《C程序设计语言》笔记 第6章 结构
结构(structure)是一个或多个变量的集合,这些变量可能是不同的类型,为了方便处理而组织在一个名字之下。由于结构将一组相关的变量看作一个单元而不是各自独立的实体,因此结构有助于组织复杂的数据,特别是在大型程序中。
结构的一个传统例子是工资记录:每个雇员由一组属性描述,如姓名、地址、社会保险号、工资等。其中的某些属性也可以是结构,例如姓名可以分成几部分,地址甚至工资也可能是这样。C语言中更典型的一个例子来自图形学:点由一对坐标定义,矩形由两个点定义,等等。
ANSI标准在结构方面最主要的变化是定义了结构的赋值操作——结构可以拷贝、赋值、传递给函数以及被函数返回。
6.1 结构的基本知识
首先来建立一下适用于图形学的结构。点是最基本的对象,有一个x坐标和一个y坐标,都是整数。
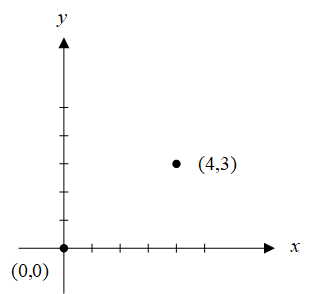
这两部分可以放在一个结构中,声明如下:
1
2
3
4
struct point {
int x;
int y;
};
关键字struct引入结构声明,由包含在花括号内的一系列声明组成。(注意不要忘记结尾的分号!)struct后面的名字是可选的,称为结构标记(structure tag)(这里是point)。结构标记用于为结构命名,后续可用作花括号内声明部分的简写形式(即:point等价于{ int x; int y; })。
结构中定义的变量称为成员(member)。结构成员、结构标记和普通(即非成员)变量可以使用相同的名字而不会冲突,因为可以通过上下文区分。另外,不同结构的成员可以使用相同的名字。但是,从编程风格方面来说,通常只有密切相关的对象才会使用相同的名字。
struct声明定义了一种数据类型。 在右花括号之后可以跟一个变量表,这与其他基本类型的变量声明是相同的。例如:
1
struct { ... } x, y, z;
在语法上类似于
1
int x, y, z;
这两个声明都将x、y和z声明为指定类型的变量,并为它们分配存储空间。
如果结构声明的后面不带变量表,则仅仅描述了结构的“模板”或“形状”。如果声明中带有结构标记,那么可以使用该标记定义结构实例(结构类型的变量)。例如,给定上面的point结构的声明,语句
1
struct point pt;
定义了一个struct point类型的变量pt(注意:类型名称是struct point而不是point)。
结构变量可以通过在定义的后面使用初值表进行初始化,每个成员对应的初值必须是常量表达式。 例如:
1
struct point maxpt = {320, 200};
注:
- 自动结构的初值也可以是表达式,静态结构和外部结构的初值必须是常量
- C语言并没有结构字面值,初值表
{320, 200}不能单独出现,例如f({320, 200})或者return {320, 200};(因为数组的初值表也是这样的,因此单独出现时无法确定其类型)
自动结构(即结构类型的自动变量)也可以通过赋值,或者调用返回相应结构类型的函数进行初始化(例如struct point q = p;)。
在表达式中,可以通过以下形式引用结构成员:
1
结构名.成员
结构成员运算符.将结构变量名与成员名连接起来。例如,下列语句打印点pt的坐标:
1
printf("%d,%d", pt.x, pt.y);
下列语句计算原点(0,0)到点pt的距离:
1
double dist = sqrt((double) pt.x * pt.x + (double) pt.y * pt.y);
结构可以嵌套。 矩形的一种表示方法是对角线上的两个点:
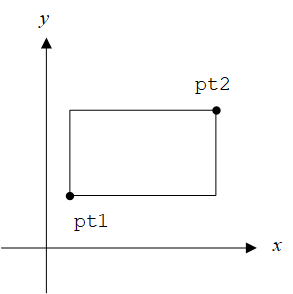
1
2
3
4
struct rect {
struct point pt1;
struct point pt2;
};
rect结构包含两个point结构。如果有声明struct rect screen;,则screen.pt1.x引用screen的成员pt1的x坐标。
嵌套的结构可以使用嵌套的初值表进行初始化,例如:
1
struct rect r = { {1, 2}, {3, 4} };
6.2 结构与函数
★结构的合法操作只有几种:拷贝和赋值(包括向函数传递参数和从函数返回值)、通过&取地址、访问成员。结构之间不能比较。 结构可以用一个常量成员值列表进行初始化,自动结构也可以通过赋值进行初始化。
为了进一步理解结构,下面编写几个操作点和矩形的函数。至少可以通过三种可能的方法传递结构:分别传递各成员、传递整个结构、传递指向结构的指针。每种方法各有利弊。
注:本节的代码都在以下两个文件中:
第一个函数makepoint接收两个整型参数,返回一个point结构。注意参数名和结构成员同名不会引起冲突,这里使用重名可以强调二者之间的关系。
注:由于自动结构的初值可以是表达式,因此makepoint函数中的temp变量可以直接声明为struct point temp = {x, y};,而省略后面的赋值语句。
现在可以使用makepoint函数动态地初始化point结构:
1
2
3
4
struct rect screen = {makepoint(0, 0), makepoint(1920, 1080)};
struct point middle = makepoint(
(screen.pt1.x + screen.pt2.x) / 2,
(screen.pt1.y + screen.pt2.y) / 2);
接下来编写一组对点执行算术运算的函数。例如,addpoint函数将两个点相加。其中函数的参数和返回值都是结构类型。之所以直接对p1的成员进行自增,而不是使用显式的临时变量,是为了强调结构类型的参数和其他类型的参数一样,都是通过值传递的。
另一个例子,函数ptinrect (point in rectangle)判断一个点是否在给定的矩形内部。这里采用了一个约定:矩形包括其左边和下边,不包括上边和右边(左闭右开)。
ptinrect函数假设矩形是用标准形式表示的,即pt1的坐标小于pt2的坐标。函数canonrect (canonical rectangle)返回一个保证是规范形式的矩形。
注:虽然在定义结构rect时期望pt1和pt2分别表示矩形的左下角和右上角,即标准形式,但并没有通过任何方式来保证这一点,使用者甚至可以将pt1和pt2分别设置为左上角和右下角。canonrect函数的作用是将一个(可能)不是标准形式的矩形转换为标准形式。
如果传递给函数的结构很大,传递指针通常比拷贝整个结构更高效。 结构指针类似于普通变量的指针。声明
1
struct point *pp;
表示pp是一个指向struct point类型的指针。如果pp指向一个point结构,那么*pp即为该结构,而(*pp).x和(*pp).y是其成员。可以按以下方式使用pp:
1
2
3
4
struct point origin, *pp;
pp = &origin;
printf("origin is (%d,%d)\n", (*pp).x, (*pp).y);
其中,(*pp).x的圆括号是必需的,因为结构成员运算符.的优先级比*高。表达式*pp.x等价于*(pp.x),因为x不是指针,因此是非法的。
结构指针的使用频度非常高,因此C语言提供了另一种简写形式。如果p是一个指向结构的指针,则
1
p->成员
引用相应的结构成员(->运算符像一个箭头,p->x可以读作“p指向的结构的成员x”)。因此上面的代码可以改写为
1
printf("origin is (%d,%d)\n", pp->x, pp->y);
运算符.和->都是从左到右结合的,因此对于
1
struct rect r, *rp = &r;
以下四个表达式是等价的:
1
2
3
4
r.pt1.x
rp->pt1.x
(r.pt1).x
(rp->pt1).x
在所有运算符中,结构运算符.和->、函数调用运算符()以及下标运算符[]的优先级最高。例如,给定声明
1
2
3
4
struct {
int len;
char *str;
} *p;
++p->len自增len而不是p,因为隐含的括号关系是++(p->len)(++p)->len先自增p再访问len(p++)->len先访问len再自增p(该表达式中的括号可以省略)*p->str读取的是str指向的值*p->str++先读取str指向的值,然后自增str(等价于*(p->str)++,类似于*s++)(*p->str)++将str指向的值自增*p++->str先读取str指向的值,然后自增p(等价于*p->str; p++)
6.3 结构数组
考虑编写一个程序来统计输入中各个C语言关键字的出现次数。需要用一个字符串数组存放关键字名,一个整型数组存放计数。一种实现方式是使用两个“平行”的数组(即相同下标的元素对应一个关键字的名字和出现次数):
1
2
char *keyword[NKEYS];
int keycount[NKEYS];
注意到这两个数组是平行的,因此考虑另一种组织方式——结构数组。每个关键字对应一对变量:
1
2
char *word;
int count;
多个这样的对构成一个数组:
1
2
3
4
struct key {
char *word;
int count;
} keytab[NKEYS];
声明了一个结构类型key,定义了一个该类型的结构数组keytab,并为其分配存储空间。数组keytab的每个元素都是一个结构。该声明也可以写成
1
2
3
4
5
6
struct key {
char *word;
int count;
};
struct key keytab[NKEYS];
因为数组keytab包含一个固定的名字集合,所以最好将它声明为外部变量,这样只需要初始化一次,所有地方都可以使用。结构数组的初始化方式也是在定义的后面跟着一个用花括号括起来的初值表,其中每个初值也是用花括号括起来的成员初值表(即结构的初值表):
1
2
3
4
5
6
7
struct key keytab[] = {
{"auto", 0},
{"break", 0},
{"case", 0},
...
{"while", 0}
};
关键字计数程序首先定义keytab。主程序反复调用函数getword,每次读取一个单词。每个单词通过二分查找函数(见第3章)在keytab中查找,关键字列表必须按升序排序。(注:这里的binsearch函数的参数类型和判断相等的条件与第3章的都不同,因此不能直接复用)
NKEYS是keytab中关键字的个数。尽管可以手工计算,但由机器实现会更简单、更安全,尤其是当列表可能变更时。一种方法是在初值表的结尾加上一个空指针,然后遍历keytab,直到遇到空指针(即strlen的原理)。
但实际上并不需要这样做,因为数组的长度在编译时已经完全确定。数组的长度 = 数组项的长度 * 项数,因此项数 = keytab的长度 / struct key的长度。
C语言提供了一个编译时(compile-time)一元运算符sizeof,可用于计算任何对象的长度。表达式sizeof 对象和sizeof(类型名)返回一个整数,它等于指定对象或类型占用存储空间的字节数。(严格地说,返回值是无符号整型值,其类型为size_t,该类型定义在头文件<stddef.h>中)其中,对象可以是变量、数组或结构;类型可以是基本类型,如int、double,也可以是派生类型,如结构或指针。
在该例子中,可使用下面的#define语句设置NKEYS的值:
1
#define NKEYS (sizeof keytab / sizeof(struct key))
另一种方法是用数组长度除以第一个元素的长度:
1
#define NKEYS (sizeof keytab / sizeof keytab[0])
这种方法的优点是,即使类型改变了也不需要改动程序。
注:这两种方法都只能在定义keytab的源文件中使用,在只有extern声明的源文件中sizeof keytab会报错“不允许使用不完整的类型”
条件编译语句#if中不能使用sizeof,因为预处理器不对类型名进行分析。但预处理器并不计算#define语句中的表达式(仅视为纯文本),因此在#define中使用sizeof是合法的。
getword函数从输入中读取下一个“单词”,单词可以是以字母开头的字母和数字串,也可以是一个非空白字符。函数返回值可能是单词的第一个字符、EOF或字符本身(如果不是字母)。
练习6-1 上述getword函数不能正确处理下划线、字符串常量、注释以及预处理器控制指令。请编写一个更完善的getword函数。
6.4 指向结构的指针
为了进一步说明结构指针和结构数组,下面重新编写关键字计数程序,这次使用指针而不是数组下标。
keytab的外部声明不需要修改,但main和binsearch函数必须修改。
首先,binsearch函数的返回值类型由整型改为指向struct key的指针,如果找到单词则返回指向它的指针,否则返回NULL。
其次,keytab的元素是通过指针访问的,这就需要对binsearch函数做较大的修改。low和high的初值分别是指向首元素和尾元素后面一个元素的指针(这意味着查找区间由[low, high]改为[low, high),因此while循环的判断条件由low <= high改为low < high)。因此,中间元素不能通过mid = (low + high) / 2计算,因为两个指针相加是非法的。但是指针相减是合法的,high - low就是数组元素的个数(前提是high指向尾元素的下一个元素 tab[n]而不是尾元素tab[n-1]),因此mid = low + (high - low) / 2将mid设置为指向low和high之间的中间元素的指针。
最重要的修改在于,确保不会生成非法的指针,或者试图访问数组范围之外的元素。例如,&tab[-1]和&tab[n]都超出了数组tab的范围。前者是绝对非法的;对后者解引用是非法的,但可以取地址。C语言的定义保证数组末尾之后的第一个元素的指针算术运算(即&tab[n])可以正确执行。
与普通指针一样,结构指针的算术运算需要考虑结构的长度。因此main函数中执行p++时指针值实际增加了sizeof(struct key)。
不要认为结构的长度等于各成员长度的和。 因为不同的对象的对齐要求,结构中可能会出现未命名的“空洞”。例如,假设char占1个字节,int占4个字节,则结构
1
2
3
4
struct {
char c;
int i;
};
可能需要8个字节,而不是5个,如下图所示。使用sizeof运算符可以返回正确的对象长度。

注:
- 结构成员本质上是一个偏移量,表示成员变量地址与结构变量地址的相对位置
- 成员的顺序不同也可能导致结构的长度不同,例如:
1
2
3
4
5
6
7
8
9
10
11
struct a {
char c;
int i;
double d;
};
struct b {
char c;
double d;
int i;
};
则sizeof(struct a) == 16, sizeof(struct b) == 24,如下图所示:

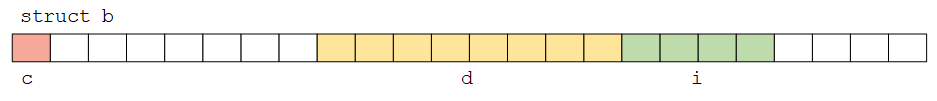
6.5 自引用结构
假设需要处理一个更通用的问题:统计输入中所有单词的出现次数。因为预先不知道单词列表,所以无法方便地排序并使用二分查找;也不能对每个输入的单词执行一次线性查找,看它在前面是否已经出现,这样程序执行将花费太长的时间。(更准确地说,运行时间随着输入单词数呈二次方增长,即O(n²))如何组织数据才能有效地处理任意的单词列表?
一种解决方法是,在读取输入单词的同时就将它放到正确的位置,从而始终保证所有出现过的单词都是按顺序排列的。但这不能通过在线型数组中移动单词来实现——这样仍然花费太长的时间。可以使用一种称为二叉树(binary tree)的数据结构。
每个不同的单词在树中都是一个节点(node),每个节点包含:
- 一个指向该单词文本的指针
- 一个统计出现次数的计数值
- 一个指向左子树的指针
- 一个指向右子树的指针
任何节点最多拥有两个子节点,也可能只有一个或没有。
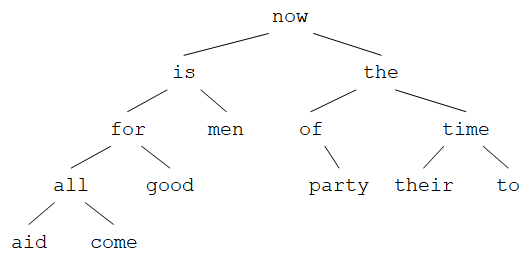
对节点的所有操作要保证:任何节点的左子树只包含按字典序小于该节点中单词的那些单词,右子树只包含按字典序大于该节点中单词的那些单词(二叉搜索树,BST)。例如,下图是按序插入句子 “now is the time for all good men to come to the aid of their party” 中各单词后生成的树:
由于二叉树是递归定义的,因此非常适合递归操作。
要查找一个新单词是否已经在树中,从根节点开始,比较新单词与该节点中的单词。若匹配,则得到肯定的答案;若新单词小于该节点中的单词,则在左子树中继续查找,否则在右子树中查找。如果在搜寻反向上无子树,则说明新单词不在树中,并且当前的空位置就是存放新单词的正确位置。因为从任意节点出发的查找都要按照相同的方式查找它的一个子节点,所以该过程是递归的。相应地,在插入和打印操作中使用递归也是很自然的。
查找操作的伪代码如下:
1
2
3
4
5
6
7
8
9
10
bool search(root, word) {
if (root == NULL)
return false
if (word == root.word)
return true
else if (word < root.word)
return search(root.left, word)
else
return search(root.right, word)
}
上面的查找操作仅返回是否存在(true或false),对其稍加改造即可实现插入、删除等功能(例如下面的addtree函数),而基本框架不会改变,因为这对应了二叉搜索树的性质。
节点可以用具有4个成员的结构来表示:
1
2
3
4
5
6
7
/* 树的节点 */
struct tnode {
char *word; /* 指向单词的指针 */
int count; /* 出现次数 */
struct tnode *left; /* 左子节点 */
struct tnode *right; /* 右子节点 */
};
对于节点的这种递归的声明看上去好像是不确定的,但它的确是正确的。一个包含其自身实例的结构是非法的(因为无法计算结构的长度),但结构可以包含指向自身类型的指针(因为指针的长度是固定的)。结构tnode包含两个指向tnode类型的指针left和right(这就叫自引用结构)。
偶尔也会使用自引用结构的一种变体:两个结构相互引用:
1
2
3
4
5
6
7
8
struct t {
...
struct s *p;
};
struct s {
...
struct t *q;
};
有了一些支持函数(例如前面编写的getword)后,整个程序的代码非常短。主函数通过getword读取单词,并使用addtree将它们插入到树中。
注:本节给出了一个抽象数据类型(ADT):二叉树,ADT=数学模型+操作
- 数学模型:
tnode结构 - 操作:插入
addtree、打印treeprint
函数addtree是递归的。该函数的基本思想与上面所述的查找操作相同:将单词与根节点中的单词进行比较,并递归地转向左子树或右子树。与查找操作不同的是,addtree函数在单词与树中已有节点匹配时将计数值加1;在遇到空指针时创建一个新节点并加入树中,返回指向新节点的指针,该指针保存在父节点中。
新节点的存储空间由talloc函数获得,该函数返回一个指针,指向能容纳一个tnode的空闲空间。创建新节点时,计数值被初始化为1,单词指针使用strdup函数初始化,两个子节点指针初始化为空。函数strdup将单词复制到某个隐藏位置。该程序忽略了对strdup和talloc返回值的错误检查(这显然是不完善的)。
注:不能直接用strcpy,因为新节点的单词指针是未初始化的指针,并没有“附带”存储空间。如果tnode的word成员是一个字符数组则可以这样做,但那样太浪费存储空间。
tprint函数按顺序打印树。在每个节点,先打印左子树(小于该单词的所有单词),然后是该单词本身,最后是右子树(大于该单词的所有单词)。(这就是二叉树的中序遍历,二叉搜索树的中序遍历是有序序列)
注意:如果单词不是按照随机的顺序到达的,树将变得不平衡,这种情况下程序的运行时间将大大增加。最坏情况下,如果单词已经排好序,则程序将退化为线性查找。某些广义二叉树(AVL树)不受这种最坏情况的影响,在此不讨论。
talloc函数使用了标准库<stdlib.h>的存储分配函数malloc。函数malloc分配一块指定大小的存储空间,并返回指向它的指针。由于该函数需要处理多种类型的请求(例如指向char的指针和指向struct tnode的指针),在C语言中,一种合适的方法是将malloc函数的返回值声明为void *,然后再显式地将该指针强制转换为所需类型:
1
void *malloc(size_t size);
注:malloc函数并不关心分配的空间用于存储什么类型的对象,如何使用分配的空间完全由调用者决定。
talloc函数仅仅是调用malloc函数分配一块struct tnode大小的空间并返回其指针。strdup函数只是把参数字符串拷贝到一块由malloc函数分配的空间并返回其指针。
在没有可用空间时,malloc函数返回NULL,strdup也将返回NULL,由调用者负责错误处理。
调用malloc函数得到的存储空间可以通过调用free函数释放以重用。
练习6-2 编写一个程序,读入一个C语言程序,并按字母表顺序分组打印变量名,每组内的前6个字符相同,其余字符不同。不考虑字符串和注释中的单词。将6作为一个可在命令行中设定的参数。
练习6-3 编写一个交叉引用程序,打印文档中所有单词的列表,并且每个单词还有一个出现过的行号列表。不考虑the、and等非实意单词。
练习6-4 编写一个程序,根据单词的出现频率降序打印输入中的各个不同的单词,并在每个单词前标上出现次数。
6.6 表查找
为了对结构的更多方面进行讨论,本节将要编写一个表查找(table-lookup)程序包的核心部分。这段代码很典型,可用于宏处理器或编译器的符号表管理。
例如,考虑#define语句。当遇到类似于#define IN 1的行,就需要把名字IN和替换文本1存入某个表中。之后,当名字IN出现在类似于state = IN的语句中时,就要从这个表中查出替换文本1来替换该名字。
以下两个函数用来处理名字和替换文本。install(s, t)将名字s和替换文本t记录到表中,s和t是字符串。lookup(s)在表中查找名字s,若找到则返回指向该位置的指针,否则返回NULL。
采用的算法是哈希搜索(hash search,也叫散列表搜索)——将输入的名字转换为一个小的非负整数(哈希值),将该整数(对数组长度取模后)作为一个指针数组的下标。数组的每个元素都指向一个链表的表头,链表中的每个块表示一个名字及其替换文本(即哈希值取模后相同的名字连接成一个链表)。如果没有名字散列到该值,则数组元素为NULL。这个数据结构叫做哈希表(hash table,也叫散列表),如下图所示:
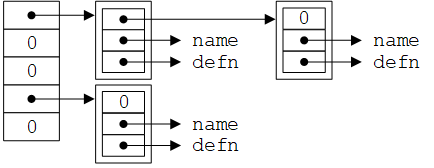
链表中的每个块都是一个结构,包含一个指向名字的指针、一个指向替换文本的指针以及一个指向该链表下一个块的指针。如果下一个块的指针为空则表明链表结束。
注:链表(linked list)是另一种数据结构,和数组一样属于线性表,但各个元素不是顺序存储的,而是通过指向下一个元素的指针连接起来。在逻辑上,链表如下图所示:

但在内存中的实际情况是:

散列函数hash在lookup和install函数中都被用到,它将字符串中的每个字符值与前面字符的混合组合(即31 * hashval)相加,并返回对数组长度取模的余数。这并不是最好的散列函数,但比较简短有效。无符号算术运算保证了散列值非负。
散列函数生成了查找数组hashtab的起始下标。如果该字符串可以被找到,则它一定位于该起始下标指向的链表的某个块中。具体查找过程由lookup函数实现,如果找到则返回指向该表项的指针,否则返回NULL。
lookup函数中的for循环是遍历链表的标准方法:
1
2
for (p = head; p != NULL; p = p->next)
...
install函数借助lookup判断待加入的名字是否已存在。如果已存在,则用新的替换文本取代旧的;否则创建一个新表项。如果没有足够空间创建新表项,则install函数返回NULL。
注:
- 本节给出了另一个ADT:散列表
- 数学模型:
nlist结构+指针数组,这种使用链表来存储散列值相同的元素的方法称为“溢出表法” - 操作:查找
lookup、插入install、删除undef(练习6-5)
- 数学模型:
- 指针表
hashtab被声明为static,即只能在lookup和install所在的源文件使用,这意味着该散列表只有一个实例,其他函数只能通过这两个函数来操作这个实例 install函数中else之前的两行就是标准的链表插入操作:p->next = head; head = p;,该操作将p指向的节点插入到表头,无论head是否为空指针都适用
练习6-5 编写函数undef,从lookup和install维护的散列表中删除一个名字及其定义。
练习6-6 基于本节介绍的函数,实现一个适用于C语言程序使用的#define处理器的简单版本(即无参数)。你会发现getch和ungetch函数非常有用。
6.7 类型定义(typedef)
C语言提供了一个称为typedef的功能,用来创建新的数据类型名。例如,声明
1
typedef int Length;
使得名字Length称为int的同义词。类型Length可用于声明、类型转换等,使用方式与int完全相同。例如:
1
2
Length len, maxlen;
Length *lengths[];
注:对于这种简单的情况,typedef的功能和#define相同,但名字在后、“替换文本”在前,并且最后要加分号;对于复杂的情况,typedef可以实现#define无法实现的功能,见下
类似地,声明
1
typedef char *String;
使得String成为char *的同义词,可用于声明和类型转换:
1
2
3
String p, lineptr[MAXLINES], alloc(int);
int strcmp(String, String);
p = (String) malloc(100);
注意,typedef声明的类型出现在变量名的位置,而不是紧跟在关键字typedef之后。
typedef常用于为结构类型定义别名,这样就可以省略关键字struct。例如:
1
2
3
4
5
6
typedef struct point {
int x;
int y;
} Point;
Point p;
其中结构标签point可省略。
必须强调的是,typedef并没有创建一个新类型,它只是为某个已存在的类型定义了一个别名。typedef声明也没有增加任何新的语义:通过这种方式声明的变量与通过普通方式声明的变量具有完全相同的属性。实际上,typedef类似于#define,但由于typedef是由编译器解释的,因此它的文本替换功能要超过预处理器的能力。例如:
1
typedef int (*PFI)(char *, char *);
定义了类型PFI是“指向具有两个char *参数、返回int的函数的指针”。它可以用在第5章的排序程序中:
1
PFI strcmp, numcmp;
除了表达方式简洁之外,使用typedef还有两个主要原因。第一个原因是它可以针对可移植性问题使程序参数化。如果typedef声明的数据类型与机器有关,那么当程序移植到其他机器上时,只需改变typedef类型定义就可以了。一个常见情况是使用typedef定义各种不同大小的整型。例如,在long类型占4字节的机器上定义
1
2
typedef int int32_t;
typedef long long int64_t;
而在long类型占8字节的机器上定义
1
2
typedef int int32_t;
typedef long int64_t;
这样在程序中可以分别使用int32_t和int64_t表示32位和64位整数,不需要考虑实际机器的整数大小。标准库<stdint.h>定义了这些整数类型。另一个例子是<stddef.h>中的size_t和ptrdiff_t。
typedef的第二个作用是为程序提供更好的说明性——PFI显然比声明复杂的函数指针更容易让人理解。
6.8 联合
联合(union)是可以(在不同时刻)保存不同类型和长度的对象的变量,编译器负责跟踪对象的长度和对齐要求。联合提供了一种在同一块存储区域中操作不同类型数据的方式。
下面的例子可能在编译器的符号表管理程序中找到。假设一个常量可能是int、float或字符指针(从编译原理的角度,整型常量、浮点常量和字符串常量都是终结符,并且有一个对应类型的值)。(在对源程序进行词法分析的过程中)一个特定常量的值必须保存在适当类型的变量中。然而,如果不同类型的值能够占据相同大小的存储空间、保存在同一个地方的话,对于符号表管理程序将很方便。这就是联合的目的——一个变量可以合法地保存多种类型中的任何一种。其语法类似于结构:
1
2
3
4
5
union constval {
int ival;
float fval;
char *sval;
} u;
变量u必须足够大,以保存这三种类型中最大的一种。这些类型中的任何一种都可以赋值给u(对应的成员)并在表达式中使用,但必须保证是一致的:读取的类型必须是最近一次存入的类型。程序员负责跟踪当前保存在联合中的类型。如果保存的类型与读取的不一致,其结果取决于具体的实现。
语法上,可以通过联合名.成员或联合指针->成员访问联合中的成员,与结构相同。如果用变量utype跟踪保存在u中的当前类型,则可以像下面这样使用联合:
1
2
3
4
5
6
7
8
if (utype == INT)
printf("%d\n", u.ival);
else if (utype == FLOAT)
printf("%f\n", u.fval);
else if (utype == STRING)
printf("%s\n", u.sval);
else
printf("bad type %d in utype\n", utype);
联合可以在结构和数组中使用,反之亦然。访问结构中的联合成员(或反之)的表示法与嵌套结构相同。例如,假设有以下结构数组定义(编译器表管理程序中的符号表):
1
2
3
4
5
6
7
8
9
10
struct {
char *name; /* 常量名 */
int flags; /* 限定符 */
int utype; /* 类型 */
union {
int ival;
float fval;
char *sval;
} u; /* 常量值 */
} symtab[NSYM];
则可通过symtab[i].u.ival引用成员ival,通过*symtab[i].u.sval或symtab[i].u.sval[0]引用字符串sval的第一个字符。
实际上,联合就是一个结构,但它的所有成员相对于基地址的偏移量都为0,次结构要大到足够容纳最“宽”的成员。对联合允许的操作与结构相同:作为一个整体单元进行赋值和拷贝、取地址以及访问成员。
联合只能使用第一个成员类型的值进行初始化。
6.9 位字段
在存储空间很宝贵的情况下,有可能需要将多个对象保存在一个机器字中。一种常见用法是类似于编译器符号表中的单个二进制位标志集合。来自外部的数据格式(如硬件设备接口)也经常需要获取字的一部分。
考虑编译器中管理符号表的功能。程序中的每个标识符都有与之相关的特定信息,例如它是否为关键字、是否是外部的和(或)静态的,等等。编码这些信息最紧凑的方式是使用一个char或int中的标志位集合。
通常采用的方式是定义一组与相关二进制位对应的“掩码”(mask),例如:
1
2
3
#define KEYWORD 01 /* 001 */
#define EXTERNAL 02 /* 010 */
#define STATIC 04 /* 100 */
或
1
enum { KEYWORD = 01, EXTERNAL = 02, STATIC = 04 };
这些数字必须是2的幂。这样,访问这些位就变成了用第2章中描述的移位、掩码及补码运算进行简单的位操作。
例如:flags |= EXTERNAL | STATIC;将flags中的EXTERNAL和STATIC位置为1;flags &= ~(EXTERNAL | STATIC);将它们置为0;当这两位都为0时,if ((flags & (EXTERNAL | STATIC)) == 0)为真。
C语言还提供了直接定义和访问一个字中的位字段的能力,而不需要通过按位运算符。位字段(bit-field),或简称字段(field),是“字”中相邻位的集合。“字”(word)是单个存储单元,与具体的实现有关(可理解为字节)。例如,上述符号表的几个#define语句可用下列三个位字段的定义来代替:
1
2
3
4
5
struct {
unsigned int is_keyword : 1;
unsigned int is_extern : 1;
unsigned int is_static : 1;
} flags;
这里定义了一个变量flags,包含三个一位的字段。冒号后的数字表示字段的宽度(单位是二进制位)。
单个字段的引用方式与其他结构成员相同,例如flags.is_keyword。字段的行为类似于小整数,可以像其他整数一样参与算术表达式。因此,上面的例子可用更自然的方式写成:flags.is_extern = flags.is_static = 1;将对应的位置1;flags.is_extern = flags.is_static = 0;将对应的位置0;if (flags.is_extern == 0 && flags.is_static == 0)对相应的位进行测试。
字段的所有属性几乎都同具体的实现有关。字段能否覆盖字边界由具体的实现定义。字段可以不命名,无名字段(只有一个冒号和宽度)起填充作用。特殊宽度0可用来强制在下一个字边界上对齐。
有些机器上字段是从左到右分配的,有些机器上是从右到左。这意味着,尽管字段对于维护内部定义的数据结构很有用,但在选择外部定义数据的情况下,必须仔细考虑哪端优先的问题。依赖于这些因素的程序是不可移植的。字段只能声明为整型,为了方便移植,最好显式地指定signed或unsigned。字段不是数组,并且没有地址,因此不能使用&运算符。