《Python基础教程》笔记 第1章 基础知识
在本章中,你将学习如何借助计算机能够听懂的语言——Python来控制计算机。Python的官方网站是 https://www.python.org/,官方文档:https://docs.python.org/3/。
首先,需要安装Python,或者验证是否已经安装。如果你使用的是macOS或Linux/UNIX,那么系统已经默认安装了Python。打开终端,输入python3并按回车键。你应该看到欢迎消息和提示符>>>:
1
2
3
4
5
$ python3
Python 3.6.9 (default, Mar 10 2023, 16:46:00)
[GCC 8.4.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>>
对于Windows,需要手动安装Python:
- 打开浏览器,访问https://www.python.org/downloads/windows/。
- 找到最新版本,点击 “Download Windows installer (64-bit)” 链接。
- 运行安装程序,使用默认设置安装即可。
安装完成后,找到开始菜单 → Python → IDLE,打开Python自带的集成开发环境(Integrated Development and Learning Environment, IDLE):
1.1 交互式解释器
当你启动Python时,会看到类似于下面的提示符:
1
2
3
4
Python 3.6.9 (default, Mar 10 2023, 16:46:00)
[GCC 8.4.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>>
这是Python的交互式解释器(interactive interpreter)。尝试输入:
1
>>> print("Hello, world!")
当按下回车键后,会得到下面的输出:
1
2
Hello, world!
>>>
注:在Python中,每行不需要以分号结尾。
>>>是提示符(prompt),可以在后面输入内容,例如print("Hello, world!")。如果按下回车,Python解释器将执行输入的语句(打印字符串 “Hello, world!” ),然后再次显示提示符。
如果输入完全不同的内容呢?尝试:
1
2
3
>>> The Spanish Inquisition
SyntaxError: invalid syntax
>>>
显然,解释器不理解输入的内容。如果运行的不是IDLE,而是Linux命令行解释器,错误消息可能稍有不同:
1
2
3
4
5
6
>>> The Spanish Inquisition
File "<stdin>", line 1
The Spanish Inquisition
^^^^^^^
SyntaxError: invalid syntax
>>>
1.2 算法是什么
在正式开始编程之前,首先解释一下什么是计算机编程。简单地说,就是告诉计算机要做什么。你需要用计算机能理解的语言给它提供一个算法。算法(algorithm)即对如何做某件事的详细描述。例如:
1
2
3
4
SPAM with SPAM, SPAM, Eggs, and SPAM: First, take some SPAM.
Then add some SPAM, SPAM, and eggs.
If a particularly spicy SPAM is desired, add some SPAM.
Cook until done -- Check every 10 minutes.
这个菜谱由一系列按顺序执行的指令组成。有些指令可以直接完成(“take some SPAM”),有些则需要考虑(“If a particularly spicy SPAM is desired”),还有些需要重复多次(“Check every 10 minutes”)。
菜谱由原料和指令组成,算法由对象、表达式和语句组成。在这个例子中,SPAM和鸡蛋是原料,“添加SPAM”和“烹饪指定的时间”等是指令。下面从一些非常简单的Python“原料”开始,看看可以用它们做些什么。
1.3 数字和表达式
交互式Python解释器可以用作功能强大的计算器。尝试:
1
2
3
4
5
6
7
8
>>> 2 + 2
4
>>> 53672 + 235253
288925
>>> 1 + 2 * 3
7
>>> (1 + 2) * 3
9
所有常见算术运算都和预期的一致。除法运算的结果为小数,即浮点数(floating-point numbers)。
1
2
3
4
>>> 1 / 2
0.5
>>> 1 / 1
1.0
如果希望丢弃小数部分,即执行整数除法(向下取整),可以使用//:
1
2
3
4
5
6
>>> 1 // 2
0
>>> 5 // 2
2
>>> 5.0 // 2.4
2.0
在旧版本的Python中,整数的普通除法/和这里的//一样。如果使用的是Python 2.x,可以通过添加以下语句来获得浮点数除法:
1
from __future__ import division
除了基本算术运算(加减乘除),还有一种与整数除法密切相关的运算:余数(remainder)/取模(modulus)运算符%。x % y是x除以y的余数,等价于x - (x // y) * y。
1
2
3
4
5
6
7
8
9
10
>>> 10 // 3
3
>>> 10 % 3
1
>>> 9 // 3
3
>>> 9 % 3
0
>>> 2.75 % 0.5
0.25
从最后一个例子中可以看出,取模运算符也可用于浮点数。这种运算甚至可用于负数,但可能有点难理解。
1
2
3
4
5
6
7
8
>>> 10 % 3
1
>>> 10 % -3
-2
>>> -10 % 3
2
>>> -10 % -3
-1
通过这些示例也许不能一眼看出取模运算的工作原理,但研究对应的整除运算有助于理解。
1
2
3
4
5
6
7
8
>>> 10 // 3
3
>>> 10 // -3
-4
>>> -10 // 3
-4
>>> -10 // -3
3
Python的整除运算始终是向下取整。例如,10 // -3等于-3.33…下取整,即-4,因此10 % -3等于10-(-3)*(-4)=-2。
注:Python的整除和取模运算符的舍入规则与C++和Java有差异,详见【Python】除法舍入问题。
最后一个运算符是乘方(exponentiation)/幂(power)运算符**:
1
2
3
4
5
6
>>> 2 ** 3
8
>>> -3 ** 2
-9
>>> (-3) ** 2
9
注意,幂运算符的优先级比负号高,因此-3**2等价于-(3**2)。
1.3.1 十六进制、八进制和二进制
十六进制、八进制和二进制数分别以0x、0o和0b开头:
1
2
3
4
5
6
>>> 0xAF
175
>>> 0o10
8
>>> 0b1011010010
722
1.4 变量
变量(variable)是表示(或引用)某个值的名字。例如,让名字x表示3:
1
>>> x = 3
这称为赋值(assignment)。我们将值3赋给变量x。换句话说,我们将变量x 绑定(bind)到值3。
注:
- 值并不是存储在变量中,而是存储在变量引用的计算机内存中。多个变量可以引用同一个值。
- 在Python中,变量没有类型,因此不需要声明。一个变量可以绑定到任意类型的对象。
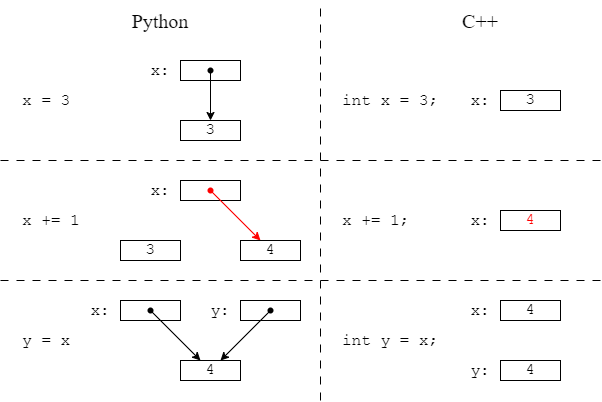
- 在Python中,一切皆对象,包括整数、字符串、列表、函数、类等。Python变量相当于C++的指针变量,赋值操作是浅拷贝,如下图所示。对于不可变类型(例如整数、字符串和元组),这种区别没有影响;而对于可变类型(例如列表和字典),这种区别影响很大。另见2.2.4节和4.2.4节。
给变量赋值后,就可以在表达式中使用它:
1
2
>>> x * 2
6
不同于其他一些语言,在Python中使用变量前必须给它赋值。
1
2
>>> y + 1
NameError: name 'y' is not defined
注意:在Python中,名字(即标识符(identifiers))只能由字母、数字和下划线构成,且不能以数字开头。因此Plan9是合法的变量名,而9Plan不是。
1.5 语句
表达式相当于菜谱的原料,而语句(statement)相当于指令。
实际上,前面已经介绍过两种语句:print语句和赋值语句。表达式是某个东西,而语句做某件事情。例如,2 * 2 是 4,而print(2 * 2) 打印 4。
1
2
3
4
>>> 2 * 2
4
>>> print(2 * 2)
4
在交互式解释器中执行时,这两段代码的结果没有任何区别,但这只是因为解释器总是将表达式的值打印出来。然而,在Python中并非都是这样。本章后面将介绍如何创建无需解释器就能运行的程序。将2 * 2这样的表达式放在程序中没有任何作用,而print(2 * 2)仍然会打印4。
注:print实际上是一个函数,前面说的print语句其实是函数调用。
涉及赋值时,语句和表达式的区别更明显。因为赋值语句不是表达式,没有可供解释器打印的值。
1
2
>>> x = 3
>>>
1.6 获取用户输入
下面看看有用的函数input()。该函数首先输出给定的提示信息(如果有),之后从输入读取一行,将其转换为字符串(删除结尾的换行符)并返回。如果遇到EOF,则引发EOFError。
1
2
3
>>> input("The meaning of life: ")
The meaning of life: 42
'42'
在这里,交互式解释器执行了第一行(input(...)),它打印字符串 “The meaning of life: ” 作为提示信息。之后输入42并按回车。input()的结果以字符串的形式在最后一行被自动打印出来。
下面是一个更有趣的例子,使用int()将字符串转换为整数:
1
2
3
4
5
6
>>> x = input("x: ")
x: 34
>>> y = input("y: ")
y: 42
>>> print(int(x) * int(y))
1428
注意:1.9节将介绍如何将程序存储在单独的文件中,让其他用户能够执行。
先睹为快:if语句
为了增添学习乐趣,这里提前介绍一下第5章才学习的内容:if语句。if语句用于在给定的条件为真时执行特定的操作(另一个语句)。一种条件是使用相等运算符==判断相等。
将条件放在if后面,用冒号与后面的语句隔开:
1
2
3
4
5
>>> if 1 == 2: print('One equals two')
...
>>> if 1 == 1: print('One equals one')
...
One equals one
注意,在交互式解释器中使用if语句时,需要按两次回车才能执行(原因将在第5章介绍)。
如果变量time是以分钟为单位的当前时间,可以用以下语句检查当前是不是整点:
1
if time % 60 == 0: print('On the hour!')
1.7 函数
1.3节使用了幂运算符(**)来计算幂。实际上,还可以使用函数(function) pow()。
1
2
3
4
>>> 2 ** 3
8
>>> pow(2, 3)
8
函数就像小型程序,可用来执行特定的操作。Python提供了很多像pow()这样的内置函数(built-in function),你也可以自己编写函数(将在后面介绍)。
注:内置函数的完整列表见Built-in Functions。
pow(2, 3)叫做调用(call)函数:你向它提供实参(argument)(这里是2和3),它返回(return)一个值。函数调用也是一种表达式,可以和运算符结合:
1
2
>>> 10 + pow(2, 3 * 5) / 3.0
10932.666666666666
注:如果忽略(或没有)返回值,函数调用也可用作语句(例如print())。
很多内置函数都可用于数值表达式。例如,abs()计算绝对值,round()将浮点数舍入为最接近的整数:
1
2
3
4
5
6
>>> abs(-10)
10
>>> 2 // 3
0
>>> round(2 / 3)
1
注意最后两个表达式的区别。整数除法始终向下取整,而round()是四舍五入。函数floor()将浮点数向下取整,但它不是内置函数,而是在模块中。
1.8 模块
模块(module)可视为扩展,可以将其导入到Python以扩展其功能。使用import命令导入模块。上一节提到的函数floor()在模块math中。
1
2
3
>>> import math
>>> math.floor(32.9)
32
使用import导入模块后,以module.function的形式使用模块中的函数。对于这个例子,也可以使用int()将数字转换为整数:
1
2
>>> int(32.9)
32
注意:还有一些类似的函数可用于类型转换(例如str()和float())。实际上,它们并不是真正的函数,而是类。
注:int()和floor()的区别:int()是向零取整,而floor()是向下取整;int()的参数可以是字符串,而floor()的参数必须是数字。
1
2
3
4
5
6
7
8
>>> int(-2.5)
-2
>>> math.floor(-2.5)
-3
>>> int('123')
123
>>> math.floor('123')
TypeError: must be real number, not str
math模块还包含其他有用的函数。例如,ceil()与floor()相反,返回大于等于给定值的最小整数(即向上取整):
1
2
3
4
>>> math.ceil(32.3)
33
>>> math.ceil(32)
32
如果确定不会从多个模块导入同名函数,可以使用import命令的变体,避免每次调用函数时都指定模块名:
1
2
3
>>> from math import sqrt
>>> sqrt(2)
1.4142135623730951
使用from module import function之后,可在调用函数时不指定模块前缀。
注:可以用变量来引用函数。执行赋值foo = math.sqrt之后,就可以使用foo来计算平方根,例如foo(4)返回2.0。
1.8.1 cmath和复数
函数sqrt()不能用于负数:
1
2
3
4
5
>>> from math import sqrt
>>> sqrt(-1)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: math domain error
负数的平方根是虚数(imaginary number),而由实部和虚部组成的数叫做复数(complex)。Python标准库提供了一个专门用于处理复数的模块cmath。
1
2
3
>>> import cmath
>>> cmath.sqrt(-1)
1j
1j是一个虚数。结尾的j表示虚数单位,即-1的平方根(在数学上表示为i)。
Python对复数提供了内置支持:
1
2
>>> (1 + 3j) * (9 + 4j)
(-3+31j)
1.8.2 回到__future__
通过“魔法”模块__future__,可以导入Python当前不支持,但未来将称为标准的特性。在1.3节已经见识过,后面也将经常遇到这个模块。
1.9 保存并执行程序
本节将介绍如何编写自己和他人都能运行的程序——脚本(script)。
首先,你需要一个文本编辑器,最好是专门用于编程的。如果你使用的是IDLE,可以通过菜单File → New File打开一个新的编辑窗口。先输入如下代码:
1
print("Hello, world!")
下面选择File → Save保存程序,并命名为hello.py(扩展名.py表示Python源文件,实际上就是纯文本文件)。
现在可以运行这个程序,选择菜单Run → Run Module,在解释器窗口中打印了 “Hello, world!” 。
接下来扩展上述脚本:
1
2
name = input("What is your name? ")
print("Hello, " + name + "!")
运行这个程序,将会看到提示信息 “What is your name?” 。输入你的名字(例如 “Gumby” )并按回车键,将会看到 “Hello, Gumby!” 。
强大的海龟绘图
turtle模块实现了海龟绘图(turtle graphics),能够让你绘制图形(而不是打印文本)。
海龟绘图的思想源自形如海龟的机器人。这种机器人可以前进和后退,还可以向左或向右旋转一定的角度。另外,它携带一支笔,可以通过抬起或放下来控制它在移动时笔是否接触到纸张。turtle模块让你能够模拟这样的机器人。例如,可以这样绘制一个三角形:
可以使用penup()将笔抬起,pendown()将笔放下。其他命令可参考Python标准库文档的相关部分(https://docs.python.org/3/library/turtle.html)。
1.9.1 从命令提示符运行Python脚本
实际上,运行程序的方式有多种。假设Python可执行程序所在目录已经添加到PATH环境变量,并且脚本hello.py在当前目录下。在Windows命令提示符(CMD)中:
1
2
C:\>python hello.py
Hello, world!
在UNIX shell中:
1
2
$ python hello.py
Hello, world!
1.9.2 让脚本像普通程序一样
有时你希望能够像执行其他程序一样执行Python脚本,而不是显式地使用Python解释器。在UNIX中,有一种标准方法:让脚本的第一行以#!(称为pound bang或shebang)开始,后面跟着用于解释脚本的程序(在这里是Python)的绝对路径。将下面的代码作为脚本的第一行:
1
#!/usr/bin/env python3
并将脚本变成可执行的:
1
$ chmod a+x hello.py
现在可以这样运行它:
1
$ ./hello.py
如果愿意,可以对文件重命名并删除.py后缀,使其看起来更像普通程序。
1.9.3 注释
在Python中,井号(#)比较特殊:井号后面到行尾的所有内容都会被忽略。例如:
1
2
# Print the circumference of the circle:
print(2 * pi * radius)
第一行是注释(comment)。注释让程序更容易理解——无论对其他人还是你自己。
确保注释说的都是重要的事情,而不要重复代码中显而易见的信息。例如,下面示例中的注释就是多余的:
1
2
# Get the user's name:
user_name = input("What is your name?")
在任何情况下,都应确保即使没有注释,代码本身也是可读(易于理解)的。幸运的是,Python是一种能够编写可读程序的优秀语言。
1.10 字符串
在本章的第一个程序中,"Hello, world!"是一个字符串(string)。字符串的主要用途是表示一段文本,例如感叹句 “Hello, world!” 。
1.10.1 单引号字符串以及对引号转义
和数字一样,字符串也是值。
1
2
>>> "Hello, world!"
'Hello, world!'
Python在打印字符串时使用的是单引号,而我们使用的是双引号。其实没有任何差别。
1
2
>>> 'Hello, world!'
'Hello, world!'
所以为什么支持两种方式?因为当字符串包含单引号或双引号时,这可能会有用。
1
2
3
4
>>> "Let's go!"
"Let's go!"
>>> '"Hello, world!" she said'
'"Hello, world!" she said'
单引号字符串不能包含单引号,否则解释器将报错:
1
2
>>> 'Let's go!'
SyntaxError: invalid syntax
在这里,字符串是'Let',Python不知道如何处理后面的s go!'。
另一种方法是使用反斜杠()对引号进行转义,例如:
1
2
3
4
5
6
>>> 'Let\'s go!'
"Let's go!"
>>> "\"Hello, world!\" she said"
'"Hello, world!" she said'
>>> 'Let\'s say "Hello, world!"'
'Let\'s say "Hello, world!"'
1.10.2 拼接字符串
继续上面的例子,另一种表示该字符串的方式:
1
2
>>> "Let's say " '"Hello, world!"'
'Let\'s say "Hello, world!"'
依次写两个字符串,Python会自动将它们拼接起来。
注意,这种机制只能用于字符串常量。拼接(concatenate)字符串的通用方法是运算符+:
1
2
3
4
5
6
>>> "Hello, " + "world!"
'Hello, world!'
>>> x = "Hello, "
>>> y = "world!"
>>> x + y
'Hello, world!'
1.10.3 字符串表示、str和repr
Python打印值时,保留其在代码中的样子,而不是你希望用户看到的样子。但如果使用print(),结果将不同。
1
2
3
4
>>> "Hello, world!"
'Hello, world!'
>>> print("Hello, world!")
Hello, world!
如果有换行符\n,差别将更明显。
1
2
3
4
5
>>> "Hello,\nworld!"
'Hello,\nworld!'
>>> print("Hello,\nworld!")
Hello,
world!
Python有两种不同的机制将值转换为字符串:str()和repr()。使用str(),能够以合理的方式将值转换为用户能够理解的字符串;而使用repr(),通常将值表示为合法的Python表达式。
注:实际上,str是一个类,而repr是一个函数。
1
2
3
4
5
>>> print(repr("Hello,\nworld!"))
'Hello,\nworld!'
>>> print(str("Hello,\nworld!"))
Hello,
world!
具体来说,str("Hello,\nworld!")就是字符串本身(共13个字符,换行符\n是一个字符);而repr("Hello,\nworld!")包含了两端的单引号,并将换行符表示为\和n两个字符(共16个字符)。

1.10.4 长字符串、原始字符串和字节
长字符串
长字符串(long string)可以跨越多行,使用三个引号而不是普通引号。
1
2
3
print('''This is a very long string. It continues here.
And it's not over yet. "Hello, world!"
Still here.''')
也可以使用三个双引号,例如"""like this"""。长字符串可以包含单引号和双引号,而无需转义。
注:普通字符串也可以跨行。如果一行的最后一个字符是反斜杠,那么换行符本身将被忽略。例如:
1
2
3
4
5
6
>>> print("Hello, \
world!")
Hello, world!
>>> 1 + 2 + \
4 + 5
12
原始字符串
原始字符串(raw string)对于反斜杠不会特殊处理,因此在有些情况下很有用(例如编写正则表达式,详见第10章)。
例如,表示Windows路径时,可能需要使用大量的反斜杠。
1
2
3
4
>>> print('C:\\nowhere')
C:\nowhere
>>> print('C:\\Program Files\\fnord\\foo\\bar\\baz\\frozz\\bozz')
C:\Program Files\fnord\foo\bar\baz\frozz\bozz
在这种情况下,原始字符串可以派上用场。原始字符串不会把反斜杠当作特殊字符,而是让每个字符都保持原样。
1
2
3
4
>>> print(r'C:\nowhere')
C:\nowhere
>>> print(r'C:\Program Files\fnord\foo\bar\baz\frozz\bozz')
C:\Program Files\fnord\foo\bar\baz\frozz\bozz
原始字符串用前缀r表示。看起来可以在原始字符串中包含任何字符,这基本是正确的,但有两个例外。引号仍然需要转义,但反斜杠也将包含在最终的字符串中。
1
2
3
4
>>> print(r'Let\'s go!')
Let\'s go!
>>> print(r'Let's go!')
SyntaxError: invalid syntax. Perhaps you forgot a comma?
另外,原始字符串不能以单个反斜杠结尾,除非对其进行转义(但用于转义的反斜杠也会成为字符串的一部分)。
1
2
3
4
>>> print(r"This is illegal\")
SyntaxError: unterminated string literal (detected at line 1)
>>> print(r"This is legal\\")
This is legal\\
如果希望原始字符串的最后一个字符是反斜杠(例如Windows路径的结尾),则必须将反斜杠单独作为一个字符串。例如:
1
2
>>> print(r'C:\Program Files\foo\bar' '\\')
C:\Program Files\foo\bar\
原始字符串可以使用单引号、双引号或者三引号。
Unicode、bytes和bytearray
Python字符串使用Unicode编码来表示文本。
每个Unicode字符表示为一个码点(code point),在Unicode标准中就是一个数字。这让你能够表示超过12万个字符。指定Unicode字符的通用机制:使用16位或32位十六进制字面值(分别加上\u或\U前缀),或者使用Unicode名称(\N{name})。
1
2
3
4
5
6
>>> "\u00C6"
'Æ'
>>> "\U0001F60A"
'😊'
>>> "This is a cat: \N{Cat}"
'This is a cat: 🐈'
Unicode码点和名称的完整列表可以参考 https://symbl.cc/en/unicode/table/ 。
Unicode带来的主要挑战是编码(encoding)问题。在内存和磁盘中,所有对象都表示为一系列二进制数字(0和1),这些数字8个为一组,即字节(byte),字符串也不例外。Python提供了两种表示二进制数据的类型:不可变的bytes和可变的bytearray。可以使用前缀b创建bytes对象:
1
2
>>> b'Hello, world!'
b'Hello, world!'
Python的bytes字面值只支持ASCII标准的128个字符,而剩余的128个值必须使用\x转义序列,例如\xf0表示ASCII码为十六进制0xf0(即240)的字符。
一个字节只能表示28=256个不同的值,远少于Unicode标准的要求。这意味着绝大多数Unicode字符无法用单个字节表示。一种巧妙的替代方法是使用变长编码:ASCII字符仍然使用单字节编码,以便与旧系统兼容;不在这个范围内的字符使用多字节编码。这种编码方式叫做UTF(Unicode Transformation Format),常见的有UTF-8、UTF-16和UTF-32。
可以使用encode()将字符串(按照指定的编码规则)编码为bytes:
1
2
3
4
5
6
>>> 'Hællå, wørld!'.encode('UTF-8')
b'H\xc3\xa6ll\xc3\xa5, w\xc3\xb8rld!'
>>> 'Hællå, wørld!'.encode('ASCII')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeEncodeError: 'ascii' codec can't encode character '\xe6' in position 1: ordinal not in range(128)
可以看出,在UTF-8编码中,字符æ被编码为两个字节\xc3\xa6,而ASCII无法编码该字符。
几乎在所有情况下,最好都使用UTF-8,这也是Python的默认编码。
也可以使用decode()将bytes解码为字符串:
1
2
>>> b'H\xc3\xa6ll\xc3\xa5, w\xc3\xb8rld!'.decode('UTF-8')
'Hællå, wørld!'
bytes对象本身并不知道编码,因此你必须负责跟踪这一点。如果解码时使用了错误的编码,将出现错误消息或得到乱码。例如:
1
2
3
4
5
>>> b = b'\xba\xf1\xa6\xe2\xa5\x76\xb5\xdc\xa9\x69'
>>> b.decode('big5')
'綠色史萊姆'
>>> b.decode('gbk', errors='replace')
'厚︹�v弟﹊'
如果想更详细地了解Python中的Unicode,可参考官方文档Unicode HOWTO: https://docs.python.org/3/howto/unicode.html 。
最后,Python还提供了bytearray,它是bytes的可变版,可以修改其中的字符。
1
2
3
4
>>> x = bytearray(b"Hello!")
>>> x[1] = ord(b"u")
>>> x
bytearray(b'Hullo!')