */
它们之间的差别说明:*是一个前缀运算符,其优先级低于(),因此必须使用圆括号以保证正确的结合顺序。
尽管实际中很少用到过于复杂的声明,但是懂得如何理解甚至如何使用这些复杂声明是很重要的。一种比较好的方法是使用typedef通过简单的步骤合成声明,这种方法将在6.7节中讨论。作为替代方法,本节介绍两个程序:一个用于将正确的C语言声明转换为文字描述,另一个完成相反的转换。文字描述可以从左到右阅读。
第一个程序dcl复杂一些。它将C语言声明转换为文字描述,例如:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
char **argv
argv: pointer to pointer to char
int (*daytab)[13]
daytab: pointer to array[13] of int
int *daytab[13]
daytab: array[13] of pointer to int
void *comp()
comp: function returning pointer to void
void (*comp)()
comp: pointer to function returning void
char (*(*x())[])()
x: function returning pointer to array[] of
pointer to function returning char
char (*(*x[3])())[5]
x: array[3] of pointer to function returning
pointer to array[5] of char
注:对于像最后两个这样的复杂声明,可以从外往内阅读:
1
2
3
4
5
6
char (*(*x())[])()
*(*x())[] 返回char的函数
(*x())[] 指向上述函数的指针
*x() 上述指针的数组
x() 指向上述数组的指针
x 返回上述指针的函数
程序dcl是基于C语言声明语法(grammar)编写的。下面是其简化的形式:
1
2
3
4
5
dcl: 前面带有可选*的direct-dcl
direct-dcl: name
(dcl)
direct-dcl()
direct-dcl[可选的长度]
注:
- 这就是编译原理中的文法(grammar),其中
dcl和direct-dcl是非终结符,*、name、(、)、[、]、长度是终结符 - 这是一种递归的表示方法,语法分析的过程可使用语法分析树表示,见下
- 该语法中没有包含数据类型
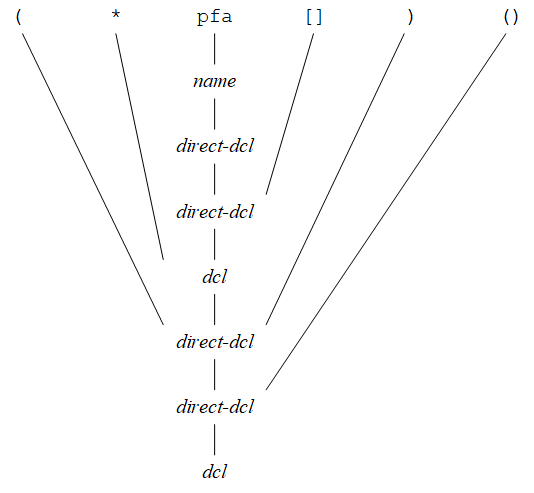
例如,考虑声明(*pfa[])(),可以用下图所示的语法分析树来说明分析过程:
程序dcl的核心是两个函数dcl和dirdcl,根据语法对声明进行分析。因为语法是递归定义的,所以在识别一个声明的组成部分时,这两个函数是相互递归调用的。我们称该程序是一个递归下降的语法分析器(recursive-descent parser)。
注:这两个函数就是利用了编译原理中自顶向下(递归下降)语法分析的基本思想
- 为每个非终结符编写一个可递归调用的处理函数
- 函数体按产生式的右端来编写,当遇到终结符时直接匹配,当遇到非终结符时就调用相应的处理函数
明白这一基本思想后,该程序就不难理解了。
该程序旨在说明问题,而不是尽善尽美(bullet-proof),因此对dcl有很多限制。它只能处理像char和int这样的简单数据类型,而无法处理函数中的参数类型或类似于const这样的限定符。它不能处理虚假的(spurious)空格(例如int f( )将被识别为语法错误)。由于没有完备的错误恢复,因此它也无法处理无效的声明。这些改进留作练习。
函数gettoken跳过空格与制表符,以查找输入中的下一个记号。“记号”(token)可以是一个名字、一对圆括号、可能包含数字的一对方括号,或其他任何单个字符。
注:书中给出的程序将所有函数和全局变量写在一起,即按照单个源文件的方式编写。从编译原理的角度,该程序可分为词法分析器(lexer)(gettoken函数)、语法分析器(parser)(dcl和dirdcl函数)和主程序三部分,因此可以将这些函数和对应的全局变量拆分到三个源文件中,如下图所示:

另一个方向的转换要容易一些,特别是如果不在乎生成多余的圆括号。程序undcl将类似于 “x is a function returning a pointer to an array of pointers to function returning char” 的文字描述表达为x () * [] * () char,并转换为char (*(*x())[])()。
由于对输入进行了简化,所以可以重用gettoken函数。undcl和dcl使用相同的外部变量。
下面是与dcl程序的示例对应的undcl程序的输入和输出:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
x int
int x
argv * * char
char (*(*argv))
daytab * [13] int
int (*daytab)[13]
daytab [13] * int
int (*daytab[13])
comp () * void
void (*comp())
comp * () void
void (*comp)()
x () * [] * () char
char (*(*x())[])()
x [3] * () * [5] char
char (*(*x[3])())[5]
练习5-18 修改dcl程序,使其能够从输入错误中恢复。
练习5-19 修改undcl程序,使其不会向声明中添加多余的圆括号。
练习5-20 扩展dcl程序,使其能够处理带有函数参数类型、类似于const的限定符等部分的声明。